To help accelerate natural language processing in biomedicine, Microsoft Research developed a BERT-based AI model that outperforms previous biomedicine natural languag processing (NLP) methods. The work promises to help researchers rapidly advance research in this field.
The model, built on top of Google’s BERT, can classify documents, extract medical information, detect specific name entities, and much more.
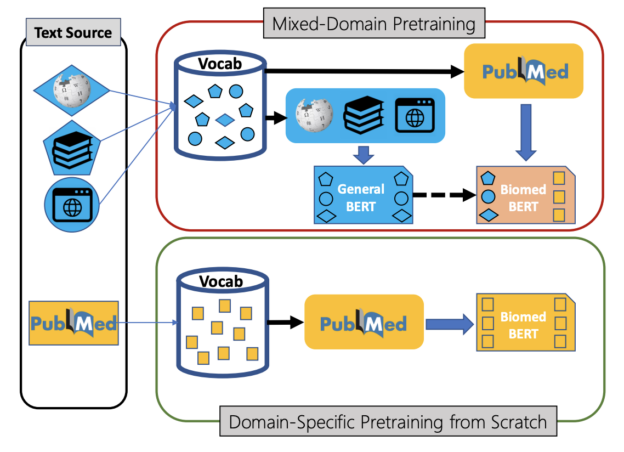
To develop the model, called PubMedBERT, the researchers compiled a comprehensive biomedical NLP benchmark, sourced from publicly-available datasets.
“Our experiments show that domain-specific pretraining serves as a solid foundation for a wide range of biomedical NLP tasks, leading to new state-of-the-art results across the board,” the researchers stated in their paper, Domain-Specific Language Model Pretraining for Biomedical Natural Language Processing.
The model was trained using vocabulary from the PubMed dataset which includes over 14 million abstracts and 3.2 billion words. They used an NVIDIA DGX-2 with 16 NVIDIA V100 GPUs, and NVIDIA’s NGC TensorFlow implementation.
The researchers have released their state-of-the-art pretrained and task-specific models for the community, and have also created a leaderboard featuring a comprehensive benchmark called BLURB.
