
NVIDIA has released RAPIDS cuDF unified memory and text data processing features that help data scientists continue to use pandas when working with larger and text-heavy datasets in demanding workloads. Data scientists can now accelerate these workloads by up to 30x.
RAPIDS is a collection of open-source GPU-accelerated data science and AI libraries. cuDF is a Python GPU DataFrame library for loading, joining, aggregating, and filtering data.
A top data processing library for data scientists, pandas is a flexible and powerful data analysis and manipulation library for Python. It was downloaded more than 200 million times in the last month. However, as dataset sizes grow, pandas struggles with processing speed and efficiency in CPU-only systems. This forces data scientists to choose between slow execution times and switching costs associated with using other tools.
NVIDIA announced at GTC 2024 that RAPIDS cuDF accelerates pandas nearly 150x with zero code changes. Google then announced that RAPIDS cuDF is available by default on Colab at Google I/O, making pandas code acceleration more accessible than ever before.
While this momentum is exciting, user feedback highlighted limitations in the size and types of workloads that can use RAPIDS cuDF pandas acceleration. More specifically:
- To maximize acceleration, datasets need to fit within GPU memory, with ample space for group-by and joins operations that spike memory requirements for workloads. This requirement has significantly limited the amount of data and operational complexity of the pandas code that users can apply acceleration to, especially on lower-memory GPUs.
- Users also quickly ran into processing constraints with text-heavy datasets in the original release of cuDF, which supported up to 2.1 billion characters in a column. This limit can be easily reached with standard customer logs, product reviews, and location-dense datasets. This created limitations when preprocessing large strings for LLMs and similar generative AI use cases.
To address this feedback, the latest release of RAPIDS cuDF pandas accelerator mode includes:
- A built-in optimized CUDA unified memory feature that optimizes memory utilization of the CPU+GPU system to enable up to 30x speedups of larger datasets and more complex workloads.
- Expanded string support from 2.1 billion characters in a column to 2.1 billion rows of tabular text data to support data preprocessing text-heavy data used in LLMs and other demanding use cases.
With this release, you can efficiently accelerate larger datasets and text-heavy use cases on the GPU, making cuDF a better fit for diverse and demanding workflows.
Accelerated data processing with unified memory
To enable zero code change acceleration and a seamless experience, cuDF relies on CPU fallback. When the memory requirements of a workflow exceed GPU memory, cuDF transfers the data into CPU memory and uses pandas to process the data.
Because common operations like joins and group-by aggregations spike memory higher than the size of the input data, avoiding CPU fallback when processing large datasets requires input data to leave significant space in GPU memory.
To address this, cuDF now uses CUDA unified memory to enable scaling pandas workloads beyond GPU memory. Unified memory provides a single address space spanning the CPUs and GPUs in your system, enables virtual memory allocations larger than available GPU memory (oversubscription), and migrates data in and out of GPU memory as needed (paging).
However, using unified memory can result in repeated page faults when data is needed but isn’t on the GPU, which can slow down performance. To maximize performance, cuDF includes optimizations to help ensure data is resident on the GPU before CUDA kernels need it. This enables you to take advantage of complete system memory to scale beyond GPU memory and continue to leverage the benefits of accelerated computing. To achieve peak acceleration, datasets should still be sized to fit entirely in GPU memory.
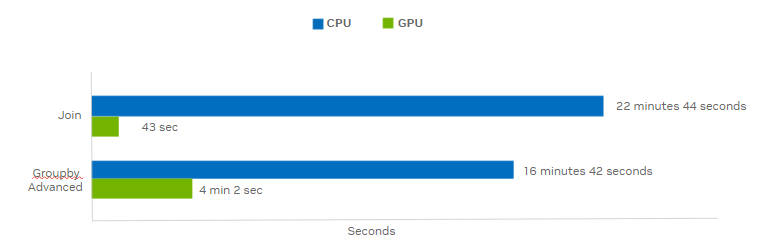
As shown in the benchmark for accelerated pandas outside of GPU memory (Figure 1), running data processing workloads with a 10 GB dataset using cuDF achieved up to 30x speedups for data joins on a 16 GB memory GPU compared to CPU-only pandas. Previously, processing datasets larger than 4 GB would have slowed performance because of GPU memory constraints. Reminder: the maximum GPU memory utilized by a workload during its execution might exceed the input dataset size.
HW: NVIDIA T4, CPU: Intel Xeon Gold 6130 CPU; SW: pandas v2.2.2, RAPIDS cuDF 24.08
For more information about these benchmark results and how to reproduce them, see the cuDF benchmarks guide. Note that our previous DuckDB benchmarks were run on 0.5 GB and 5 GB, so this would require changing the data generation scripts and data processing scripts to enable the creation of 10 GB benchmarks.
Processing tabular text data at scale with RAPIDS cuDF
In the original release, cuDF supported up to 2.1 billion total characters in a column of text data, which is easily outstripped in common large datasets. Processing product review data, customer service chat logs, or large datasets with substantial locations or user ID data are common examples of how that limitation can be easily met.
Strings are notoriously slow to execute using CPU-only pandas, making it infeasible to use pandas code to process tabular text data at scale. User feedback indicates that large strings in text-heavy datasets is a use case that could benefit from acceleration. This was originally limited by the design of cuDF.
cuDF can now process up to 2.1 billion rows of tabular text data using pandas code on the GPU by significantly increasing the number of characters supported in strings. This makes pandas a viable tool for data preparation in generative AI pipelines.
Get started
All these features are available with RAPIDS 24.08, which you can download from the RAPIDS Installation Guide. Note that the unified memory feature only works on Linux-based systems.
- To experience unified memory, try the Unified Memory demo notebook, which explains more of how the expanded memory capability works.
- To test a large strings preprocessing workflow, check out the Job Postings demo notebook.
