In recent years, transformers have emerged as a powerful deep neural network architecture that has been proven to beat the state of the art in many application domains, such as natural language processing (NLP) and computer vision.
This post uncovers how you can achieve maximum accuracy with the fastest training time possible when fine-tuning transformers. We demonstrate how the cuML support vector machine (SVM) algorithm, from the RAPIDS Machine Learning library, can dramatically accelerate this process. CuML SVM on GPU is 500x faster than the CPU-based implementation. This approach uses SVM heads instead of the conventional multi-layer perceptron (MLP) head, making it possible to fine-tune with precision and ease.
What is fine-tuning and why do you need it?
A transformer is a deep learning model consisting of many multi-head, self-attention, and feedforward fully connected layers. It is mainly used for sequence-to-sequence tasks, including NLP tasks, such as machine translation and question-answering, and computer vision tasks, such as object detection and more.
Training a transformer from scratch is a compute-intensive process, often taking days or even weeks. In practice, fine-tuning is the most efficient way of applying pretrained transformers to new tasks, thereby reducing training time.
MLP head for fine-tuning transformers
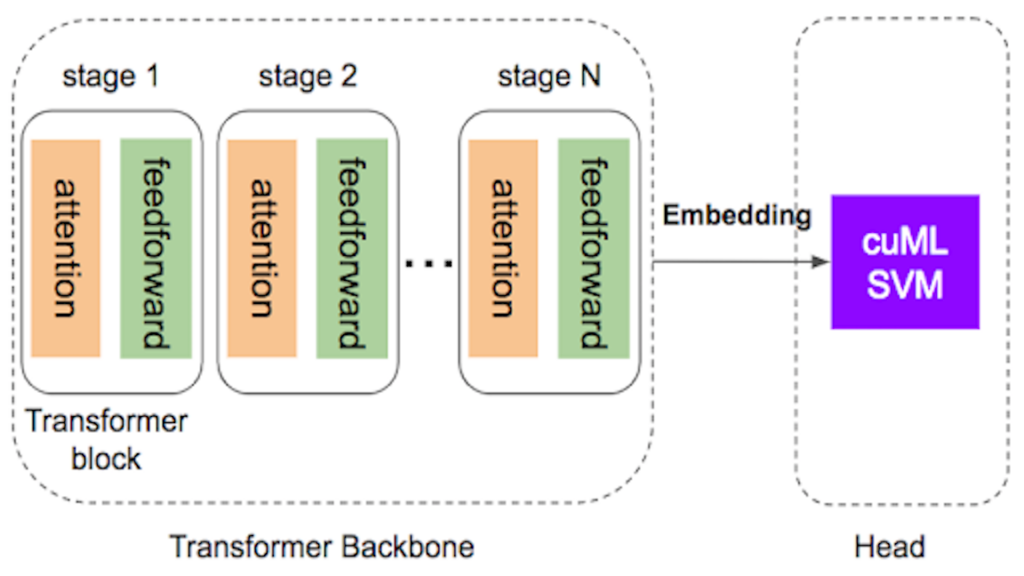
As shown in Figure 1, transformers have two distinct components:
- The backbone, which contains multiple blocks of self-attention and feedforward layers.
- The head, where final predictions take place for either classification or regression tasks.
During fine-tuning, the backbone network of the transformer is frozen while only the lightweight head module is trained for the new task. The most common choice for the head module is a multi-layer perceptron (MLP) for both classification and regression tasks.
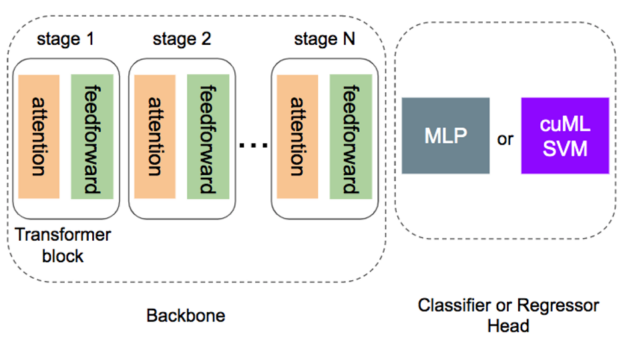
As it turns out, implementing and tuning a MLP can be much harder than it looks. Why is that?
- There are multiple hyperparameters to tune: number of layers, dropout, learning rate, regularization, types of optimizers, and more. Choosing which hyperparameter to tune is dependent on the problem that you are trying to solve. For example, standard techniques such as dropout and batchnorm could lead to performance degradation for regression problems.
- Additional efforts must be made to prevent overfitting. The transformer’s output is often a long embedding vector, with a length ranging from hundreds to thousands. Overfitting is common when the training data size is not large enough.
- Performance in terms of execution time is typically not optimized. Users must write boilerplate code for data processing and training. Batch generation and data movement from CPU to GPU can also become a bottleneck for performance.
Advantages of SVM heads for fine-tuning transformers
Support vector machines (SVMs) are one of the most popular supervised learning methods and most potent when there are meaningful, predictive features available. This is especially true with high-dimensional data due to SVM’s robustness against overfitting.
Yet, data scientists are sometimes hesitant to try SVMs for several reasons:
- It requires handcraft feature engineering that can be difficult to implement.
- SVMs are traditionally slow.
RAPIDS cuML revives interest in revisiting this classic model by providing a speedup of up to 500x on GPU. With RAPIDS cuML, SVM is gaining popularity again in the data science community.
For example, RAPIDS cuML SVM notebooks have been frequently used in several Kaggle competitions:
As transformers have already learned to extract meaningful representations in the form of long embedding vectors, cuML SVM is an ideal candidate for the head classifier or regressor.
When compared to the MLP head, cuML SVM has the following advantages:
- Easy to tune. In practice, we have found in most instances that tuning just one parameter, C, is enough for SVM.
- Speed. cuML moves all data to the GPU at once, before processing on the GPU.
- Diversity. The predictions of SVM are statistically different from the MLP predictions, rendering it useful in ensembles.
- Simple API. cuML SVM API provides scikit-learn style fit and predict functions.
Case study: PetFinder.my Pawpularity Contest
This proposed fine-tuning methodology with SVM heads applies to both NLP and computer vision tasks. To demonstrate this, we looked at the PetFinder.my Pawpularity Contest, a Kaggle data science competition that predicted the popularity of shelter pets based on their photos.
The dataset used for this project consists of 10,000 hand-labeled images, each with a target pawpularity that we aimed to predict. With pawpularity values ranging from 0 to 100, we used regression to solve this problem.
As there are only 10,000 labeled images, it is impractical to train a deep neural network to achieve high accuracy from scratch. Instead, we approached this by using a pretrained swin transformer backbone and then fine-tuning it with the labeled pet images.
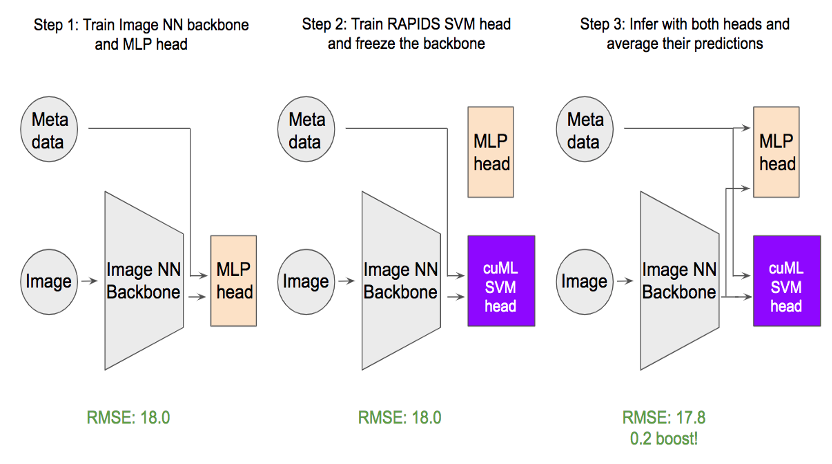
As shown in Figure 2, our approach requires three steps:
- First, a regression head using MLP is added to the backbone swin transformer, and the backbone and head are fine tuned. One interesting finding is that the binary cross entropy loss outperforms the common mean square error loss (MSE) due to the distribution of the target.
- Next, the backbone is frozen, and the MLP head is replaced with the cuML SVM head. The SVM head is then trained with the regular MSE loss.
- To achieve the best prediction accuracy, we averaged the MLP head and SVM head. The evaluation metric root means that square error is optimized going from 18 to 17.8, which is significant for this dataset.
It is worth noting that steps 1 and 3 are optional and have been implemented here to optimize the model’s score for this competition. Step 2 alone is the most common scenario for fine-tuning. For this reason, we measured the run time at step 2 and compared three options: cuML SVM (GPU), sklearn SVM (CPU), and PyTorchMLP (GPU). The results are shown in Figure 3.
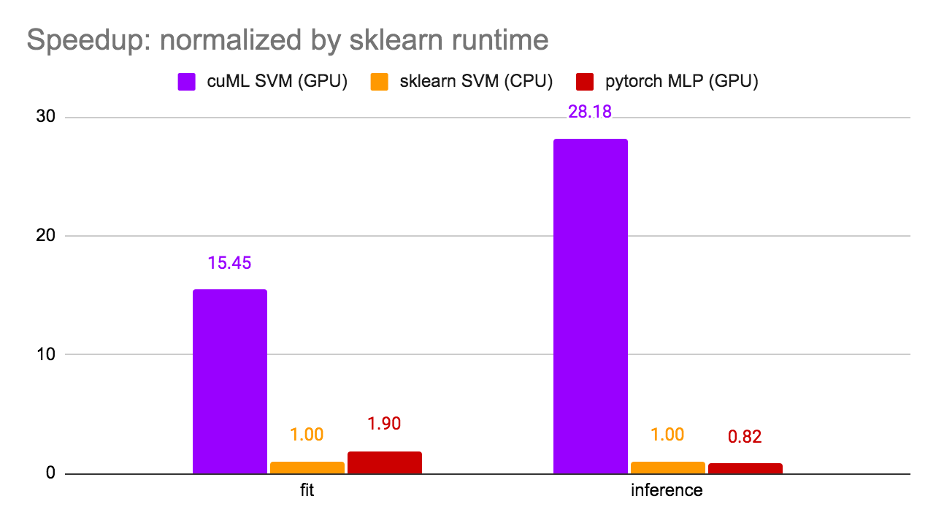
The runtime is normalized by sklearn SVM and cuML SVM achieved 15x speedup for training and 28.18x speedup for inference. It is noteworthy that cuML SVM is faster than PyTorch MLP due to high GPU utilization. The notebook can be found on Kaggle.
Key takeaways on transformer fine-tuning
Transformers are revolutionary deep learning models, but training them is time-consuming. Fast fine-tuning of transformers on a GPU can benefit many applications by providing significant speedup. RAPIDS cuML SVM can also be used as a drop-in replacement of the classic MLP head, as it is both faster and more accurate.
GPU acceleration infuses new energy into classic ML models like SVM. With RAPIDS, it is possible to combine the best of the two worlds: classic machine learning (ML) models and cutting-edge deep learning (DL) models. In RAPIDS cuML, you will find more lightning-fast and easy-to-use models.
Postscript
At the time of writing and editing this post, the PetFinder.my Pawpularity Contest concluded. NVIDIA KGMON Gilberto Titericz won first place by using RAPIDS SVM. His winning solution was to concentrate embeddings from transformers and other deep CNNs, and use RAPIDS SVM as the regression head. For more information, see his winning solution write-up.

