
From monotonous highways to routine neighborhood trips, driving is often uneventful. As a result, much of the training data for autonomous vehicle (AV) development collected in the real world is heavily skewed toward simple scenarios.
This poses a challenge to deploying robust perception models. AVs must be thoroughly trained, tested, and validated to handle complex situations, which requires an immense amount of data covering such scenarios.
Simulation offers an alternative to finding and collecting such data in the real world—which would be incredibly time- and cost-intensive. And yet generating complicated, dynamic scenarios at scale is still a significant hurdle.
In a recently released paper, NVIDIA Research shows how a new neural radiance field (NeRF)-based method, known as EmerNeRF, uses self-supervised learning to accurately generate dynamic scenarios. By training through self-supervision, EmerNeRF not only outperforms other NeRF-based methods for dynamic objects, but also for static scenes. For more details, see EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision.



When running EmerNeRF alongside similar NeRFs, it increases dynamic scene reconstruction accuracy by 15% and static scene by 11%, additionally achieving a 12% improvement for novel view synthesis.
Addressing limitations in NeRF-based methods
NeRFs take a set of static images and reconstruct them into a realistic 3D scene. They make it possible to create high-fidelity simulations from driving logs for closed-loop deep neural network (DNN) training, testing, and validation.
However, current NeRF-based reconstruction methods struggle with dynamic objects and have proven difficult to scale. For example, while some approaches can generate both static and dynamic scenes, they require ground truth (GT) labels to do so. This means that each object in the driving logs must be accurately outlined and defined using autolabeling techniques or human annotators.
Other NeRF methods rely on additional models to achieve complete information about a scene, such as optical flow.
To address these limitations, EmerNeRF uses self-supervised learning to decompose a scene into static, dynamic, and flow fields. The model learns associations and structure from raw data rather than relying on human-labeled GT annotations. It then renders both the temporal and spatial aspects of a scene simultaneously, eliminating the need for an external model to fill in the gaps while improving accuracy.

As a result, while other models tend to produce over-smoothed renderings and dynamic objects with lower accuracy, EmerNeRF reconstructs high-fidelity background scenery as well as dynamic objects, all while preserving the fine details of a scene.
| Dynamic-32 Split | ||||||||
| Scene Reconstruction | Novel View Synthesis | |||||||
| Methods | Full Image | Dynamic Only | Full Image | Dynamic Only | ||||
| PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | PSNR↑ | SSIM↑ | DPSNR↑ | SSIM↑ | |
| D2 NeRF | 24.35 | 0.645 | 21.78 | 0.504 | 24.17 | 0.642 | 21.44 | 0.494 |
| HyperNeRF | 25.17 | 0.688 | 22.93 | 0.569 | 24.71 | 0.682 | 22.43 | 0.554 |
| EmerNeRF | 28.87 | 0.814 | 26.19 | 0.736 | 27.62 | 0.792 | 24.18 | 0.67 |
| Static-32 Split | ||
| Methods | Static Scene Reconstruction | |
| PSNR↑ | SSIM↑ | |
| iNGP | 24.46 | 0.694 |
| StreetSurf | 26.15 | 0.753 |
| EmerNeRF | 29.08 | 0.803 |
The EmerNeRF approach
Using self-supervised learning, rather than human annotation or external models, enables EmerNeRF to bypass challenges previous methods have encountered.
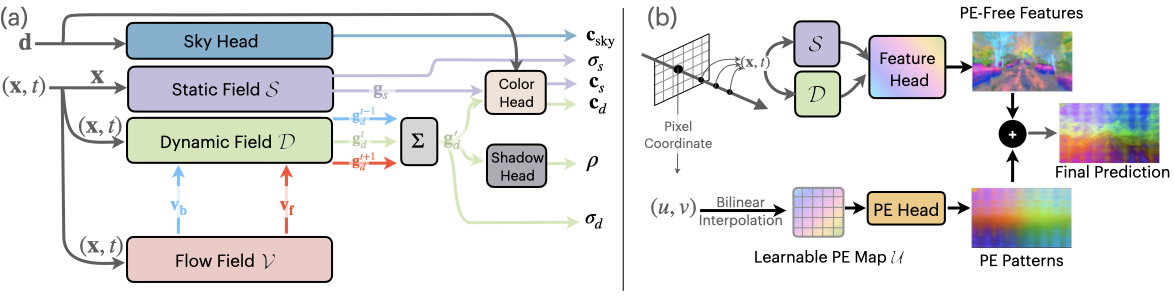
EmerNeRF is designed to break down a scene into dynamic and static elements. As it decomposes a scene, EmerNeRF also estimates a flow field from dynamic objects, such as cars and pedestrians, and uses this field to further improve reconstruction quality by aggregating features across time. Other approaches use external models to provide such optical flow data, which can often lead to inaccuracies.
By combining the static, dynamic, and flow fields all at once, EmerNeRF can represent highly dynamic scenes self-sufficiently, which improves accuracy and enables scaling to general data sources.
Adding semantic understanding with foundation models
EmerNeRF’s semantic understanding of a scene is further strengthened using foundation models for additional supervision. Foundation models have a broad knowledge of objects (specific types of vehicles or animals, for example). EmerNeRF leverages vision transformer (ViT) models such as DINO and DINOv2 to incorporate semantic features into its scene reconstruction.
This enables EmerNeRF to better predict objects in a scene, as well as perform downstream tasks such as autolabeling.

However, transformer-based foundation models pose a new challenge: semantic features can exhibit position-dependent noise, which can significantly limit downstream task performance.

To solve the noise issue, EmerNeRF uses positional embedding decomposition to recover a noise-free feature map. This unlocks the full, accurate representation of foundation model semantic features, as shown in Figure 5.
Evaluating EmerNeRF
As detailed in EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision, we evaluated the performance of EmerNeRF by curating a dataset of 120 unique scenarios, divided into 32 static, 32 dynamic, and 56 diverse scenes across challenging conditions such as high-speed and low-light conditions.
Each NeRF model was then evaluated on its ability to reconstruct scenes and synthesize novel views based on different subsets of the dataset.
Accordingly, we found EmerNeRF consistently and significantly outperformed other methods in both scene reconstruction and novel view synthesis, as shown in Table 1.
EmerNeRF also outperformed methods specifically designed for static scenes, suggesting that self-supervised decomposing of a scene into static and dynamic elements improves static reconstruction as well as dynamic.
Conclusion
AV simulation is only effective if it can accurately reproduce the real world. The need for fidelity increases—and becomes more challenging to achieve—as scenarios become more dynamic and complex.
EmerNeRF represents and reconstructs dynamic scenarios more accurately than previous methods, without requiring human supervision or external models. This enables reconstructing and modifying complicated driving data at scale, addressing current imbalances in AV training datasets.
We’re eager to investigate new capabilities that EmerNeRF unlocks, including end-to-end driving, autolabeling, and simulation.
To learn more, visit the EmerNeRF project page and read the paper, EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision.
