
The conversation about designing and evaluating Retrieval-Augmented Generation (RAG) systems is a long, multi-faceted discussion. Even when we look at retrieval on its own, developers selectively employ many techniques, such as query decomposition, re-writing, building soft filters, and more, to increase the accuracy of their RAG pipelines. While the techniques vary from system to system, an embedding model is typically at the heart of every retrieval pipeline in RAGs.
Embeddings, specifically dense embeddings, are used to express the semantic structure of text. Because all retrievers in RAGs have a critical must solve for the semantic understanding of the raw text, it’s paramount to have a systematic evaluation process to choose the right one.
General retrieval benchmarks, such as Massive Text Embedding Benchmark (MTEB) and Benchmarking-IR (BEIR), are often used as proxies for evaluating retrievers. The type of data you encounter in production plays a crucial role in determining the relevance of academic benchmarks. Additionally, the choice of metrics should be use-case-dependent when evaluating enterprise RAGs.
In this post, you’ll learn:
- What some of the most popular academic benchmarks entail and how best to leverage them as a proxy.
- The recommended metrics for evaluating retrievers.
If you are new to the role of retrievers in RAG, review this post about building enterprise RAG apps with the NVIDIA Retrieval QA Embedding model.
Effects of data blending on benchmarks
The best data to evaluate retrieval is your own. Ideally, you build a clean and labeled evaluation dataset that best reflects what you see in production. It’s best to build a custom benchmark for evaluating the quality of different retrievers, which can vary greatly depending on the domain and task.
Without well-labeled evaluation data, many turn to two popular benchmarks: MTEB and BEIR, as proxies. However, a crucial question is:
“Do the datasets in these benchmarks truly represent your workload?”
Answering this is vital, as evaluating performance on irrelevant cases can lead to false confidence in your RAG pipelines.
What are the popular benchmarks?
RAG systems are often deployed as a part of chatbots. The retriever’s task is to find relevant passages based on a user’s query to provide a context for the LLM. The BEIR benchmark has become the go-to standard for evaluating embeddings in information retrieval since its inception in 2021.
MTEB, hosted by Hugging Face, incorporates BEIR and a variety of other datasets for evaluating embedding models across different tasks, such as classification, clustering, retrieval, ranking, and more.
Retrieval benchmark
BEIR has 17 benchmark datasets spanning diverse text retrieval tasks and domains, while MTEB consists of 58 datasets across 112 languages for eight different embedding tasks. Each dataset caters to measuring the performance of various applications of an embedding model—retrieval, clustering, and summarization. Given the focus on RAG, you must consider which performance metrics and datasets are most useful for evaluating a Question-Answering (QA) retrieval solution aligned with your use case.
Several datasets address the task of finding a relevant passage based on an input query:
- HotpotQA and NaturalQuestions (NQ) assess general QA.
- FiQA concentrates on QA related to financial data.
- NFCorpus consists of QA pairs in the medical domain.
HotpotQA: General Question-Passage pairs
| Input: Were Scott Derrickson and Ed Wood of the same nationality? Target: Scott Derrickson (born July 16, 1966) is an American director, screenwriter and producer. He lives in Los Angeles, California. He is best known for directing horror films such as “Sinister”, “The Exorcism of Emily Rose”, and “Deliver Us From Evil”, as well as the 2016 Marvel Cinematic Universe installment, “Doctor Strange.” |
NQ: General Question-Passage pairs
| Input: What is non-controlling interest on the balance sheet? Target: In accounting, minority interest (or non-controlling interest) is the portion of a subsidiary corporation’s stock that is not owned by the parent corporation. The magnitude of the minority interest in the subsidiary company is generally less than 50% of outstanding shares, or the corporation would generally cease to be a subsidiary of the parent.[1] |
However, other datasets like Quora and Arguana in BEIR focus on tasks beyond QA.
Quora: Find duplicated questions
| Input: Which question should I ask on Quora? Target: What are good questions to ask on Quora? |
Arguana: Find counterfactual passages
| Input: It is immoral to kill animals As evolved human beings it is our moral duty to inflict as little pain as possible for our survival. So if we do not need to inflict pain to animals in order to survive, we should not do it. Farm animals such as chickens, pigs, sheep, and cows are sentient living beings like us – they are our evolutionary cousins and like us they can feel pleasure and pain. The 18th century utilitarian philosopher Jeremy Bentham even believed that animal suffering was just as serious as human suffering and likened the idea of human superiority to racism. It is wrong to farm and kill these animals for food when we do not need to do so. […] Target: There is a great moral difference between humans and animals. Unlike animals, humans are capable of rational thought and can alter the world around them. Other creatures were put on this earth for mankind to use, and that includes eating meat. For all these reasons we say that men and women have rights and that animals don’t. |
These examples underscore the importance of meticulously reviewing benchmark data and selecting problems that closely align with your use case. When using the BEIR benchmark to guide your decisions, consider the following:
- Are all the datasets that makeup BEIR relevant to your RAG application?
- Does the distribution of samples from different benchmarks accurately represent the questions your users typically ask?
Our general recommendation is to evaluate the retriever on a relevant subset, such as HotpotQA, NQ, and FiQA, as they are representative of a generic QA application. However, if your RAG pipeline has unique considerations, we recommend adding representative data from the preceding sources into your evaluation blend.
How to select the best model for QA benchmarks
Let’s drill down on selecting or curating benchmarks that align best with your evaluation.
Domain and quality
When examining the different BEIR datasets, you might notice that some are domain-specific. If you want to build a RAG system for technical manual instructions, you might want to consider datasets from the same domain with similar questions that best represent your use case. An example of such a dataset is TechQA, a domain-adaptation dataset with actual questions posed by users on a technical forum. TechQA isn’t among the BEIR benchmark datasets, but it might be a good candidate with a similar domain to your IT/technical support use case. For example:
| Question tile: “Datacap on Citrix” Question text: “Hi All, Can we operate Datacap thin clients on Citrix?” Answer: “Remote users that access Datacap over a WAN can use Taskmaster Web-based \”thin clients\”, or FastDoc Capture operating in offline mode.” Context: “WAN LAN architecture deployment TECHNOTE (FAQ)\n\nQUESTION\n What are the best practices for deploying Datacap servers and clients on a wide area network (WAN)? ANSWER Remote users that access Datacap over a WAN can use Taskmaster Web-based “thin clients”, or FastDoc Capture operating in offline mode. Datacap thick clients (DotScan, DotEdit) and utilities (NENU, Fingerprint Maintenance Tool) require LAN communication speeds and low latency for responsive performance. Connect all Datacap Taskmaster Servers, Rulerunner Servers, Web Servers, file servers and databases to a single high performance LAN for best results. Network delays between Taskmaster Server, shared files and databases causes degraded performance of Job Monitor and data intensive operations. Some customers successfully operate Datacap thick clients in remote sites using Citrix or other remote access technology. IBM has not tested or sought certification with Citrix, and does not provide support for Citrix. If you deploy Datacap clients on Citrix and encounter issues, IBM may require you to reproduce the issues outside of Citrix as part of the investigation.Consult the IBM Redbooks titled “Implementing Imaging Solutions with IBM Production Imaging Edition and IBM Datacap Capture”, section 2.5, for deployment recommendations and diagrams. RELATED INFORMATION IBM Redbooks Production Imaging Edition [http://www.redbooks.ibm.com/abstracts/sg247969.html?Open]” |
Training data: in-domain compared to out-of-domain
Several BEIR benchmark datasets feature a split between training and testing data. Although including the training split into the retriever’s training dataset is fine, it complicates the comparison of model performance on the MTEB benchmark and its effectiveness on unseen, enterprise-specific data. When the training split is included, the model learns from the same distribution as the testing dataset, leading to inflated performance metrics on the testing dataset. The differentiation is commonly called in-domain compared to out-of-domain.
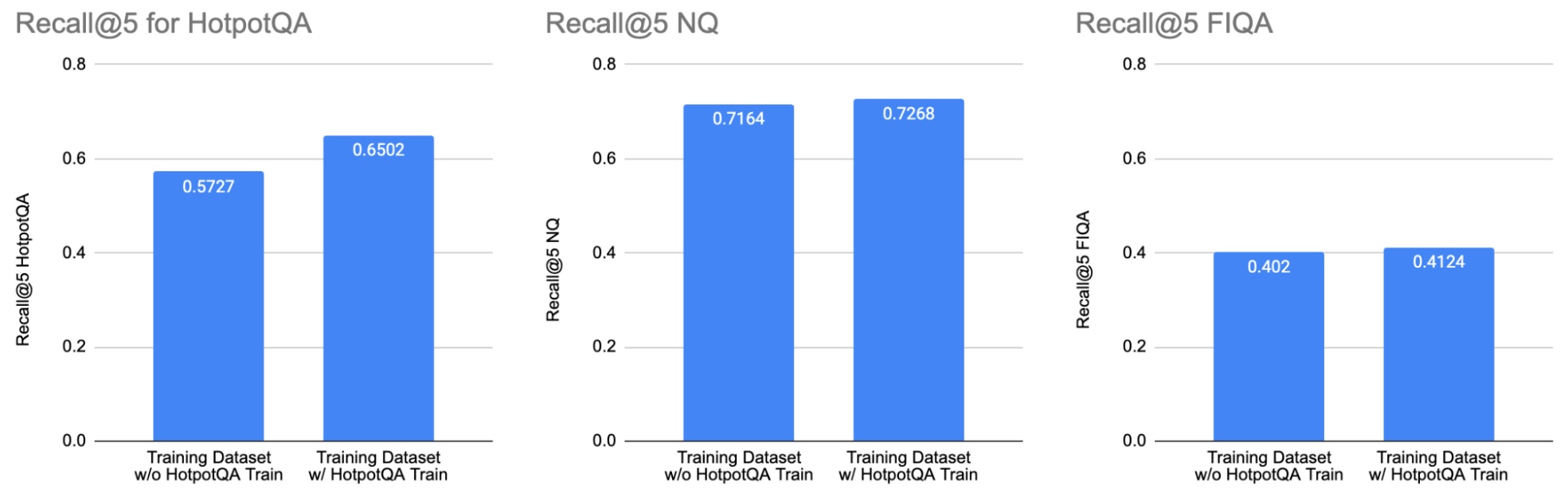
We ran the experiment by fine-tuning the e5_large_unsupervised model two times: once with a training dataset, which excluded the HotpotQA training split (left bars), and once with a training dataset, which included the HotpotQA training split (right bars). Including the HotpotQA training split improved performance on the HotpotQA testing dataset (left bar chart). However, it didn’t significantly change the performance on NQ (middle bar chart) and FIQA (right bar chart). This illustrates the importance of examining which datasets are used to train models when interpreting results on a public benchmark.
Many models were trained on a mix of MSMarco, NQ, and NLI including the training split from BEIR datasets. For example, the study Improving Text Embeddings with Large Language Models provides details of the training dataset in the appendix. In the paper, Table 1 illustrates the difference in performance between synthetic+MSMarco and synthetic+Full configurations. In general, human-generated, or annotated data provides better quality assessment than a purely synthetic dataset. This correlation also holds true for the size of the dataset.
In summary, the general recommendation is to look for human-generated and annotated datasets that align with your use case and have a lot of samples.
License
Note that the following is just an interpretation and not legal advice—it’s advisable to consult your legal team for any consideration.
Another important aspect to consider is the license and terms of use associated with pretrained models. While many pretrained models are shared under MIT or Apache 2.0 licenses on the HuggingFace platform, reviewing the datasets used for pretraining is essential as some datasets might have licenses that prohibit commercial applications. Consider using a pretrained model, which uses training data licensed for commercial use.
With the importance of data understood, we have one aspect of the evaluation covered. The other crucial aspect is the metrics that we use to gauge quality.
Evaluation metrics
There are primarily two types of metrics used in retrieval evaluation:
- Rank-Aware metrics: These metrics consider the order or rank of the retrieved documents. They’re useful in scenarios where it’s beneficial to have the most relevant results presented higher in the list, such as recommendation systems or search engines. Examples include Normalized Discounted Cumulative Gain (NDCG).
- Rank-Agnostic metrics: These metrics do not consider the order in which results are presented. They’re useful when the goal is to detect the presence of relevant items in a list, rather than their ranks.
Now let’s delve deeper into Recall and NDCG, two metrics commonly encountered in academic benchmarks and leaderboards.
Recall
A rank-agnostic metric recall measures the percentage of the relevant results retrieved:
\({\text{Recall} = \frac{\text{Number of Relevant Items Retrieved}}{\text{Total Number of Relevant Items}}}\)
Plainly put—if there are three relevant chunks for a given query, and only two show up in the top 5 retrieved chunks, the recall rate would be ⅔ = 0.66.
A popular variation that you’ll see in benchmarks is recall@K, which only considers the top K items returned by the system. However, if your system always returns a fixed K number of items, then recall@K. and recall are effectively the same metric.
In most information retrieval scenarios, recall is an excellent metric when the order of the retrieved candidates isn’t important. From a RAG perspective, if your chunks are small (300–500 tokens) and you are retrieving a few chunks, most LLMs don’t run into a lost in the middle problem for 1500–2500 token contexts.
In cases where a considerably long context is given to an LLM, its ability to extract relevant information varies based on the position of the information. Typically LLMs work best with information at the top and the bottom, and experience significant degradation if the information is “in the middle.” The order of the chunks doesn’t matter in a shorter context, as long as they’re all included.
Normalized discounted cumulative gain
Normalized discounted cumulative gain (NDCG) is a rank-aware metric that measures the relevance and order of the retrieved information.
- Cumulative gain tracks relevance where each item in a retrieved list is assigned relevance scores based on their usefulness in answering the query.
- A discount is applied based on position, where lower positions receive higher discounts, incentivizing better ranking.
- Normalization unifies the metric across queries when different numbers of relevant chunks are used.
The primary goal of retrieval in a RAG pipeline is to enable the LLM to perform Extractive Question-Answering. NDCG becomes relevant in cases where retrieved chunks are excessively long (exceed 4k tokens), or when retrieving a large number of chunks, leading to a scenario where lost in the middle in long context is plausible. Additionally, if your application exposes chunks as citations, you may find the order and relevance of the retrieved chunks important.
In many real-world applications, a context of up to 4K tokens is sufficient, and recall is the recommended metric because NDCG penalizes when the most relevant chunk isn’t ranked at the top. As long as it’s in the top K-retrieved results that can be shared in a reasonably sized context, the LLM should effectively leverage that information to formulate a response.
While recall and NDCG are very different approaches, they often exhibit high correlations. A retrieval model with a good recall score on your data will also likely have a good NDCG score.
Now let’s explore a retrieval benchmark, relevant to text-based QA, aligning with the recommendations so far.
Retrieval benchmark
The NVIDIA NeMo Retriever, a part of the NVIDIA NeMo framework, offers an information retrieval service designed to streamline the integration of enterprise-grade RAG into customized production AI applications securely and with ease. At its core lies the NVIDIA Retrieval QA Embedding model, trained on commercially viable, internally curated datasets.
In Figure 2, we showcase recall@5 scores on relevant subsets of MTEB/BEIR including NaturalQuestions, HotpotQA, and FiQA. These subsets serve as representative RAG workloads for QA tasks.
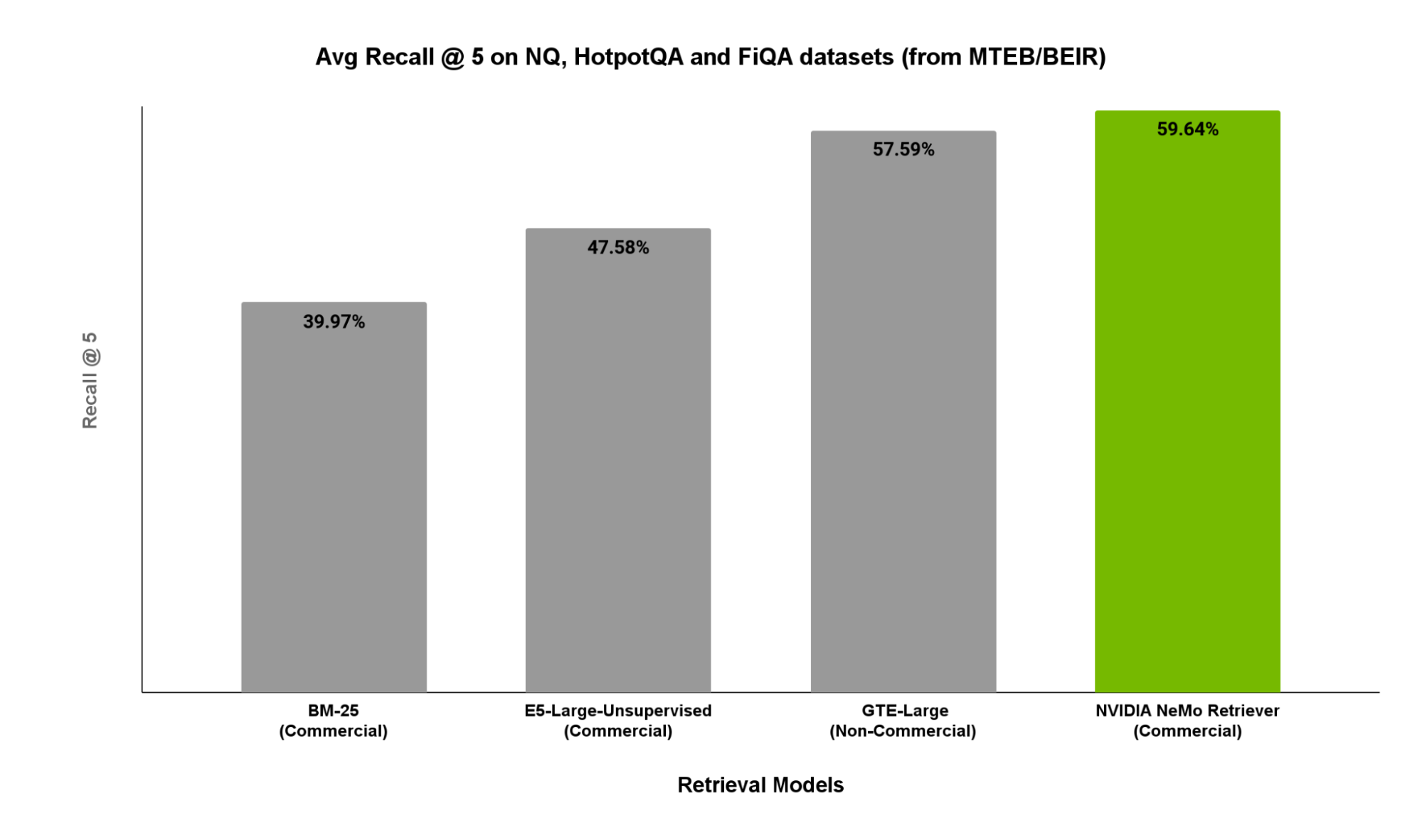
As indicated in Figure 2, NVIDIA Retrieval QA Embedding outperforms the other open-source options.
Conclusion
In the absence of evaluation data, it’s essential to pinpoint which parts of an academic benchmark suite can closely approximate your use case rather than averaging over potentially irrelevant subsets. Additionally, be cautious of relying solely on academic benchmarks, as parts of them may have been used to train the retriever in consideration, potentially leading to false confidence in its performance on your data.
To download the benchmark datasets used in this analysis, visit the BEIR GitHub repository and find the download links under the Available Datasets section. Try our embedding model using NVIDIA AI Foundation Endpoints and refer to documentation and code snippets.
Furthermore, recall@K and NDCG are two of the most relevant metrics, and you may choose a combination of both. If selecting only one, recall is simpler to interpret, and is more widely applicable.
Register to attend NVIDIA GTC to learn more about building generative AI applications with Retrieval-Augmented Generation from our panel of experts, and explore our DLI course to learn how to build AI chatbots with RAG.
