Labellio is the world’s easiest deep learning web service for computer vision. It aims to provide a deep learning environment for image data where non-experts in deep learning can experiment with their ideas for image classification applications. Watch our video embedded here to see how easy it is.
The challenges in deep learning today are not just in configuring hyperparameters or designing a suitable neural network structure; they are also in knowing how to prepare good training data to fine-tune a well-known working classification model, and in knowing how to set up a computing environment without hassle. Labellio aims to address these problems by supporting the deep learning workflow from beginning to end.
The Labellio training data collector lets users upload images, or downloads images from the internet from specified URL lists or keyword searches on external services like Flickr and Bing. While some users have their own domain-specific training data in hand already, others don’t. Labellio’s data ingestion capabilities help both types of users start building their own deep learning models immediately. It is extremely important to assign the correct class to each training image to build a more accurate classification model, so Labellio’s labelling capability helps users cleanse input training data.
Labellio helps users build and manage multiple classification models. Creating a classification model is typically not just a one-time operation; you need trial and error to develop the most accurate model by replacing some of the training data.
When it comes to using the models you train with Labellio, users have varying requirements, ranging from tight integration in a local data center to a loosely coupled web API architecture. Therefore Labellio does not provide a prediction API; instead, we provide an Amazon Web Services AMI, Docker containers, and a python library that enable using trained models anywhere you want from day one (see more details in our blog posts about how to use the AMI and Docker images to load Labellio’s model data).
These features make Labellio the easiest deep learning environment because it lets you focus on your application problem rather than spending unnecessary time and money to figure out how to run deep learning.
While there is a lot of deep learning software available, Labellio had more than 350 new users signed up and created nearly 400 models during the first week after its beta release on June 30th. This indicates many people are still looking for better deep learning environments. Almost half of the new users uploaded their own datasets, and the other half used available online datasets. While most users created models with less than 10 classes, some created models with hundreds of classes. Example user applications include a model to classify a tiny difference among various types of mushrooms, and models to recognize anime characters’ faces.
Labeling Images with Labellio
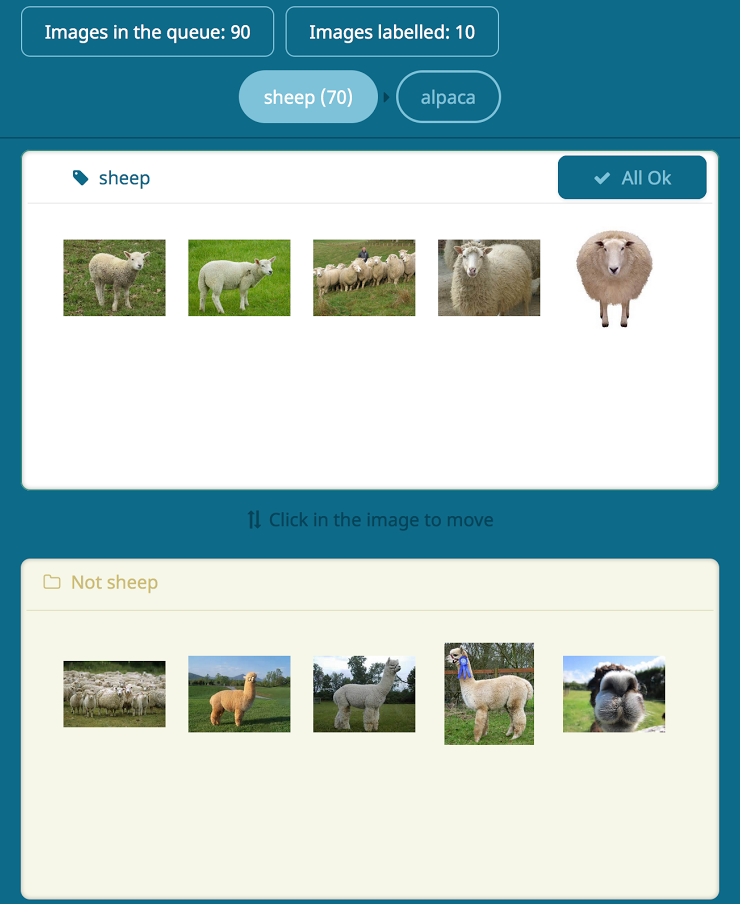
The most interesting aspect of Labellio is its labelling capability, which uses real-time AI support to make it easy for users to sort and label training data (Figure 1).
A correct dataset is crucial to training an artificial intelligence model, so you need to prepare the right dataset to express your problem. Before Labellio, there was not a good tool available to help with this task, besides using your OS file browser to look at images and drag and drop them one by one into category folders. Labellio’s labelling system helps you label efficiently by learning how you label data and immediately suggesting how to label the rest of the unlabelled data.
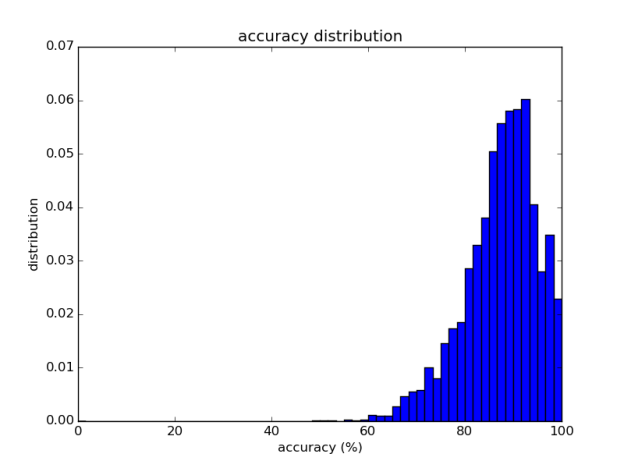
This is made possible by the combination of an online classifier and deep-learning-based feature extraction. Because deep learning model training takes some time to iteratively adjust neural network parameters, we defer it until it is really necessary; instead, to respond to users’ labelling work interactively, we employ another approach with multiclass Adaptive Regularization of Weights (AROW), an online training algorithm, by feeding high-dimensional feature vectors extracted from a prebuilt deep learning model. This improves not just CPU/GPU resource usage, but also interactivity reduces the human user’s burden of labelling each one of the images. This would not have been possible without Labellio’s highly scalable architecture (described next) that allows us to utilize different computing resources from CPU image preprocessing to batch-style GPU deep learning. This approach works very well, and the benchmark in Figure 2 shows the accuracy of our system over the Caltech 101 dataset.
Labellio Architecture
Deep learning requires dense numerical computing resources, and GPUs make our system an order of magnitude faster. But it is very hard to support many users running different deep learning training and prediction tasks in one place. Let me share some key points of Labellio’s architecture that maximizes the use of the GPU for as many users as possible.
The Labellio architecture is based on the modern distributed computing architectural concept of microservices, with some modification to achieve maximal utilization of GPU resources. At the core of Labellio is a messaging bus for deep learning training and classification tasks, which launches GPU cloud instances on demand. Running behind the web interface and API layer are a number of components including data collectors, dataset builders, model trainer controllers, metadata databases, image preprocessors, online classifiers and GPU-based trainers and predictors. These components all run inside docker containers. Each component communicates with the others mainly through the messaging bus to maximize the computing resources of CPU, GPU and network, and share data using object storage as well as RDBMS.
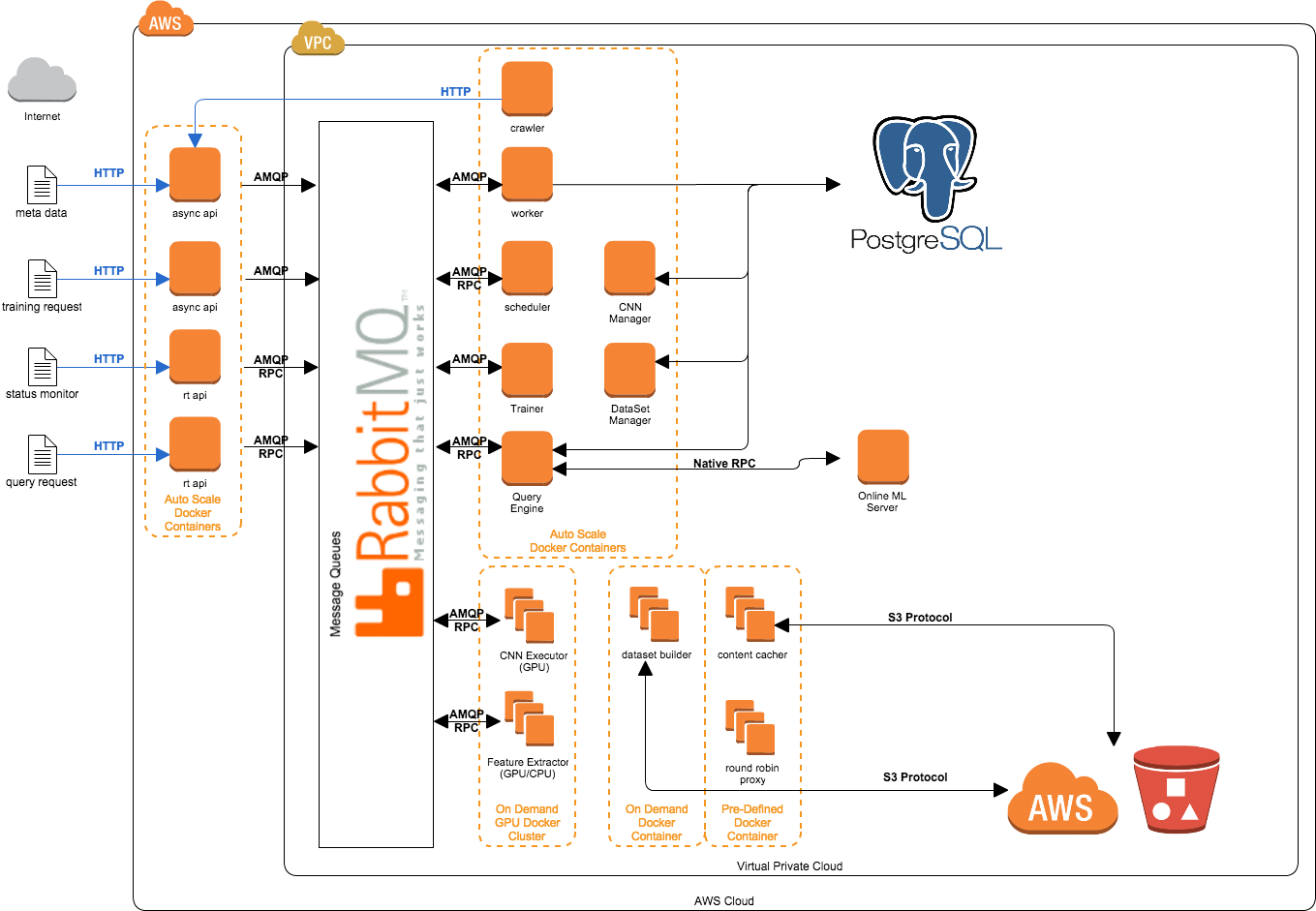
Because the components are stateless, share data via shared storage, and communicate via the messaging bus, the Labellio system is fairly scalable and fault tolerant. We have experienced some critical problems such as failure of individual machines (e.g. AWS instances), but the service kept running thanks to this architecture. The architecture also maintains service during large usage spikes, such as on the service release date, when more than a hundred users immediately signed up and started using the service.
GPU tasks such as training and prediction are queued in the bus, and the first available GPU container receives and processes the message. Especially when it comes to prediction, since it is best to keep using the same prediction model to perform feature extraction and classification over multiple data instead of switching between models, the messages are sent to separate queues per prediction model and GPU containers buffer messages instead of
consuming each single message immediately. This improves the system’s throughput by an order of magnitude compared to switching back and forth between prediction models on every prediction request.
Try Labellio Today
This blog post briefly introduced Labellio’s scalable architecture for efficient GPU deep learning. After working with many enterprise customers, it became clear to us that deep learning technology should be provided in the cloud space to deliver the latest technology to as many users as possible. Labellio enabled more people to develop new ideas for deep learning applications, from mushroom classification to content moderation on social media sites.
Without Labellio’s scalable architecture, we could not have served the latest AI technology to hundreds of users in a week. We know there is still a lot of room to improve on this architecture, from speeding up model training using multiple GPUs in parallel, or even running on multiple machines by updating parameters loosely, to reducing the prediction latency and increasing prediction throughput. Beyond the computing resource utilization, the web service could serve not just as a deep learning training environment, but also enable the community to exchange ideas, share models and training datasets as well as even learning results for academic purposes. Labellio has a strong future for everyone who benefits from deep learning technology. Try Labellio today!