
Celebrating the SuperComputing 2022 international conference, NVIDIA announces the release of HPC Software Development Kit (SDK) v22.11. Members of the NVIDIA Developer Program can download the release now for free.
The NVIDIA HPC SDK is a comprehensive suite of compilers, libraries, and tools for high performance computing (HPC) developers. It provides everything developers need to productively develop high performance applications. The HPC SDK and its components are updated numerous times each year with new capabilities, performance advancements, and other enhancements.
Designed for asynchronous programming with C++
In addition to the usual fixes and enhancements, the new v22.11 release gives you a preview of the innovative stdexec library designed to standardize C++ asynchrony. This library enables developers to write high-level algorithmic code that is not specific to CPU or GPU machines, resulting in improved programmer productivity and application portability.
The stdexec library introduces the ability to schedule work asynchronously, which results in better resource utilization and performance than the existing C++ parallel algorithms. This enables fine-grained execution control, minimizing latencies, and even leveraging the performance advantages of multi-GPU/multi-node systems.
The stdexec library is an early implementation of a C++ Standardization Committee proposal that enables matching the HPC workload with the most appropriate computing resources. Sometimes referred to as Senders, this library empowers you, the developer, to control precisely where and how you want your work to execute, ultimately delivering portable parallelism.
Scale applications with multi-node math libraries
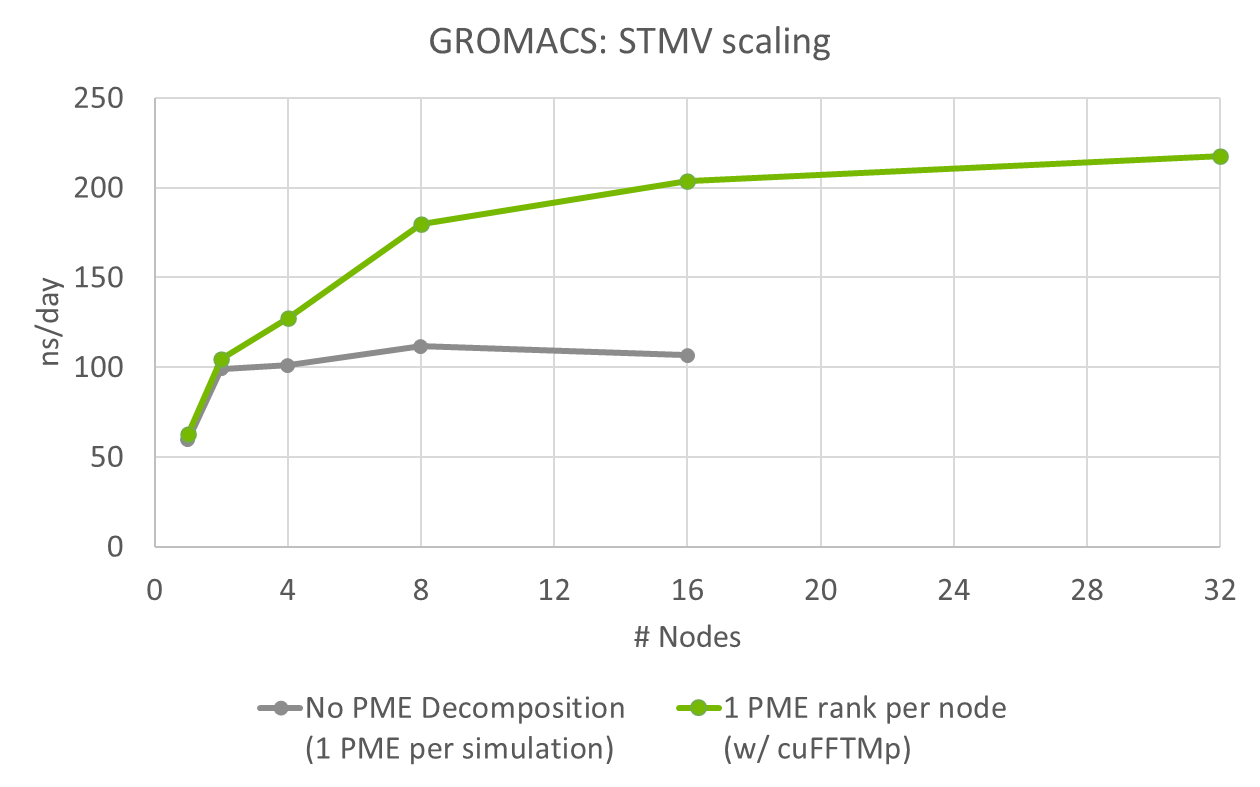
The HPC SDK now contains the latest cuSOLVER and cuFFT multi-node functionality. These libraries enable users to write software applications that scale to thousands of GPUs with just a few lines of code. Recently, multi-node FFTs have been integrated into the HPC application GROMACS, providing performance improvements.
GROMACS, a simulation package for molecular dynamics, is one of the most-used HPC applications worldwide. Historically, the application was only able to compute Particle-Mesh Ewald (PME) long-range forces between atoms with a single rank and single GPU. This limits multi-node scalability of the full simulation. By integrating the new multi-node functionality, GROMACS can now compute multiple PME ranks in the simulation, providing enhanced scalability and performance.
Figure 1 shows the performance improvements of this new feature, for a real scientific test case. The results, from the NVIDIA Selene cluster using 4 A100-SXM4 GPUs per node, demonstrate that scalability has improved from 2 to 32 nodes, allowing a large boost in performance.
The term ns/day refers to the number of nanoseconds (ns) of simulation (the variable time in the simulation) that are possible in a day of computation (elapsed real time or wall time). This is a useful metric to schedule your work or to get a sense of what is achievable in a given period of time.
More HPC, math library, and parallel programming resources
To get started with stdexec and the NVIDIA math libraries, download the new HPC SDK 22.11 update for free from the NVIDIA Developer Zone.
Learn more about the HPC SDK, the advantages of standards-based parallel programming, and multi-node GPU-accelerated math libraries. You can also reference the NVIDIA HPC SDK Version 22.9 Documentation.
Additional resources
- Why Standards-Based Parallel Programming Should Be in Your HPC Toolbox
- Leveraging Standards-Based Parallel Programming in HPC Applications
- Developing Accelerated Code with Standard Language Parallelism
- Multi-GPU Programming with Standard Parallel C++ (Part 1)
- Multi-GPU Programming with Standard Parallel C++ (Part 2)
- Using Fortran Standard Parallel Programming for GPU Acceleration
