The One Billion Row Challenge is a fun benchmark to showcase basic data processing operations. It was originally launched as a pure-Java competition, and has gathered a community of developers in other languages, including Python, Rust, Go, Swift, and more. The challenge has been useful for many software engineers with an interest in exploring the details of text file reading, hash-based algorithms, and CPU optimizations. As of mid-2024, the One Billion Row Challenge GitHub repo has so far attracted more than 1.8K forks, earned more than 6K stars, and inspired dozens of blog posts and videos.
This post showcases using RAPIDS cuDF pandas accelerator mode to complete the challenge of processing one billion rows of data. Specifically, we demonstrate how two new features in cuDF pandas accelerator version 24.08—large string support and managed memory with prefetching—enable improved performance of large data sizes with GPU-accelerated data processing workflows.
Data processing with RAPIDS cuDF pandas accelerator mode
pandas is an open-source software library built on top of Python specifically for data manipulation and analysis. It’s a flexible tool for data processing that supports the operations needed to complete the One Billion Row Challenge, including parsing a text file, aggregating numeric data by group, and sorting a table.
RAPIDS cuDF is a GPU DataFrame library that provides a pandas-like API for loading, filtering, and manipulating data. And RAPIDS cuDF pandas accelerator mode brings accelerated computing to pandas workflows with zero code changes through a unified CPU/GPU user experience. To learn more, see RAPIDS cuDF Accelerates pandas Nearly 150x with Zero Code Changes.
The following pandas script is sufficient to complete the One Billion Row Challenge:
import pandas as pd
df = pd.read_csv(
“measurements.txt”,
sep=';',
header=None,
names=["station", "measure"]
)
df = df.groupby("station").agg(["min", "max", "mean"])
df = df.sort_values("station")
Running this script with cuDF pandas accelerator mode involves adding a single-line command before importing pandas in Python or Jupyter Notebooks. The command is %load_ext cudf.pandas.
%load_ext cudf.pandas
import pandas as pd
Learn more about RAPIDS cuDF pandas accelerator mode, including different ways of using this mode in Python, such as the Python module flag, or explicitly enabling through import.
New large data processing features in RAPIDS cuDF pandas accelerator mode 24.08
The 24.08 version of RAPIDS cuDF pandas accelerator mode includes two key features for more efficient data processing: large string support and managed memory pool with prefetching. Together, these features work to enable large DataFrame processing—up to 2.1 billion rows of data, with good performance even at 2-3x total GPU memory. Note that Windows Subsystem for Linux (WSL2) has limited support for GPU oversubscription, and the results featured in this post were collected on Ubuntu 22.04.
Large string support
Large string support enables RAPIDS cuDF to dynamically switch between 32-bit and 64-bit indices. Rather than supporting two types of strings explicitly, the way string and large string types exist in PyArrow, strings in cuDF switch to 64-bit indices only when the column data exceeds 2.1 billion characters. This enables cuDF to keep a lower memory footprint and higher processing speed for columns with fewer than 2.1 billion characters, and still support efficient processing for large string columns.
Previously, in version 24.06, string overflow would occur when a string column on the GPU had more than 2.1 billion characters, and the resulting overflow error would cause the data to copy back to the host and fall back to pandas processing. Now, with version 24.08, DataFrames may have a mix of large and small string columns, and each column processes correctly as the string column type in cuDF.
Managed memory pool with prefetching
The managed memory pool with prefetching enables cuDF to use both GPU and host memory to store data and avoid out-of-memory errors. Managed memory, also known as CUDA Unified Virtual Memory, maintains a single address space backed by GPU and host memory. When a GPU kernel launches, any data that is not accessible by the GPU is paged over (migrates) from host memory to GPU memory. Using a memory pool with managed memory reduces the overhead from each allocation and reduces overall execution time. Prefetching is also important for observing good performance with managed memory, because it helps ensure that data is available for GPU kernels without needing to page the data in at the time of compute, which might be “just too late.”
Previously, in version 24.06, larger data sets were more likely to exhaust total GPU memory, and the resulting out-of-memory error would also cause the data to copy back to the host and fall back to pandas processing. Now, with version 24.08, cuDF pandas accelerator mode uses a managed memory pool with prefetching enabled. Note that the best performance with large data sizes can be data and workflow dependent. We welcome your feedback.
Running the One Billion Row Challenge using NVIDIA GPUs
You can run the challenge both on high and low memory GPUs, which shows the performance impact of large data features in RAPDIS cuDF 24.08. At a row count of one billion, the challenge begins with a 13.1 GB text file. In cuDF, this turns into 16 GB of string data and 8 GB of float64 data. The read_csv operation tops out at ~76 GB peak memory footprint and the groupby aggregate operation tops out at ~56 GB peak memory footprint.
Note that the input files were generated according to the One Billion Row Challenge GitHub repo, stored on local NVMe SSD, and cached by the OS during benchmarking. Wall time was measured as the time to execute a complete the subprocess.run command in Python, including all initialization and loading steps.
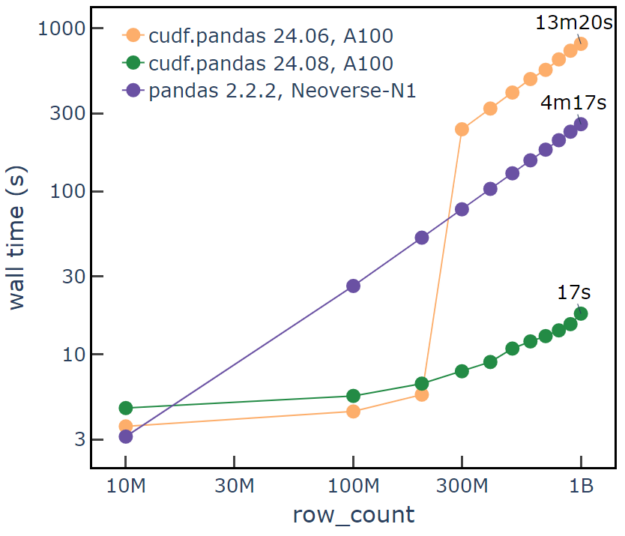
NVIDIA A100 Tensore Core GPU
When running the challenge with RAPIDS cuDF pandas accelerator mode and a GPU with sufficient memory, large string support is critical to good performance. The first hardware set uses an NVIDIA A100 Tensore Core 80 GB PCIe GPU, an Arm Neoverse-N1 CPU with 500 GiB of RAM, and a Samsung MZ1L23T8HBLA SSD. For row counts of 200 million, cuDF shows ~6 seconds runtime, compared to the pandas CPU-only runtime of ~50 seconds. However, for 300 million rows, the string overflow in cuDF 24.06 causes pandas to fall back and increases runtime to ~240 seconds.
With large string support in cuDF 24.08, we observe a one billion row runtime of 17 seconds, which is much faster than the pandas runtime of 260 seconds and cuDF 24.06 runtime of 800 seconds. This is shown in Figure 1 in green. Note that graceful fallback to the CPU due to the GPU running out of memory leads to higher runtime on cuDF 24.06.
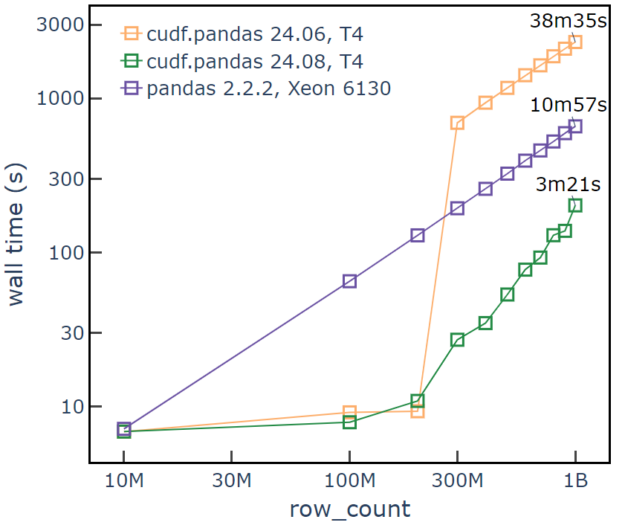
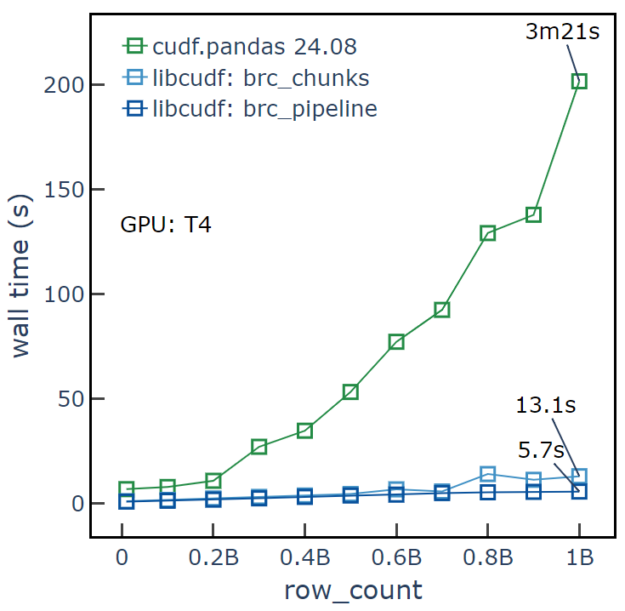
NVIDIA Tesla T4 GPU
We can also evaluate performance on an older generation GPU from 2018 that is widely available on notebook platforms like Colab and Kaggle. In this case, the managed memory pool with prefetching becomes critical for good performance. The second hardware set uses an NVIDIA Tesla T4 14 GB PCIe GPU, an Intel Xeon Gold 6130 CPU with 376 GiB of RAM, and a Dell Express Flash PM1725a SSD. For row counts of 200 million, RAPIDS cuDF pandas accelerator mode shows ~10 seconds runtime compared to a pandas runtime of ~130 seconds. When we scale to one billion rows, the T4 GPU is operating at about 5x oversubscription and still completing with a runtime of 200 seconds, compared to a pandas runtime of 660 seconds (Figure 2).
Overall, the combination of large string support and managed memory pool with prefetching in RAPIDS cuDF pandas accelerator mode 24.08 removes the data size limits that held back performance in version 24.06. In 24.08, the larger memory capacity of the NVIDIA A100 GPU results in a faster runtime and less host-to-GPU data movement than what we observe for the NVIDIA T4 GPU. You can decide which GPU makes sense for your workflows based on cost efficiency and performance. Scaling your data size with cuDF now comes with fewer barriers and more predictable runtimes.
Optimizing the challenge in libcudf
If you’re building GPU-accelerated data processing applications and need lower overhead and faster runtimes, we recommend using RAPIDS libcudf, the CUDA C++ computational core of cuDF. libcudf accelerates database and DataFrame operations, from ingestion and parsing, to joins, aggregations, and more.
We’ve published a module of new C++ examples named billion_rows. These examples demonstrate single-threaded data chunking and multithreaded data pipelining with libcudf. The brc example shows the simple, single-batch processing of the 13 GB One Billion Row Challenge input file. The brc_chunks example shows a chunking pattern that reads byte ranges from the input file, computes partial aggregations, and then combines the final result. The brc_pipeline example shows a pipelining pattern that uses multiple host threads and device CUDA streams to complete the chunked work while saturating copy bandwidth and compute capacity.
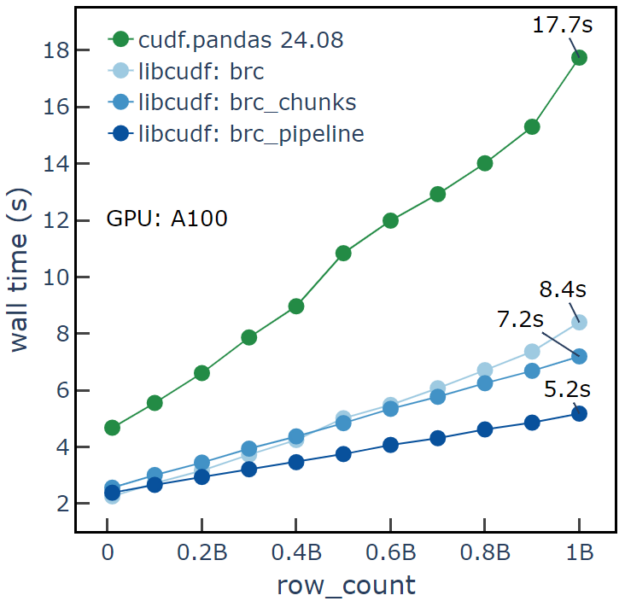
When comparing these methods on an NVIDIA A100 GPU, we find that brc_pipeline achieves the fastest runtime, with ~5.2 seconds runtime using 256 chunks and four threads (Figure 3). With 80 GB of GPU memory on the A100 GPU, all three of the methods can complete the challenge at one billion rows. Chunking and pipelining provide faster runtimes as well as dramatically lowered peak memory footprint. For one billion rows, brc uses 55 GB peak memory, while brc_chunks and brc_pipeline use <1 GB peak memory. The techniques in the libcudf billion_rows example module show how to complete large workflows while efficiently saturating GPU resources and PCIe bandwidth.
Shifting over to the NVIDIA T4 GPU, we find that the brc_pipeline method also achieves the fastest runtime, with ~5.7 seconds runtime using 256 chunks and four threads (Figure 4). For the optimized brc_pipeline case, results for both the T4 and A100 GPUs look similar due to the limits of data transfer from host to GPU over PCIe. With the 16 GB memory capacity of T4, the brc example runs out of memory after 200 million rows and can’t complete the challenge. Chunking and pipelining are effective methods for efficiently completing the challenge, even with lower memory capacity GPUs like T4.
Get started
Processing large datasets is now easier than ever with RAPIDS cuDF pandas accelerator mode. With large string support, your string processing workflow can scale beyond the previous 2.1 billion character limit. With the new managed memory pool, your data processing memory footprint can extend beyond the GPU memory limit. To get started with cuDF pandas accelerator mode, check out RAPIDS cuDF Instantly Accelerates pandas up to 50x on Google Colab.
RAPIDS cuDF pandas accelerator mode is built using RAPIDS libcudf, the CUDA C++ library for GPU data processing. To get started with RAPIDS libcudf, try building and running a few C++ examples. RAPIDS Docker containers are also available for releases and nightly builds to enable easier testing and deployment.
