
QHack is an educational conference and the world’s largest quantum machine learning (QML) hackathon. This year at QHack 2023, 2,850 individuals from 105 different countries competed for 8 days to build the most innovative solutions for quantum computing applications using NVIDIA quantum technology.
The event was organized by Xanadu, with NVIDIA sponsoring the QHack 2023 NVIDIA Challenge. As part of the challenge, the top teams received access to the NVIDIA Quantum Platform, consisting of NVIDIA quantum software. This included the NVIDIA cuQuantum SDK and an early-access version of NVIDIA CUDA-Q, now available in open source. Both of these tools are optimized for the most powerful NVIDIA GPUs in the world—the same GPUs used to train ChatGPT.
QHack NVIDIA Challenge
In support of the NVIDIA Challenge, Cyxtera provided three DGX A100 Stations located around the globe, and Run:ai provided the user management and orchestration interface. The top 72 teams were given access to a single NVIDIA A100 80 GB GPU for 6 hours a day.
A few days into the event, teams were asked to submit their projects in progress for consideration for additional power-ups. At this time, 36 of these teams received private beta access to CUDA-Q. Additionally, the top 24 teams received a second NVIDIA A100 80 GB GPU.
Participants in the NVIDIA Challenge built 23 incredible projects, including, but not limited to:
- Quantum mixed reality
- QML for weather forecasting
- Genomic error correction and resequencing
- Machine learning (ML) to design better variational quantum algorithms
- Simulating the quantum dynamics of a space-time wormhole
These projects were graded on innovative ideas, scientific rigor, and capabilities with GPU-based simulators and workflows.
Winning projects underscore quantum computing use cases
The top three winning projects of the NVIDIA Challenge (detailed below) were awarded to the most rigorous scientific explorations, backed by good performance optimizations and presentations within the time allowed.
First place: Accelerating Noisy Algorithm Research with PennyLane-Lightning and NVIDIA cuQuantum SDK
Team MFC, consisting of Lion Frangoulis, Cristian Emiliano Godínez Ramírez, Emily Haworth, and Aaron Sander, won first place in the NVIDIA Challenge. Team MFC’s project, Accelerating Noisy Algorithm Research with PennyLane-Lightning and NVIDIA cuQuantum SDK addresses the computational complexity of noisy simulations with the PennyLane-Lightning-GPU plugin and the NVIDIA cuQuantum SDK.
This work is critically important for anyone interested in running algorithms on real quantum processing units (QPUs). By understanding noise sources present in the target system, developers may be able to design ansatzes to mitigate that noise, or even take advantage of it.
Team MFC’s work relies upon Trotter-Suzuki decomposition to approximate Hamiltonian evolution. The noise was modeled by injecting a depolarizing noise channel after each CNOT operation. Next, the team explored the effects of this noise on finding the ground state of the transverse field Heisenberg model using the Variational Quantum Eigensolver (VQE).
As one might expect, high levels of noise led to unstable solutions. But most interestingly, intermediate levels of noise can lead to a faster and more accurate convergence, compared to the noiseless run shown in Figure 1.
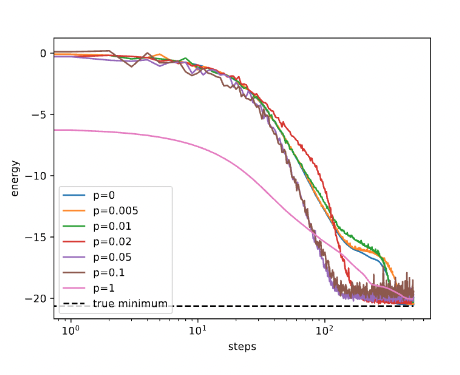
Team MFC took their process one step further and compared PennyLane Lightning Qubit (CPU-state vector simulator) with the PennyLane-Lightning-GPU (GPU-state vector simulator backed by cuQuantum) with the PennyLane default.mixed simulator backend by the native density matrix backend.
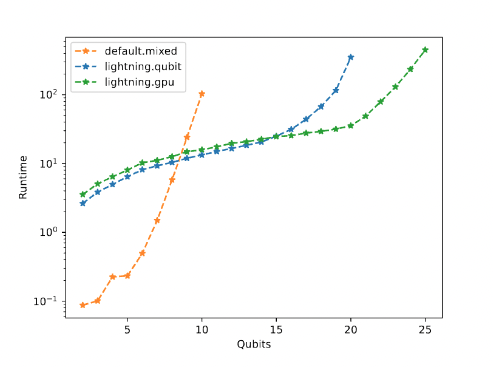
In an effort to make an apples-to-apples comparison, the team explored the effect of varying the number of trajectories on the fidelity of the stochastic noise algorithm. Their exploration shows that using roughly 200 trajectories is good enough. MFC then implemented benchmarks of the various backends of varying qubit counts. It became clear that PennyLane-Lightning-GPU is ideally tuned for larger simulations, outperforming the CPU simulator above 15 qubits.
This project demonstrates that the simulation of noisy quantum circuits is an invaluable tool for exploring hardware-efficient ansatzes for NISQ devices.
Second place: Quantum-Enhanced Support Vector Machines for Stellar Classification
Louis Chen, Henry Makhanov, and Felix Xu of Team Durchmusterung earned second place for their exploration of Quantum-Enhanced Support Vector Machines for Stellar Classification.
Stellar classification is a technique based on stellar spectroscopy data used to classify stars. Each spectral type relies on temperature, and luminosity and can be further divided into luminosity classes. Chemical compositions are also included. Due to the nature of the data, human classification is difficult to standardize, which is why ML models have been broadly employed for the task.
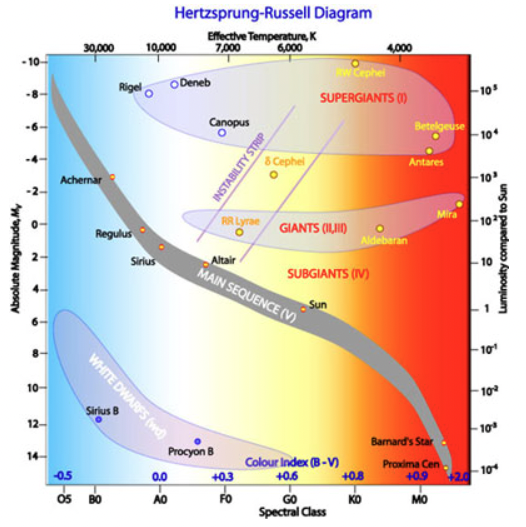
Team Durchmusterung explored how these state-of-the-art methods compare to a Quantum Support Vector Machine (QSVM). The Hertzsprung-Russell diagram is a common tool for studying stellar evolution and their classifications. See Figure 3 to get an idea of how complex, and sometimes subjective, this process can be when done by humans.
While quantum SVMs are promising, these methods still require classical preprocessing and postprocessing. In order to enable the quantum kernel methods for this ML model, feature engineering is required to reduce the dimensionality of the dataset and extract certain features that may negatively impact the computational load or model accuracy.
After the dataset had been prepared for quantum kernel learning, Durchmusterung explored its effectiveness compared to classical SVMs across multiple metrics like accuracy, sensitivity, and specificity. The goal of this approach is to determine if the quantum kernel can compete with the classical methods under investigation.
It is clear that the model has competitive accuracy, while consistently outperforming the specificity of the classical models investigated. The sensitivity of the quantum model was also slightly more robust than the classical model, suggesting that this method could be useful at scale.
Durchmusterung also explored the other classical models for benchmarking, such as k-nearest neighbors (KNN) and logistic regression. They found that while these methods succeed for binary classification achieving accuracies of roughly 86%, for multi-labeled classification the accuracy drops to roughly 78%. The quantum kernel model is able to achieve an accuracy of approximately 81%.
Overall, this exploration is a testament to the team’s hard work and the value the NVIDIA Quantum Platform provides to QML and quantum circuit simulation.
Third place: Reinforcement Learning Quantum Local Search
The third-place prize for the NVIDIA Challenge at QHack 2023 went to TaipeiQC for Reinforcement Learning Quantum Local Search. The two-person team, consisting of Chen-Yu Liu and Ya-Chi Lu, considered quantum local search (QLS), which leverages small QPUs to solve combinatorial optimization problems with some random starting point. They examined whether reinforcement learning (RL) can improve the initial selection process such that the quantum local search performs better.
Combinatorial optimization problems are very common. Routing optimization (such as the traveling salesman problem) and resource allocation (such as portfolio optimization) are great examples of combinatorial optimization problems. There are many approaches to attempting to solve these problems with quantum processors and QLS is one of those approaches.
TaipeiQC chose to explore 32, 64, and 128 variable combinatorial Ising problems, each with a five-variable solver. Leveraging a Proximal Policy Optimization (PPO) approach for training their agents, TaipeiQC generated a problem graph and historical configuration data to help the Policy Network understand the state in which it can take action.
And the team did not stop there—they also explored Importance Weighted Actor-Learner Architectures (IMPALA) for training.
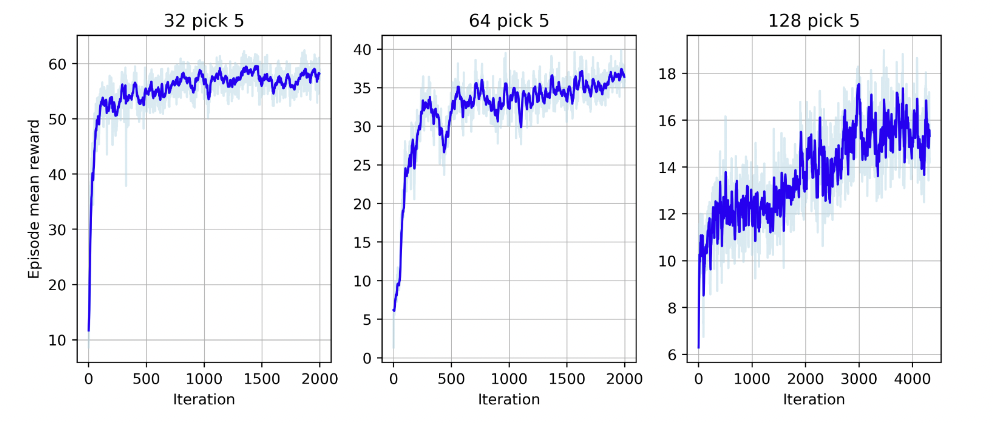
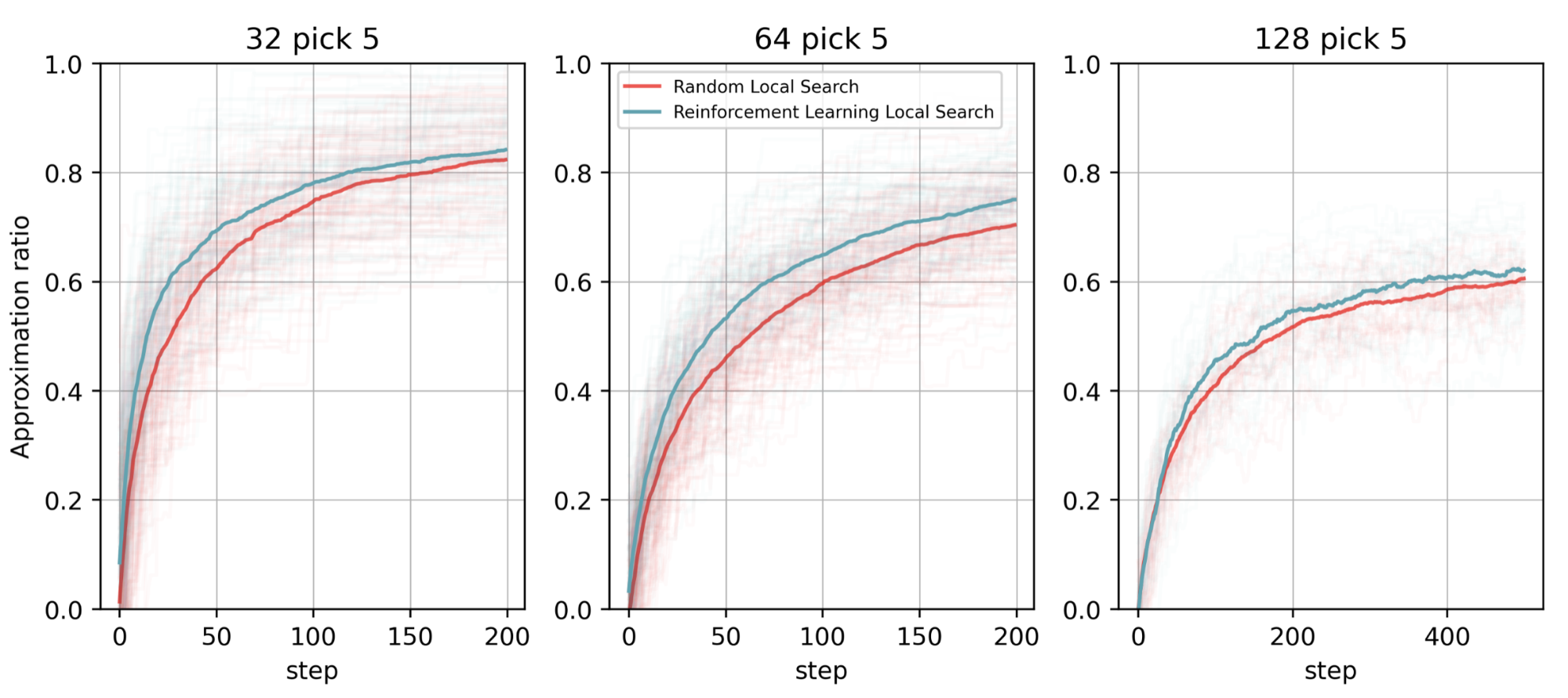
Higher mean rewards are better, and for all of these cases, the RL-QLS approach performs better than QLS, with better approximation ratios in every case (Figure 6). Applying ML techniques to design better quantum algorithms is an interesting intersection between ML and quantum computing.
As the TaipeiQC project shows, there is real promise in applying these techniques to quantum algorithm design. NVIDIA GPUs and the NVIDIA Quantum Platform are critical for workloads like these.
NVIDIA quantum computing
We are excited to see what follow-on work will be done with all the QHack 2023 projects. The technology NVIDIA provides is key to accelerating algorithm development and implementations like these. Faster throughput enables researchers and developers to innovate at a scale and speed not possible before.
To learn more about quantum computing applications and the technology accessible to participants during QHack 2023, check out NVIDIA cuQuantum and NVIDIA CUDA-Q.
