
NVIDIA CUDA-Q (formerly NVIDIA CUDA Quantum) is an open-source programming model for building hybrid-quantum classical applications that take full advantage of CPU, GPU, and QPU compute abilities. Developing these applications today is challenging and requires a flexible, easy-to-use coding environment coupled with powerful quantum simulation capabilities to efficiently evaluate and improve the performance of new algorithms.
CUDA-Q is a platform built specifically with this in mind. Its ability to effortlessly switch between simulation and a broad range of actual QPU hardware backends makes it a long-term solution to quantum application development. The recent v0.8 release further improves the CUDA-Q simulation performance, developer experience, and flexibility.
In this post, we discuss some of the top highlights from CUDA-Q v0.8:
- State handling
- Pauli words
- Custom unitary operations
- Visualization tools
- NVIDIA Grace Hopper integration
State handling
Quantum state preparation is a core component of useful quantum algorithms, but it is often one of the most complex and expensive elements to simulate. Keeping the same state in memory and reusing it can optimize simulations when the state is used multiple times with different parameters or following classical pre– and post-processing steps.
You can now construct CUDA-Q kernels based on a provided state vector. The following code example shows this by specifying a 4-entry state vector corresponding to a 2-qubit state.
c = [.707, 0, 0, .707]
@cudaq.kernel
def initial_state():
q = cudaq.qvector(c)
Following the execution of a quantum circuit, the state can now be retained on GPU memory and easily passed to future kernels using optimized memory transfer tools.
The state-handling tools can be especially helpful for quantum algorithms that are recursive or iterative in nature.
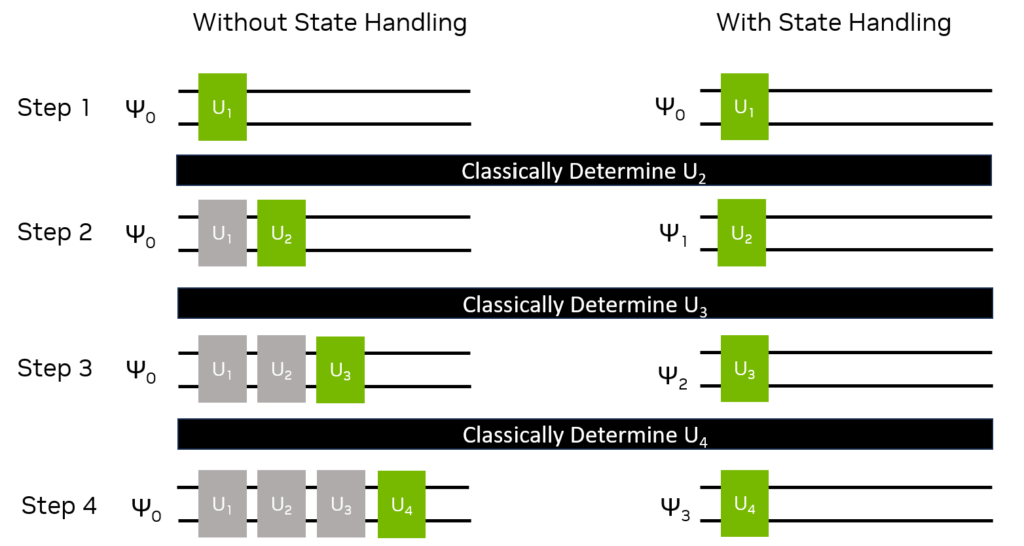
Figure 1 represents an example case where subsequent quantum operations \(U_{n+1}\) (green boxes) are determined classically based on measurement results from the previous state (\(\psi_n\)).
Without state handling, the \(n+1\) step would require the simulation of all previous operations (gray boxes) to produce \(\psi_n\) before \(U_{n+1}\) is applied and the process continues.
Retaining the previous state in GPU memory eliminates the need to perform all previous operations, significantly boosting performance.
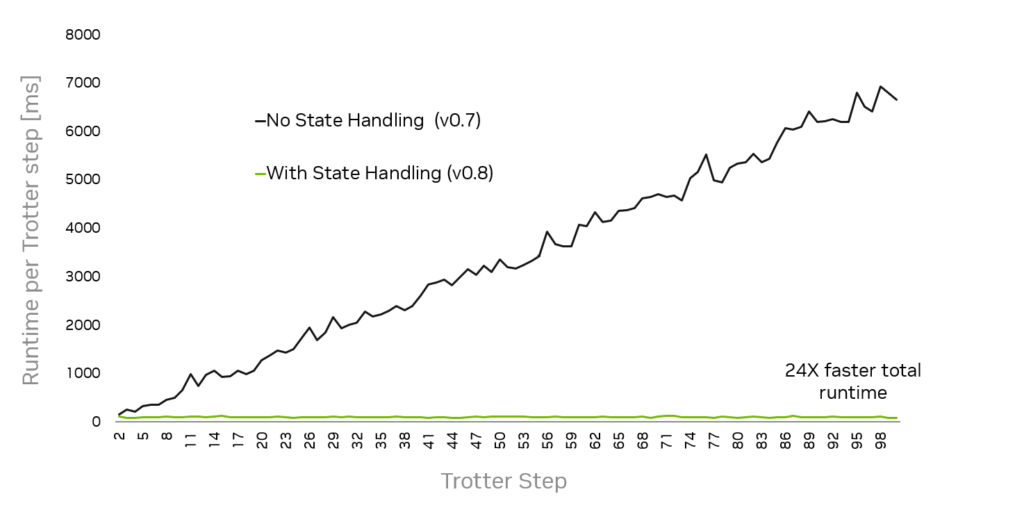
Simulating Trotter dynamics is a great quantitative example of a state-handling performance boost. In a 25-qubit benchmark of a Heisenberg Hamiltonian simulation (Figure 2), saving the previous state means each step takes approximately the same amount of time. Without state handling, the steps become increasingly onerous. For a simulation with 100 steps, state handling results in an impressive 24x faster total simulation time.
Pauli words
Pauli words are tensor products of the single-qubit X, Y, Z, I Pauli operators (P). Exponentiating these operators (\(e^{-i\theta P}\)) results in single qubit rotation gates: Rx(\(\theta\)), Ry(\(\theta\)), Rz(\(\theta\)).
Certain algorithms require more complex operations derived from the exponentiation of whole Pauli words.
CUDA-Q v0.8 now includes a new pauli_word type that can be input to a quantum kernel and converted into a quantum circuit operation with exp_pauli. The following code example shows how a list of Pauli words and their associated coefficients can be used to apply the following operation:
\(e^{i(0.432XYZ + 0.324IXX)}\)
words = ['XYZ', 'IXX']
coefficients = [0.432, 0.324]
@cudaq.kernel
def kernel(coefficients: list[float], words: list[cudaq.pauli_word]):
q = cudaq.qvector(3)
for i in range(len(coefficients)):
exp_pauli(coefficients[i], q, words[i])
The Pauli words and their respective coefficients are input as lists to the kernel and then transformed into a quantum circuit operation with exp_pauli. The Trotter simulation example discussed in the previous section makes use of this feature for Hamiltonian simulation. For more information, see the trotter_kernel_mode.py script on GitHub.
Custom unitary operations
Using a unitary operation is sometimes preferred to gates when designing quantum algorithms that are more abstract, have oracles, or have no exactly known gate set.
You can now execute custom unitary operations within CUDA-Q kernels. The following code example shows how to specify a custom unitary operation as a NumPy array, name it, and then use it in a kernel. A custom standard X gate is specified as a 2×2 unitary matrix with rows [0,1] and [1,0]. The example also demonstrates how custom unitaries can be applied using a controlled operation of one or more qubits.
import numpy as np
cudaq.register_operation("custom_x", np.array([0, 1, 1, 0]))
@cudaq.kernel
def kernel():
qubits = cudaq.qvector(2)
h(qubits[0])
custom_x(qubits[0])
custom_x.ctrl(qubits[0], qubits[1])
counts = cudaq.sample(kernel)
counts.dump()
Visualization tools
Visualization tools are invaluable for learning quantum computing concepts, designing algorithms, and collaborating on research. Participants in the 2024 Unitary Hack event contributed enhanced quantum-circuit and Bloch sphere visualization to CUDA-Q.
Any kernel can be visualized using the print(cudaq.draw(kernel)) command. By default, an ASCII representation prints in the terminal (Figure 4).
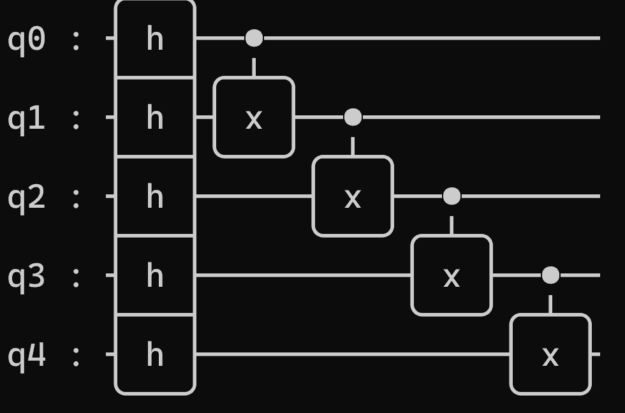
LaTeX is a text preparation and typesetting tool often used to prepare scientific publications. The following command prints a LaTeX string:
print(cudaq.draw(‘latex’, kernel))
To prepare a typeset quantum circuit, copy the string into any LaTeX editor (such as Overleaf) and then export it to PDF.

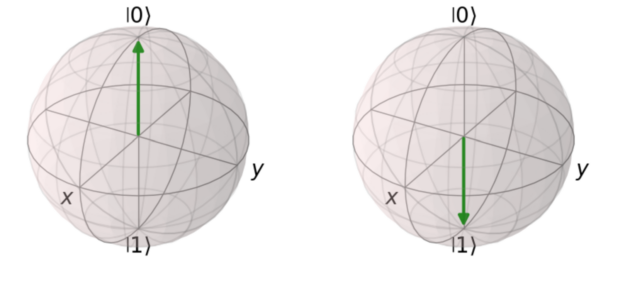
CUDA-Q v0.8 now also uses QuTip, an open-source Python package for dynamics simulations, to visualize Bloch spheres corresponding to single-qubit states. Figure 6 shows a detailed example of visualizing one or more Bloch spheres. For more information, see Qubit Visualization.
NVIDIA Grace Hopper integration
You can now use CUDA-Q to leverage the full performance of the NVIDIA GH200 Superchip, pushing the boundaries of quantum simulation even further. The large memory bandwidth enables significant speedup in simulating quantum systems, with simulations on the GH200 Superchip needing only a quarter of the nodes previously required. This is particularly important for quantum simulations, which are usually bottlenecked by memory.
Getting started with CUDA-Q
The continued improvement of CUDA-Q provides you with a more performant platform to build quantum-accelerated supercomputing applications. It’s a more performant simulation platform and applications constructed on CUDA-Q are also positioned to deploy in the future hybrid CPU, GPU, and QPU environments necessary for practical quantum computing.
For more information, see the following resources:
- CUDA-Q Quick Start guide: Quickly set up your environment.
- CUDA-Q Basics: Write your first CUDA-Q application.
- CUDA-Q By Example and CUDA-Q Tutorials: Get inspiration for your own quantum application development.
To provide feedback and suggestions, see the /NVIDIA/cuda-quantum GitHub repo.
