Large-scale graph neural network (GNN) training presents formidable challenges, particularly concerning the scale and complexity of graph data. These challenges extend beyond the typical concerns of neural network forward and backward computations, encompassing issues such as bandwidth-intensive graph feature gathering and sampling, and the limitations of single GPU capacities.
In my previous post, I introduced WholeGraph as a breakthrough feature within the RAPIDS cuGraph library, designed to optimize memory storage and retrieval for large-scale GNN training.
Building upon the foundation laid in my introductory post, this post dives deeper into the performance evaluation of WholeGraph. My focus extends to its role as both a storage library and a facilitator of GNN tasks. Using the power of the NVIDIA NVLink technology, I examine how WholeGraph addresses the challenges of inter-GPU communication bandwidth, effectively breaking down communication bottlenecks and streamlining data storage.
By examining its performance and real-world application, I aim to showcase the effectiveness of WholeGraph in overcoming the hurdles inherent in large-scale GNN training.
WholeGraph performance as storage
To evaluate the performance of using WholeGraph as storage, I measured the bandwidth of random gathering of fixed-length memory. The fixed length is organized as a float embedding vector with a fixed embedding dimension.
The testing was conducted on an NVIDIA DGX-A100 system, covering all memory types supported by WholeGraph:
- Eight NVIDIA A100 GPUs interconnected through NVIDIA NVSwitch.
- Bidirectional bandwidth of 600 GB/s per GPU, translating to 300 GB/s per GPU of bandwidth in each direction.
- Every two GPUs are connected to a PCIe 4.0 switch, sharing a PCIe 4.0 x16 host bandwidth, resulting in a shared bandwidth of 32GB/s to host memory for every two GPUs.
- The theoretical gather bandwidth for memory across multiple GPUs is 300 GB/s * 8 / 7 = 343 GB/s per GPU. Regarding host memory, the theoretical gather bandwidth for each GPU is 32 GB/s / 2 = 16 GB/s.
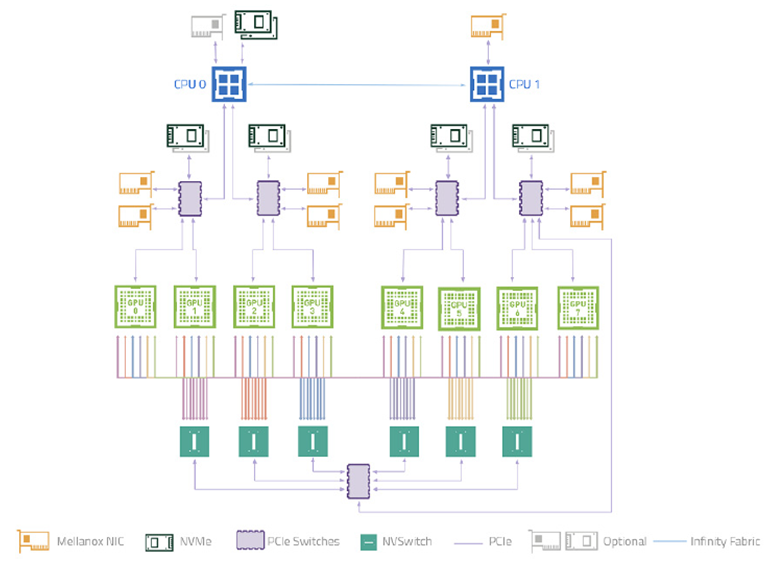
Table 1 shows the benchmark results. As host memory with continuous and chunked type are using the same implementation now, they are using the same column. As you can see, for chunked device memory, you can get 75% of the NVLink bandwidth. For host memory, you can get ~80% of PCIe bandwidth.
| Embedding dimension | Continuous device | Chunked device | Distributed device | Non-Distributed* host | Distributed host |
| 32 | 2.78 | 264.16 | 113.29 | 2.47 | 11.73 |
| 64 | 5.35 | 260.99 | 133.25 | 4.91 | 12.2 |
| 128 | 10.35 | 261.03 | 144.61 | 9.73 | 12.31 |
| 256 | 19.74 | 261.18 | 149.51 | 13.18 | 12.34 |
| 512 | 36.93 | 261.45 | 151.82 | 12.89 | 12.34 |
| 1024 | 68.66 | 260.25 | 155.28 | 13.18 | 12.34 |
*Non-Distributed host means Continuous host and Chunked host, as they are using the same implementation.
WholeGraph performance in GNN tasks
To evaluate the performance of WholeGraph in GNN tasks, I used the ogbn-papers100M dataset as a test dataset. The dataset has about 111M nodes and about 3.2B edges. Each node has a 128-dim feature. The task is 172-class node classification.
In this evaluation, I used WholeGraph 23.10 for graph and feature storage and cuGraphOps for the GNN layer implementation. As earlier, the tests are also on a DGX-A100 server.
Computational performance improvements
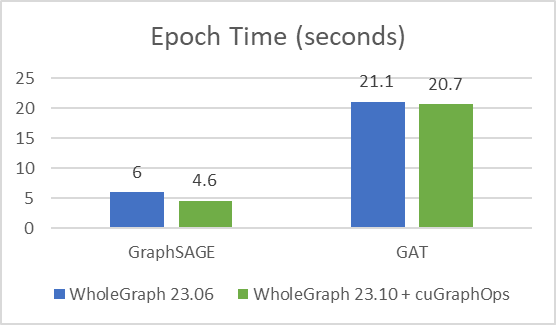
First, I’d like to highlight the performance improvement of the latest version of WholeGraph 23.10, which uses cuGraph-Ops, against the previous version of WholeGraph.
I used the same training configuration and training sample count, in which the sample count is [30,30,30], and I trained for 24 epochs to verify that the accuracy is good (around 65% test accuracy). The improvement is shown in Figure 2.
Time to convergence optimization
For any dataset, there might be an optimal sample count or other hyperparameters that produce the best time to target accuracy. Increasing the sample count may result in a large amount of computation but produce little accuracy improvements.
I found that for the ogbn-papers100M dataset, targeting 65% test accuracy, it is okay to use [15,10,5] as a training sample count. This is the same sample count that Intel used in their paper.
Using similar sample counts is important for comparison as reducing the number of samples can significantly reduce computational load. For instance, the reduction in computational workload by reducing sample count from [30,30,30] to [15,10,5] can be as much as 36x. The 24 epochs might be also not needed to achieve around 65% test accuracy. I also tuned hyperparameters such as batch-size and learning rate.
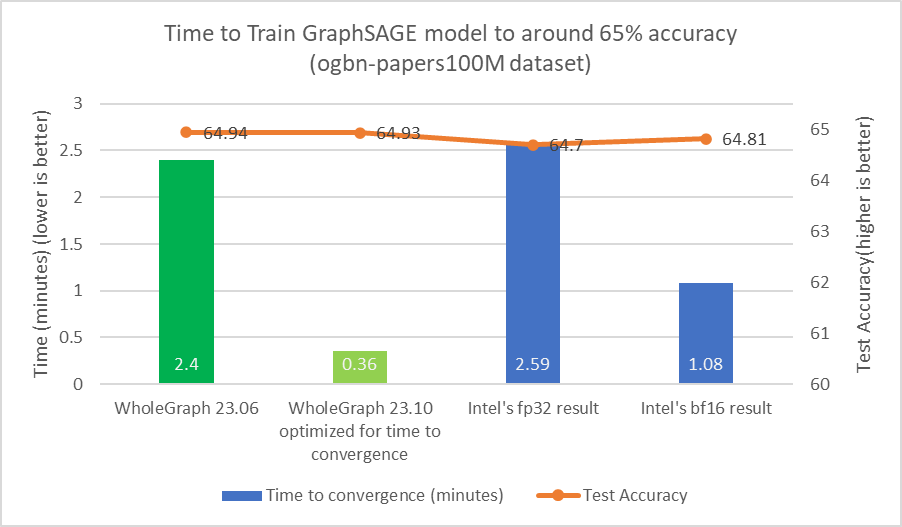
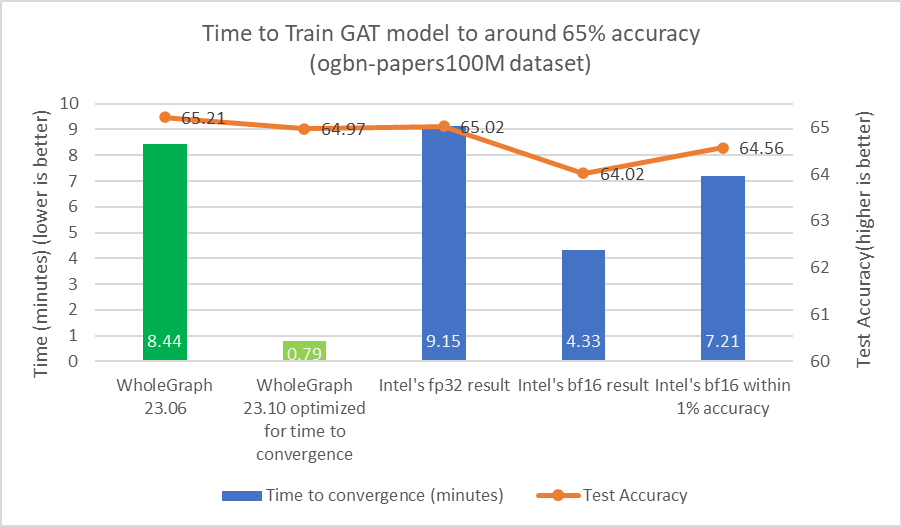
From Figures 3 and 4, you can see that WholeGraph can achieve a high level of acceleration in terms of time to convergence. For more information about comparing with 8-node dual-socket Intel 8480+ CPU servers, see Setting Graph Neural Network Models in Record Time. (For time to convergence, the computation may be different.)
Conclusion
In this post, I showcased the performance of WholeGraph, which comes remarkably close to the theoretical performance of the hardware. I demonstrated its performance in real-world GNN tasks, highlighting its capability to significantly accelerate GNN workloads. As the underlying hardware, NVIDIA GPU and NVLink technology provide the best hardware platform for GNN tasks.
