UMAP is a popular dimension reduction algorithm used in fields like bioinformatics, NLP topic modeling, and ML preprocessing. It works by creating a k-nearest neighbors (k-NN) graph, which is known in literature as an all-neighbors graph, to build a fuzzy topological representation of the data, which is used to embed high-dimensional data into lower dimensions.
RAPIDS cuML already contained an accelerated UMAP, which provided significant speed improvements over the original CPU-based UMAP. As we demonstrate in this post, there was still room for improvement.
In this post, we explore how to use the new features introduced in RAPIDS cuML 24.10. We also dive into the details of the nn-descent algorithm and the batching process. Finally, we share benchmark results to highlight possible performance gains. By the end of this post, we hope you are excited about the benefits that RAPIDS’ faster and scalable UMAP can provide.
Challenges
One challenge we faced is that the all-neighbors graph-building phase takes a long time, especially in comparison to the other steps in the UMAP algorithm.
cuML UMAP initially used only a brute-force approach to compute the all-neighbors graph, which is usually referred to in literature as an all-neighbors graph because it involves an exhaustive vector search over all vectors in the dataset.
Because it exhaustively computes distances for every pair of vectors in the dataset, brute force tends to have poor scaling. Thus, as the number of vectors in the dataset grows, the amount of time spent in this step grows quadratically (number of vectors to the power of 2) as compared to all the other steps in UMAP.
Figure 1 shows the proportion of time spent in the all-neighbors graph construction for several popular datasets. The proportion spent in all-neighbors graph construction quickly becomes 99% and higher at the 1M and 5M vector scales.

The second challenge we faced is that, like many algorithms in cuML, the entire dataset had to fit into the memory of the GPU.
Handling large datasets, such as those that are hundreds of GB in size, can be especially challenging when only a consumer-level NVIDIA RTX GPU is available for processing. Even though the NVIDIA H100 GPU offers 80 GB of memory, this may not be sufficient for an 80-GB dataset because algorithms like UMAP require many little temporary memory allocations that can add up over the course of the algorithm.
Accelerating and scaling UMAP
We have solved these challenges with a novel batched approximate nearest neighbor (ANN) algorithm. While the general approach can apply to any algorithm capability of searching for nearest neighbors, we used a GPU-accelerated version of a fast algorithm called nearest neighbors descent (nn-descent) from the RAPIDS cuVS library, which is great for all-neighbors graph construction.
ANN algorithms accelerate the all-neighbors graph-building process by trading off quality for speed. In general, approximate methods aim to reduce the number of distances that need to be computed to find the nearest neighbors. As this algorithm can compute a single all-neighbors graph in pieces, we could place larger datasets in RAM memory and pull only what we need into the GPU memory when we needed it.
As we demonstrate in this post, our new approach scales UMAP in RAPIDS cuML 24.10 to massive datasets at lightspeed. What’s better is that it’s enabled by default, so you don’t have to make any changes to your code to reap the benefits!
| Matrix size | Running UMAP with brute-force | Running UMAP with nn-descent |
| 1M x 960 | 214.4s | 9.9s (21.6x speedup) |
| 8M x 384 | 2191.3s | 34.0s (54.4x speedup) |
| 10M x 96 | 2170.8s | 53.4s (40.6x speedup) |
| 20M x 384 | 38350.7s | 122.9 (312x speedup) |
| 59M x 768 | Error: out of memory | 575.1 |
Table 1 shows that UMAP can now run with datasets that don’t fit on the device (50M, 768 is 153 GB). Speedup gain increases for large datasets. What used to take 10 hours to run on the GPU can be run in 2 minutes.
Using faster and scalable UMAP in RAPIDS cuML
As mentioned earlier, no code changes are required as of cuML 24.10 to take advantage of this new feature.
However, for more control, the UMAP estimator now accepts two more parameters during initialization:
build_algo: Algorithm to build the all-neighbors graph. It can be one of the following three values:auto: Decides to build with brute force or nn-descent during runtime depending on the dataset size (>50K data samples uses nn-descent). Default value.brute_force_knn: Builds all-neighbors graph using brute force.nn_descent: Builds all-neighbors graph using nn-descent.
build_kwds: Python dictionary type for passing parameters related to all-neighbors graph building, with the following parameters:nnd_graph_degree: Graph degree when building k-nn with nn-descent. Default:64.nnd_intermediate_graph_degree: Intermediate graph degree when building k-NN with nn-descent. Default:128.nnd_max_iterations: Maximum number of iterations to run nn-descent. Default:20.nnd_termination_threshold: Termination threshold to early stop nn-descent iterations. Default:0.0001.nnd_return_distances: Whether to return distances from nn-descent. This should be set to true to use nn-descent with UMAP. Default:True.nnd_n_clusters: Number of clusters to use for the batching approach. A larger number of clusters reduces memory usage when running with larger datasets. Default:2.nnd_do_batch: Should be set toTruefor batching. Default:False.
You can also choose to put the data on the host instead of putting the entire data on the device using the data_on_host option which defaults to False. This is only compatible with build_algo=”nn_descent” and is not supported for building with the brute-force algorithm.
We recommend that you put data on the host to get the most out of our batching algorithm for large datasets.
from cuml.manifold.umap import UMAP
data = generate_data()
# running default. Runs with NN Descent if data has more than 50K points
umap = UMAP(n_neighbors=16)
emb = umap.fit_transform(data)
# explicitly set build algo. Runs with this regardless of the data size. Data can be put on host
umap = UMAP(n_neighbors=16, build_algo="nn_descent", build_kwds={"nnd_graph_degree": 32})
emb = umap.fit_transform(data, data_on_host=True)
# batching NN Descent with 4 clusters
umap = UMAP(n_neighbors=16, build_algo="nn_descent", build_kwds={"nnd_do_batch": True, "nnd_n_clusters": 4})
emb = umap.fit_transform(data, data_on_host=True)
Why approximate nearest neighbors?
Brute-force is an exact and exhaustive algorithm. In contrast, ANN algorithms don’t guarantee finding the exact closest neighbors but they do efficiently navigate the search space to construct an approximation to the nearest neighbors much faster, trading off search speed for accuracy.
Nearest neighbors descent (nn-descent) is an ANN algorithm that can directly approximate an all-neighbors graph. The algorithm begins by randomly initializing nearest neighbors for each data point before iteratively improving nearest neighbor approximations by exploring each point’s neighbors’ neighbors.
As noted in the original paper, nn-descent “typically converges to above 90% recall with each point comparing only to several percent of the whole dataset on average”. In short, ANN algorithms generally find clever ways to reduce the number of distances that must be computed.
We used nn-descent from the NVIDIA cuVS library to construct all-neighbors graphs for UMAP. For large datasets, this method accelerates the all-neighbors graph-building process by hundreds of times, while still maintaining functionally equivalent results.
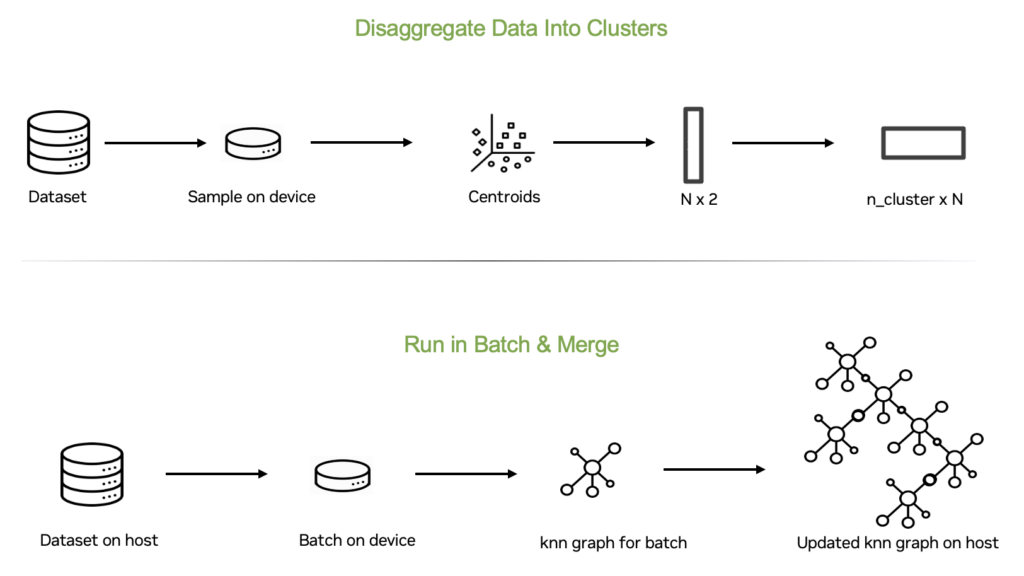
Using batching to scale all-neighbors graph construction
Managing a large dataset by keeping it on the host and processing it in batches on the device may seem straightforward. However, a key challenge when building k-NN subgraphs with a certain subset of the dataset is that data samples with similar indices are not guaranteed to be close in distance. This means you can’t simply slice the dataset into batches.
We solved this problem with a batching approach that is inspired by literature on the popular DiskANN algorithm. We first perform a balanced k-means clustering on a subsample of the dataset to extract centroids for a predefined number of clusters. Then, using this information, we partition the dataset into batches based on their closest clusters.
This approach ensures that data points in each batch are more likely to be closed to each other, improving the likelihood that nearest neighbors are found within the same batch. The remaining part of this section explains each step of the batching process in detail:
- Extract the cluster centroids
- Find data points for each cluster
- Build subgraphs of cluster data points
- Merge the k-NN subgraph with the global all-neighbors graph
Extract the cluster centroids
We first extracted the cluster centroids from the dataset. Because we assumed that a large dataset doesn’t fit on a GPU device, we left the data in host memory and randomly subsampled a set of points to ensure that the subset fits in the GPU device memory. Usually, 10% of the dataset is a large enough subsample to find a usable set of centroids.
Using the nnd_n_clusters parameters provided by the user, we ran balanced k-means on the sampled subset to identify the specified number of cluster centers.
Find data points for each cluster
Next, we determined the top two closest cluster centers for each data point and then inverted the indices to find the data points that belonged to each cluster. This process resulted in each data point being assigned to two separate clusters.
This approach ensures that there is overlap in the neighborhoods for each cluster, increasing the likelihood that the final neighborhoods will include at least an acceptable number of the neighbors that we might have expected if we had computed the exact results.
Build subgraphs of cluster data points
When we knew the data points that belonged to each cluster, we proceeded to iteratively build subgraphs on the data points for each cluster. This means that for each cluster, we gathered the data points for that cluster in the GPU’s memory and ran NN-descent on this subset to construct the all-neighbors graph for that cluster.
Merge the k-NN subgraph with the global all-neighbors graph
After the all-neighbors graph for a cluster was built, we merged this k-NN subgraph with the global all-neighbors graph. To do this efficiently, we used a custom CUDA kernel that merged the two subgraphs without allocating additional device memory.
After iterating through all the clusters in this way, the global all-neighbors graph was returned as the final result. As this graph is generally much smaller than the input dataset, it could be copied safely into the GPU’s memory space even when the input dataset was much too large to fit.
Performance improvements
We evaluated the performance impact of using cuML UMAP and the new batched all-neighbors graph construction method.
For these experiments, we used an NVIDIA H100 GPU with 80 GB of memory. These comparisons are against the GPU version of UMAP, and so these speedups are not from a CPU-to-GPU comparison but improvements to the existing GPU implementation.
Figure 2 illustrates the total runtime of UMAP in cuML, comparing the new NN-descent strategy with the brute-force all-neighbors graph construction strategy. For a dataset with 20M points and 384 dimensions, we gained 311x speedup using NN-descent, reducing UMAP’s total runtime on the GPU from 10 hours to just 2 minutes!
Figure 2 is in log scale because the speedups are so high.

We also observe that the UMAP algorithm for a dataset as large as 50M points with 768 dimensions is now able to be run on the GPU, even though this dataset is 150 GB– much larger than the amount of memory in the GPU.
This feat is achieved with the batching algorithm by partitioning the dataset into five clusters. In contrast, the brute-force all-neighbors graph building algorithm runs out of memory because it attempts to load the entire dataset onto the device at one time.
While this new technique can improve UMAP’s speed and scalability, we need to maintain quality to ensure the low-dimensional embeddings can be used effectively. To measure quality, we turn to the trustworthiness score. Trustworthiness is a score between 0 and 1 that indicates how well the local nearest neighbors structure is retained in the low-dimensional UMAP embedded space as compared to the nearest neighbors of the original vectors before running UMAP. In this metric, higher is better.
Figure 3 shows that these significant speedups and benefits come without sacrificing the quality of the UMAP embedding results. We can see that there are no significant changes in the trustworthiness score as we increase the numbers of batches.

Conclusion
We are excited to share these performance results with the data science community. Given UMAP’s popularity across various domains, we believe that these new features in RAPIDS cuML will significantly accelerate workflows and help computational scientists uncover insights that are only possible by processing large-scale datasets on the GPU.
To get started with cuML and install the conda and pip packages, as well as ready-to-go Docker containers, see the RAPIDS Installation Guide.
