
Algorithms are commonplace in the world of data science and machine learning. Algorithms power social media applications, Google search results, banking systems and plenty more. Therefore, it’s paramount that Data Scientists and machine-learning practitioners have an intuition for analyzing, designing, and implementing algorithms.
Efficient algorithms have saved companies millions of dollars and reduced memory and energy consumption when applied to large-scale computational tasks. This article introduces a straightforward algorithm, Insertion Sort.
Although knowing how to implement algorithms is essential, this article also includes details of the insertion algorithm that Data Scientists should consider when selecting for utilization.Therefore, this article mentions factors such as algorithm complexity, performance, analysis, explanation, and utilization.

Why?
It’s important to remember why Data Scientists should study data structures and algorithms before going into explanation and implementation.
Data Science and ML libraries and packages abstract the complexity of commonly used algorithms. Furthermore, algorithms that take 100s of lines to code and some logical deduction are reduced to simple method invocations due to abstraction. This doesn’t relinquish the requirement for Data Scientists to study algorithm development and data structures.
When given a collection of pre-built algorithms to use, determining which algorithm is best for the situation requires understanding the fundamental algorithms in terms of parameters, performances, restrictions, and robustness. Data Scientists can learn all of this information after analyzing and, in some cases, re-implementing algorithms.
The selection of correct problem-specific algorithms and the capacity to troubleshoot algorithms are two of the most significant advantages of algorithm understanding.
K-Means, BIRCH and Mean Shift are all commonly used clustering algorithms, and by no means are Data Scientists possessing the knowledge to implement these algorithms from scratch. Still, there is a necessity that Data Scientists understand the properties of each algorithm and their suitability to specific datasets.
For example, centroid based algorithms are favorable for high-density datasets where clusters can be clearly defined. In contrast, density-based algorithms such as DBSCAN(Density-based spatial clustering of application with Noise) are preferred when dealing with a noisy dataset.
In the context of sorting algorithms, Data Scientists come across data lakes and databases where traversing through elements to identify relationships is more efficient if the containing data is sorted.
Identifying library subroutines suitable for the dataset requires an understanding of various sorting algorithms preferred data structure types. Quicksort algorithms are favorable when working with arrays, but if data is presented as linked-list, then merge sort is more performant, especially in the case of a large dataset. Still, both use the divide and conquer strategy to sort data.
Background
What’s a sorting algorithm?
The Sorting Problem is a well-known programming problem faced by Data Scientists and other software engineers. The primary purpose of the sorting problem is to arrange a set of objects in ascending or descending order. Sorting algorithms are sequential instructions executed to reorder elements within a list efficiently or array into the desired ordering.
What’s the purpose of sorting?
In the data realm, the structured organization of elements within a dataset enables the efficient traversing and quick lookup of specific elements or groups. At a macro level, applications built with efficient algorithms translate to simplicity introduced into our lives, such as navigation systems and search engines.
What’s insertion sort?
Insertion sort algorithm involves the sorted list created based on an iterative comparison of each element in the list with its adjacent element.
An index pointing at the current element indicates the position of the sort. At the beginning of the sort (index=0), the current value is compared to the adjacent value to the left. If the value is greater than the current value, no modifications are made to the list; this is also the case if the adjacent value and the current value are the same numbers.
However, if the adjacent value to the left of the current value is lesser, then the adjacent value position is moved to the left, and only stops moving to the left if the value to the left of it is lesser.
The diagram illustrates the procedures taken in the insertion algorithm on an unsorted list. The list in the diagram below is sorted in ascending order (lowest to highest).
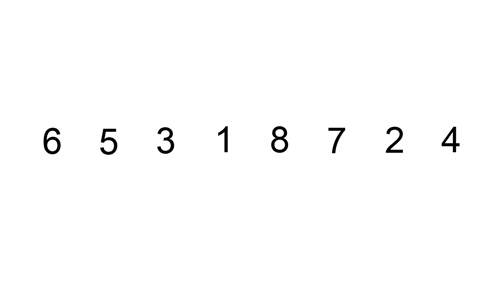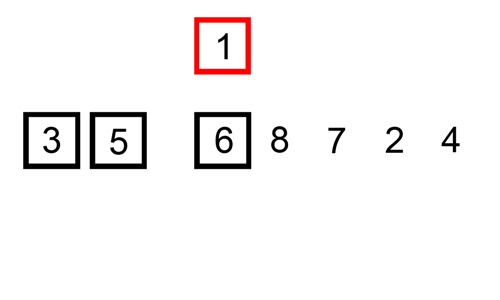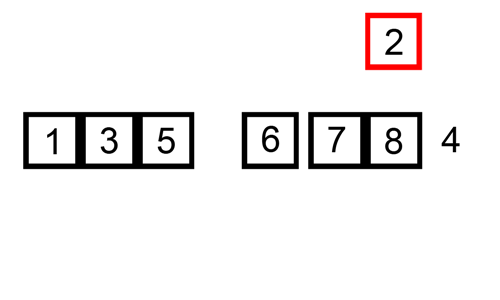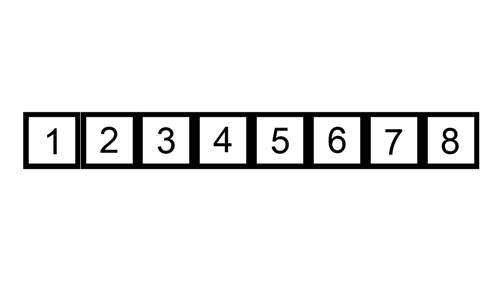
Algorithm Steps and Implementation (Python and JavaScript)
Steps
To order a list of elements in ascending order, the Insertion Sort algorithm requires the following operations:
- Begin with a list of unsorted elements.
- Iterate through the list of unsorted elements, from the first item to last.
- The current element is compared to the elements in all preceding positions to the left in each step.
- If the current element is less than any of the previously listed elements, it is moved one position to the left.
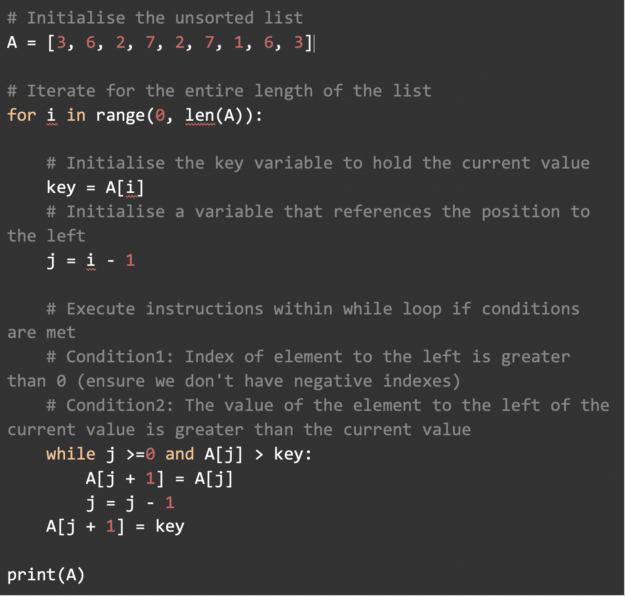
Implementation in Python
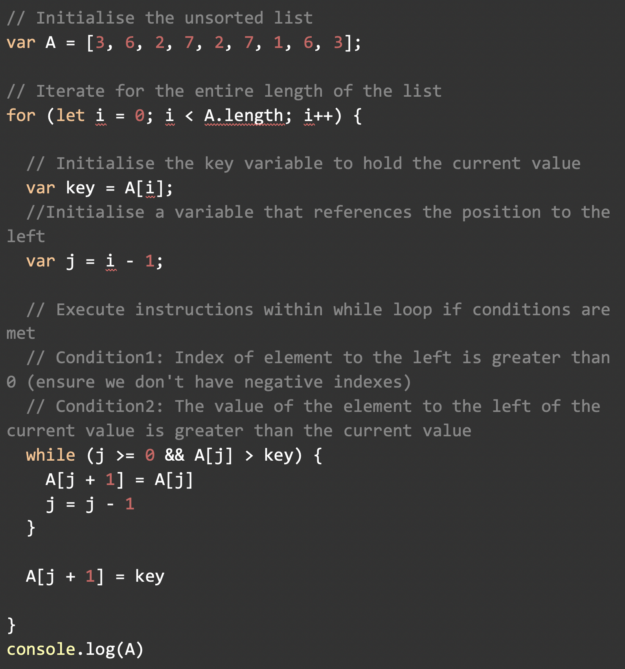
Implementation in JavaScript
Performance and Complexity
In the realm of computer science, ‘Big O notation is a strategy for measuring algorithm complexity. We won’t get too technical with Big O notation here. Still, it’s worth noting that computer scientists use this mathematical symbol to quantify algorithms according to their time and space requirements.
The Big O notation is a function that is defined in terms of the input. The letter ‘n’ often represents the size of the input to the function. Simply kept, n represents the number of elements in a list. In different scenarios, practitioners care about the worst-case, best-case, or average complexity of a function.
The worst-case (and average-case) complexity of the insertion sort algorithm is O(n²). Meaning that, in the worst case, the time taken to sort a list is proportional to the square of the number of elements in the list.
The best-case time complexity of insertion sort algorithm is O(n) time complexity. Meaning that the time taken to sort a list is proportional to the number of elements in the list; this is the case when the list is already in the correct order. There’s only one iteration in this case since the inner loop operation is trivial when the list is already in order.
Insertion sort is frequently used to arrange small lists. On the other hand, Insertion sort isn’t the most efficient method for handling large lists with numerous elements. Notably, the insertion sort algorithm is preferred when working with a linked list. And although the algorithm can be applied to data structured in an array, other sorting algorithms such as quicksort.
Summary
One of the simplest sorting methods is insertion sort, which involves building up a sorted list one element at a time. By inserting each unexamined element into the sorted list between elements that are less than it and greater than it. As demonstrated in this article, it’s a simple algorithm to grasp and apply in many languages.
By clearly describing the insertion sort algorithm, accompanied by a step-by-step breakdown of the algorithmic procedures involved. Data Scientists are better equipped to implement the insertion sort algorithm and explore other comparable sorting algorithms such as quicksort and bubble sort, and so on.
Algorithms may be a touchy subject for many Data Scientists. It may be due to the complexity of the topic. The word “algorithm” is sometimes associated with complexity. With the appropriate tools, training, and time, even the most complicated algorithms are simple to understand when you have enough time, information, and resources. Algorithms are fundamental tools used in data science and cannot be ignored.
