

In June 2020, we released the first NVIDIA Display Driver that enabled GPU acceleration in the Windows Subsystem for Linux (WSL) 2 for Windows Insider Program (WIP) Preview users. At that time, it was still an early preview with a limited set of features. A year later, as we have steadily added new capabilities, we have also been focusing on optimizing the CUDA driver to deliver top performance on WSL2.
WSL is a Windows 10 feature that enables you to run native Linux command-line tools directly on Windows, without requiring the complexity of a dual-boot environment. Internally, WSL is a containerized environment that is tightly integrated with the Microsoft Windows OS. WSL2 enables you to run Linux applications alongside traditional Windows desktop and modern store apps. For more information about CUDA on WSL, see Announcing CUDA on Windows Subsystem for Linux 2.
In this post, we focus on the current state of the CUDA performance on WSL2, the various performance-centric optimizations that have been made, and what to look forward to in the future.
Current state of WSL performance
Over the past several months, we have been tuning the performance of the CUDA Driver on WSL2 by analyzing and optimizing multiple critical driver paths, both on the NVIDIA and the Microsoft sides. In this post, we go into detail on what we have done exactly to reach the current performance level. Before we start that, here’s the current state of WSL2 on a couple of baseline benchmarks.
On WSL2, all the GPU operations are serialized through VMBUS and sent to the host kernel interface. One of the most common performance questions around WSL2 is the overhead of said operations. We understand that developers want to know whether there is any overhead to running workloads in WSL2 compared to running them directly on native Linux. Is there a difference? Is this overhead significant?
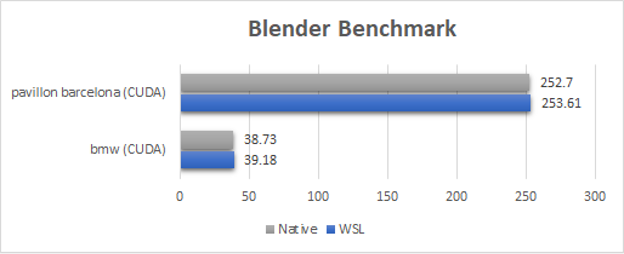
For the Blender benchmark, WSL2 performance is comparable or close to native Linux (within 1%). Because Blender Cycles push a long running kernel on the GPU, the overhead of WSL2 is not visible on any of those benchmarks.
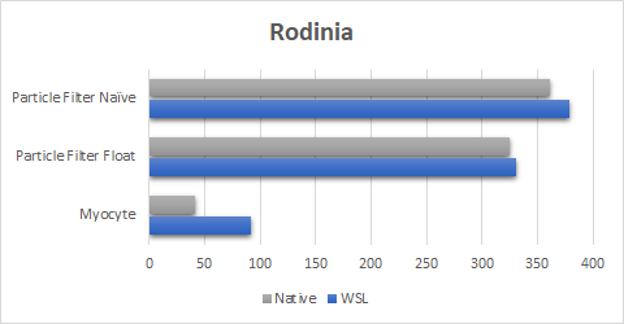
When it comes to the Rodinia Benchmark suite (Figure 2), we have come a long way from the performance we were able to achieve when we first launched support for WSL2.
The new driver can perform considerably better and can even reach close to native execution time for Particle Filter tests. It also finally closes the gap for the Myocyte benchmark. This is especially of consequence for the Myocyte benchmark where the early results with WSL2 were up to 10 times slower compared to native Linux. Myocyte is particularly hard on WSL2, as this benchmark consists of many extremely small sequential submissions (less than microseconds), making it a sequential launch latency microbenchmark. This is an area that we’re investigating to achieve complete performance parity.
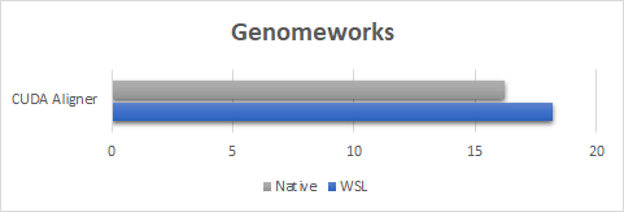
For the GenomeWorks benchmark (Figure 3), we are using CUDA aligner for GPU-Accelerated pairwise alignment. To show the worst-case scenario of performance overhead, the benchmark runs here were done with a sample dataset composed of short running kernels. Due to how short the kernel launches are, you can observe the launch latency overhead on WSL2. However, even for this worst-case example, the performance is equal to or more than 90% of the native speed. Our expectation is that for real-world use cases, where dataset sizes are typically larger, performance will be close to native performance.
To explore this key trade-off between kernel size and WSL2 performance, look at the next benchmark.
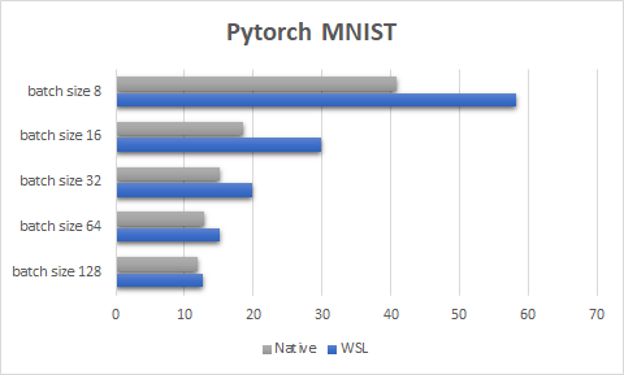
Figure 4 shows the PyTorch MNIST test, a purposefully small, toy machine learning sample that highlights how important it is to keep the GPU busy to reach satisfactory performance on WSL2. As with native Linux, the smaller the workload, the more likely that you’ll see performance degradation due to the overhead of launching a GPU process. This degradation is more pronounced on WSL2, and scales differently compared to native Linux.
As you keep improving the WSL2 driver, this difference in scaling for exceedingly small workloads should become less and less pronounced. The best way to avoid these pitfalls, both on WSL2 and on native Linux, is to keep the GPU busy as much as possible.
| WSL2 | Native Linux | |
| OS | Latest Windows Insider Preview | Ubuntu 20.04 |
| WSL Kernel Driver | 5.10.16.3-microsoft-standard-WSL2 | N/A |
| Driver Model | GPU Accelerated Hardware Scheduling | N/A |
| System | All benchmarks were run on the same system with an NVIDIA RTX 6000 | All benchmarks were run on the same system with an NVIDIA RTX 6000 |
| Benchmark name | Description |
| Blender | Classic blender benchmark run with CUDA (not NVIDIA OptiX) on the BMW and Pavillion Barcelona scenes. |
| NVIDIA GenomeWork | CUDA pairwise alignment sample (available as a sample in the GenomeWork repository). |
| PyTorch MNIST | Modified (code added to time each epoch) MNIST sample. |
| Myocyte, Particle Filter | Benchmarks that are part of the RODINIA benchmark suite. |
Launch latency optimizations
Launch latency is one of the leading causes of performance disparities between some native Linux applications and WSL2. There are two important metrics here:
- GPU kernel launch latency: The time it takes to launch a kernel with a CUDA call and start execution by the GPU.
- End-to-end overhead (launch latency plus synchronization overhead): The overall time it takes to launch a kernel with a CUDA call and wait for its completion on the CPU, excluding the kernel run time itself.
Launch latency is usually negligible when the workload pushed onto the GPU is significantly bigger than the latency itself. Thanks to CUDA primitives like streams and graphs, you can keep the GPU busy and can leverage the asynchronous nature of these APIs to overcome any latency issues. However, when the execution time of the workload sent to the GPU is close to the launch latency, then it quickly becomes a major performance bottleneck. The launch latency will act as a launch rate limiter, which causes kernel execution performance to plunge.
Launch latency on native Windows
Before diving into what makes launch latency a significant obstacle to overcome on WSL2, we explain the launch path of a CUDA kernel on native Windows. There are two different launch models implemented in the CUDA driver for Windows: one for packet scheduling and another for hardware-accelerated GPU scheduling.
Packet scheduling
In packet scheduling, the OS is responsible for most of the scheduling work. However, to compensate for the submission model and the significant launch overhead, the CUDA driver always tries to batch a certain number of kernel launches based on various heuristics. Figure 5 shows that in packet scheduling mode, the OS schedules submissions and they are serialized for a given context. This means that all work of one submission must finish before any work of the next submission can start.
To improve the throughput in packet scheduling mode, the CUDA driver tries to aggregate some of the launches together in a single submission, even though internally they are dispatched across multiple GPU queues. This heuristic helps with false dependency and parallelism, and it also reduces the number of packets submitted, reducing scheduling overhead times.
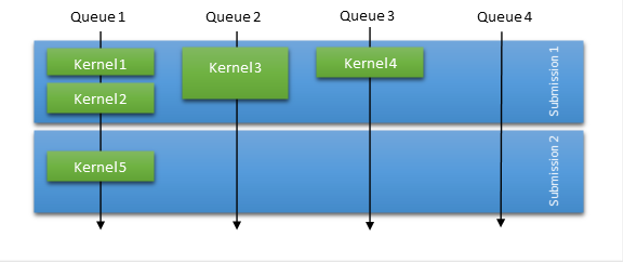
In this submission model, you see performance reach its limits when the workload is launch latency bound. You can force outstanding submissions to be issued, by querying the status of a stream with a small pending workload. In this case, it still suffers from high scheduling overhead, on top of having to deal with potential false dependencies.
Hardware-accelerated GPU scheduling
More recently, Microsoft introduced a new model called hardware-accelerated GPU scheduling. Using this model, hardware queues are directly exposed for a given context and the user mode driver (in this case, CUDA) is solely responsible for managing the work submissions and the dependencies between the work items. It removes the need for batching multiple kernel launches into a single submission, enabling you to adopt the same strategy as used in a native Linux driver where work submissions are almost instantaneous (Figure 6).
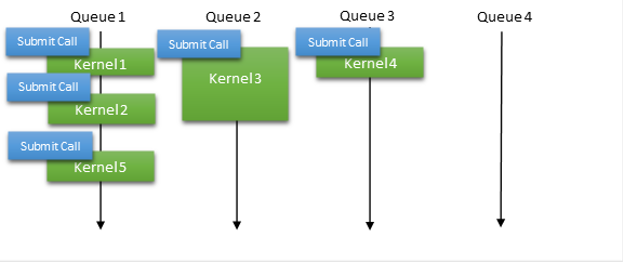
This hardware scheduling-based submission model removes the false dependency and avoids the need for buffering. It also reduces the overhead by offloading some of the OS scheduling tasks previously handled on the CPUs to the GPU.
Leveraging HW-accelerated GPU scheduling on WSL2
Why do these scheduling details matter? Native Windows applications were traditionally designed to hide the higher latency. However, launch latency was never a factor for native Linux applications, where the threshold at which latency affects performance was an order of magnitude smaller than the one on Windows.
When these same Linux applications run in WSL2, the launch latency becomes more prominent. Here, the benefits of hardware-accelerated GPU scheduling can offset the latency-induced performance loss, as CUDA adopts the same submission strategy followed on native Linux for both WSL2 and native Windows. We strongly recommend switching to hardware-accelerated GPU scheduling mode when running WSL2.
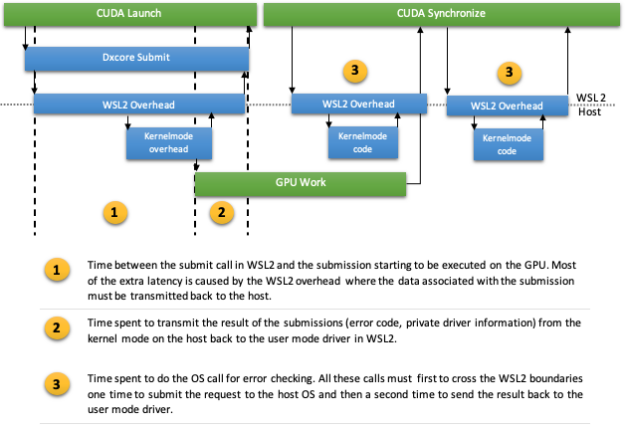
Even with hardware-accelerated GPU scheduling, submitting work to the GPU is still done with a call to the OS, just like in packet scheduling. Not only submission but, in some cases, synchronization might also have to make some OS calls for error detection. Each such call to the OS on WSL2 involves crossing the WSL2 boundary to reach the host kernel mode through VMBUS. This can quickly become the single bottleneck for the driver (Figure 7). Linux applications that are doing small batches of GPU work at a time may still not perform well.
Asynchronous submissions to reduce the launch latency
We found a solution to mitigate the extra launch latency on WSL through a change made by Microsoft to make the Submit call asynchronous. By leveraging this call, you can start overlapping other operations while the submission is happening and hide the extra WSL overhead in this way. Thanks to the new asynchronous nature of the submit call, the launch latency is now comparable to native Windows.
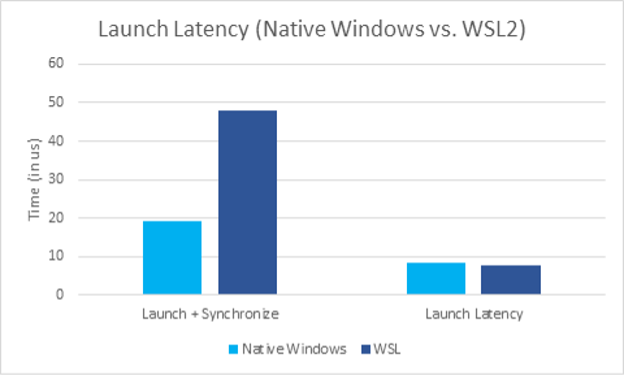
Despite the optimization made in the synchronization path, the total overhead of launching and synchronizing on a submission is still higher compared to native Windows. The VMBUS overhead at point 1 causes this, not the synchronization path itself (Figure 7). This effect can be seen in Figure 8, where we measure the overhead of a single launch, followed by synchronization. The extra latency induced by VMBUS is clearly visible.
Making the submission call asynchronous does not necessarily remove the launch latency cost altogether. Instead, it enables you to offset it by doing other operations at the same time. An application can pipeline multiple launches on a stream for instance, assuming that the kernel launches are long enough to cover the extra latency. In that case, this cost can be shadowed and designed to be visible only at the beginning of a long series of submissions.
In short, we have and will continue to improve and optimize performance on WSL2. Despite all the optimizations mentioned thus far, if applications are not pipelining enough workload on the GPU, or worse, if the workload is too small, a performance gap between native Linux and WSL2 will start to appear. This is also why comparisons between WSL2 and native Linux are challenging and vary widely from benchmark to benchmark.
Imagine that the application is pipelining enough work to shadow the latency overhead and keep the GPU busy during the entire lifetime of the application. With the current set of optimizations, chances are that the performance will be close to or even comparable with native Linux applications.
When the GPU workload submitted by an application is not long enough to overcome that latency, a performance gap between native Linux and WSL2 will start to appear. The gap is proportional to the difference between the overall latency and the size of the work pushed at one time.
This is also why, despite all the improvements made in this area, we will keep focusing on reducing this latency to bring it closer and closer to native Linux.
New allocation optimization
Another area of focus for us has been memory allocation. Unlike launch latency, which affects the performance for as long as the application is launching work on the GPU, memory allocations mostly affect the startup and loading and unloading phases of a program.
This does not mean that it is unimportant; far from it. Even if those operations are infrequent compared to just submitting work on the GPU, the associated driver overhead is usually an order of magnitude higher. The allocation of several megabytes at a time end up taking several milliseconds to complete.
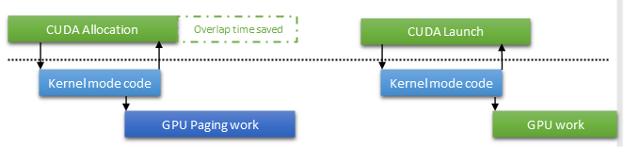
To optimize this path, one of our main approaches has been to enable asynchronous paging operation in CUDA. This capability has been available in the Windows Display Driver model for a while, but the CUDA driver never used it, until now. The main advantage of this strategy is that you can exit the allocation call and give control back to the user code. You don’t have to wait for an expensive GPU operation to complete, for example, updating the page table. Instead, the wait is postponed to the next operation that references the allocation.
Not only does this improve the overlap between the CPU and GPU work, but it can also eliminate the wait altogether. If the paging operation completes early enough, the CUDA driver can avoid issuing an OS call to wait on the paging operation by snooping a mapped fence value. On WSL2, this is particularly important. Anytime that you avoid calling into the host kernel mode, you also avoid the VMBUS overhead.
Are we there yet?
We have come a long way when it comes to WSL2 performance over the past months, and we are now seeing results comparable or close to native Linux for many benchmarks. This doesn’t mean that we have reached our goal and that we will stop optimizing the driver. Not at all!
First, future optimization in hardware scheduling, currently being looked at by Microsoft, might allow us to bring the launch overhead to a minimum. In the meantime, until those features are fully developed, we will keep optimizing the CUDA driver on WSL, with recommendations for native Windows as well.
Second, we will focus on fast and efficient memory allocation through some special form of memory copy. We will also soon start looking at better multi-GPU features and optimizations on WSL2 to enable even more intensive workload to run fast.
WSL2 is a fully supported platform for NVIDIA, and it will be given the same feature offerings and performance focus that CUDA strives for all its other supported platforms. It is our intent to make WSL2 performance better and suitable for development. We will also make this into a CUDA platform that is attractive for every use case, with performance as close as possible to any native Linux system.
Last, but not least, we heartily thank the developer community that has been rapidly adopting GPU acceleration in the WSL2 preview, reporting issues, and providing feedback continuously over the past year. You have helped us uncover potential issues and make big strides on performance by sharing with us performance use cases that we might have missed otherwise. Without your unwavering support, GPU acceleration on WSL2 would not be where it is today. We look forward to engaging with the community further as we work on achieving future milestones for CUDA on WSL2.
To access the driver installers and documentation, register for the NVIDIA Developer Program and Microsoft Windows Insider Program.
The following resources contain valuable information to aid you on how CUDA works with WSL2, including how to get started with running applications, and deep learning containers:
- CUDA on WSL page for downloads
- CUDA on WSL User Guide
- Announcing CUDA on Windows Subsystem for Linux 2
- GPU accelerated ML training inside the Windows Subsystem for Linux
- What is WSL?
- Run RAPIDS on Microsoft Windows 10 using WSL 2 — The Windows Subsystem for Linux
We encourage everyone to use our forum and share their experience with the larger WSL community.
