
This post was originally published on the RAPIDS AI blog.
TLDR: Learn how to use RAPIDS, HuggingFace, and Dask for high-performance NLP. See how to build end-to-end NLP pipelines in a fast and scalable way on GPUs. This covers feature engineering, deep learning inference, and post-inference processing.Introduction
Modern natural language processing (NLP) mixes modeling, feature engineering, and general text processing. Deep learning NLP models can provide fantastic performance for tasks like named-entity recognition (NER), sentiment classification, and text summarization. However, end-to-end workflow pipelines with these models often struggle with a performance at scale, especially when the pipelines involve extensive pre-and post-inference processing.
In our previous blog post, we covered how RAPIDS accelerates string processing and feature engineering. This post explains how to leverage RAPIDS for feature engineering and string processing, HuggingFace for deep learning inference, and Dask for scaling out for end-to-end acceleration on GPUs.
An NLP pipeline often involves the following steps:
- Pre-processing
- Tokenization
- Inference
- Post Inference Processing
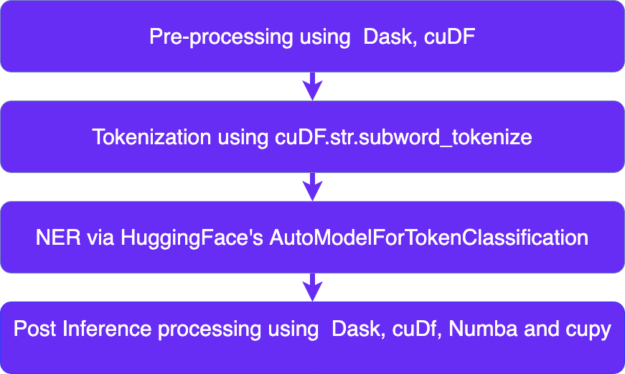
Pre-Processing:
Pre-Processing for NLP pipelines involves general data ingestion, filtration, and general reformatting. With the RAPIDS ecosystem, each piece of the workflow is accelerated on GPUs. Check out our recent blog where we showcased these capabilities in more detail.
Once we have pre-processed our data, we need to tokenize it so that the appropriate machine learning model can ingest it.
Subword Tokenization:
Tokenization is the process of breaking down the text into standard units that a machine can understand. It is a fundamental step across NLP methods from traditional like CountVectorizer to advanced deep learning methods like Transformers.
One approach to tokenization is breaking a sentence into words. For example, the sentence, “I love apples” can be broken down into, “I,” “love,” “apples”. But this delimiter based tokenization runs into problems like:
- Needing a large vocabulary as you will need to store all words in the dictionary.
- Uncertainty of combined words like “check-in,” i.e., what exactly constitutes a word, is often ambiguous.
- Some languages don’t segment by spaces.
To solve these problems, we use subword tokenization. Subword tokenization is a recent strategy from machine translation that breaks into subword units, strings of characters like “ing,” “any,” “place.” For example, the word “anyplace” can be broken down into “any” and “place,” so you don’t need an entry for each word in your vocabulary.
When BERT(Bidirectional Encoder Representations from Transformers) was released in 2018, it included a new subword algorithm called WordPiece. This tokenization is used to create input for NLP DL models like BERT, Electra, DistilBert, and more.
GPU Subword Tokenization
We first introduced the GPU BERT subword tokenizer in a previous blog as part of CLX for cybersecurity applications. Since then, we migrated the implementation into RAPIDS cuDF and exposed it as a string function, subword tokenization, making it easier to use in typical DataFrame workflows.
This tokenizer takes a series of strings and returns tokenized cupy arrays:
Example of using: cudf.str.subword_tokenize
Advantages of cuDF’s GPU subword Tokenizer:
The advantages of using cudf.str.subword_tokenize include:
- The tokenizer itself is up to 483x faster than HuggingFace’s Fast RUST tokenizer
BertTokeizerFast.batch_encode_plus. - Tokens are extracted and kept in GPU memory and then used in subsequent tensors, all without leaving GPUs and avoiding expensive CPU copies.
Once our inputs are tokenized using the subword tokenizer, they can be fed into NLP DL models like BERT for inference.
HuggingFace Overview:
HuggingFace provides access to several pre-trained transformer model architectures ( BERT, GPT-2, RoBERTa, XLM, DistilBert, XLNet…) for Natural Language Understanding (NLU) and Natural Language Generation (NLG) with over 32+ pre-trained models in 100+ languages.In our workflow, we used BERT and DISTIILBERT from HuggingFace to do named entity recognition.
Combining RAPIDS, HuggingFace, and Dask:
This section covers how we put RAPIDS, HuggingFace, and Dask together to achieve 5x better performance than the leading Apache Spark and OpenNLP for TPCx-BB query 27 equivalent pipeline at the 10TB scale factor with 136 V100 GPUs while using a near state of the art NER model. We expect to see even better results with A100 as A100’s BERT inference speed is up to 6x faster than V100’s.
In this workflow, we are given 26 Million synthetic reviews, and the task is to find the competitor company names in the product reviews for a given product. We then return the review id, product id, competitor company name, and the related sentence from the online review. To get a competitor’s name, we need to do NER on the reviews and find all the tokens in the review labeled as an organization.
Our previous implementation relied on spaCy for NER but, spaCy currently needs your inputs on CPU and thus was slow as it required a copy to CPU memory and back to GPU memory. With the new cudf.str.subword_tokenize, we can go from cudf.string.series to subword tensors without leaving the GPU unlocking many new SOTA language models.
In this task, we experimented with two of HuggingFace’s models for NER fine-tuned on CoNLL 2003(English) :
- Bert-base-model: This model gets an f1 of 91.95and achieves a speedup of 1.7 x over spaCy.
- Distil-bert-cased model: This model gets an f1of 89.6 (97% of the accuracy of BERT ) and achieves a speedup of 2.5x over spaCy
Research by Zhu, Mengdi et al. (2019) showcased that BERT-based model architectures achieve near state art performance, significantly improving the performance on existing public-NER toolkits like spaCy, NLTK, and StanfordNER.
For example, the bert-base model on average across datasets achieves a 13.63% better F1 than spaCy, so not only did we get faster but also reached near state of the art performance.
Check out the workflow code here.
Conclusion:
This workflow is just one example of leveraging GPUs to do end to end accelerating natural language processing. With cudf.str.subword_tokenizenow, most of the NLP tasks such as question answering, text-classification, summarization, translation, token classification are all within reach for an end to end acceleration leveraging RAPIDS and HuggingFace.Stay tuned for more examples and in, the meantime, try out RAPIDS in your NLP work on Google Colab or blazingsql notebooks, see our documentation docs page, and if you see something missing, we welcome feature requests on GitHub!
