At GTC DC in Washington DC, NVIDIA announced NVIDIA BioBERT, an optimized version of BioBERT. BioBERT is an extension of the pre-trained language model BERT, that was created specifically for biomedical and clinical domains.
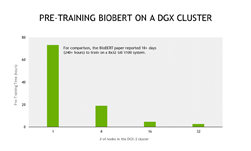
For context, over 4.5 billion words were used to train BioBERT, compared to 3.3 billion for BERT. BioBERT was built to address the nuances of biomedical and clinical text (which each have their own distinct writing styles, vocabulary and jargon). However, training large language models like BioBERT is computationally expensive. The original authors from Korea University reported that it took them over 10 days to pre-train BioBERT on 8 32GB NVIDIA V100 GPUs.
NVIDIA’s BioBERT, an optimized version of the implementation presented in the original BioBERT paper, leverages automatic mixed precision arithmetic and Tensor Cores on NVIDIA V100 GPUs producing faster training times while maintaining target accuracy. It also provides efficient scale out to multiple GPUs for both pre-training and fine-tuning.
The goal of this work is to make it fast and easy for the biomedical community to use the state of the art NLP models in pursuit of the next medical breakthrough.
For comparison, pre-training BioBERT using Automatic Mixed Precision takes less than 3 days on a NVIDIA DGX-2, which contains 16 32GB NVIDIA V100 GPUs. With the excellent scaling that these scripts provide, this entire process can be done in less than 3 hours using a 32 node DGX-2 cluster.
Unlike the original fine-tuning scripts, the ones provided in NVIDIA’s BioBERT support scaling to multiple GPUs. They also provide improved performance through Automatic Mixed Precision as seen in the second graph below. For fast inference, these models can be deployed using TensorRT Inference Server.
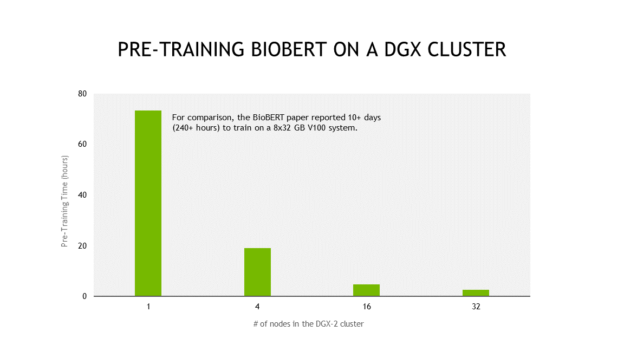
Efficient Scale out dramatically reduces pre-training times from days to hours
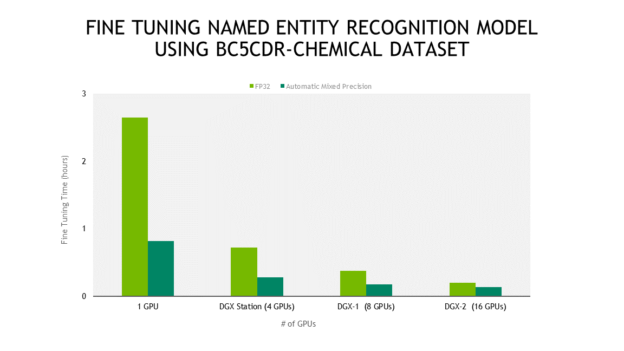
Automatic Mixed Precision Provides up to 3x speed up
- If you want to use BioBERT for pre-training or for fine-tuning, check out BioBERT on our Deep Learning Examples GitHub Repo
- Check out our inference notebook to to try these cutting-edge NLU models.
