
Automatic speech recognition (ASR) research generally focuses on high-resource languages such as English, which is supported by hundreds of thousands of hours of speech. Recent literature has renewed focus on more complex languages, such as Japanese. Like other Asian languages, Japanese has a vast base character set (upwards of 3,000 unique characters are used in common vernacular), and poses unique challenges, such as multiple word order.

This post discusses recent work that improved both accuracy and speed for Japanese language ASR. First, we improved Conformer, a state-of-the-art ASR neural network architecture, to achieve a significant improvement in training and inferencing speed without accuracy loss. Second, we enhanced a pure and deep convolutional network with a multiple-head self attention mechanism for enriching the learning of global contextual representations of the input speech waves.
Deep sparse conformer for speech recognition
Conformer is a neural network architecture widely used in the ASR systems of numerous languages and has achieved high levels of accuracy. However, Conformer is relatively slow at both training and inferencing because it uses multi-head self-attention with a time/memory complexity of quadratic to the length of input audio waves.
This prevents its efficient processing of long audio sequences since relatively high memory footprints are required during training and inferencing. These motivate the usage of sparse attention for efficient Conformer constructing. In addition, with sparse attention and relatively low memory cost, we are able to build a deeper network that can process long sequences fed with large-scale speech datasets.
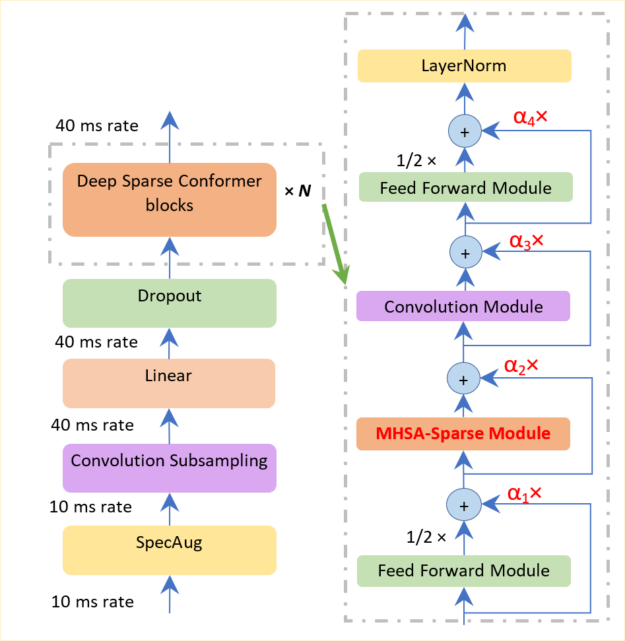
As depicted in Figure 1, we improved the Conformer long-sequence representation ability in two directions: sparser and deeper. We used a ranking criteria to only select a small scale of dominant queries instead of the whole query set to save time for attention score computing.
A deep normalization strategy is used when performing residual connections to ensure the training of hundred-level Conformer blocks. This strategy involves discounting the parameters of the encoder and decoder parts with a function that is related respectively to the number of encoder layers and decoder layers.
In addition, this deep normalization strategy ensures a successful building of 10 to 100 layers so that the model is more expressive. In contrast, the deep sparse Conformer time and memory costs decrease at a rate of 10% to 20% when compared to the usual Conformer.
Attention-enhanced Citrinet for speech recognition
Citrinet, proposed by NVIDIA researchers, is an end-to-end convolutional Connectionist Temporal Classification (CTC)-based ASR model. To capture local and global contextual information, Citrinet uses 1D time-channel separable convolutions combined with sub-word encoding and squeeze-and-excitation (SE), enabling the whole architecture to achieve state-of-the-art accuracies compared with transformer-based counterparts.
Applying Citrinet to Japanese ASR involves several challenges. Specifically, it is relatively slower at convergence and more difficult to train a model with a comparable accuracy than similar deep neural network models. Considering that there are as many as 235 convolutional layers that influence the convergence speed of Citrinet, we aim to reduce the CNN layers by introducing multi-head attentions in the convolution module in Citrinet blocks while keeping the SE and residual modules unchanged.
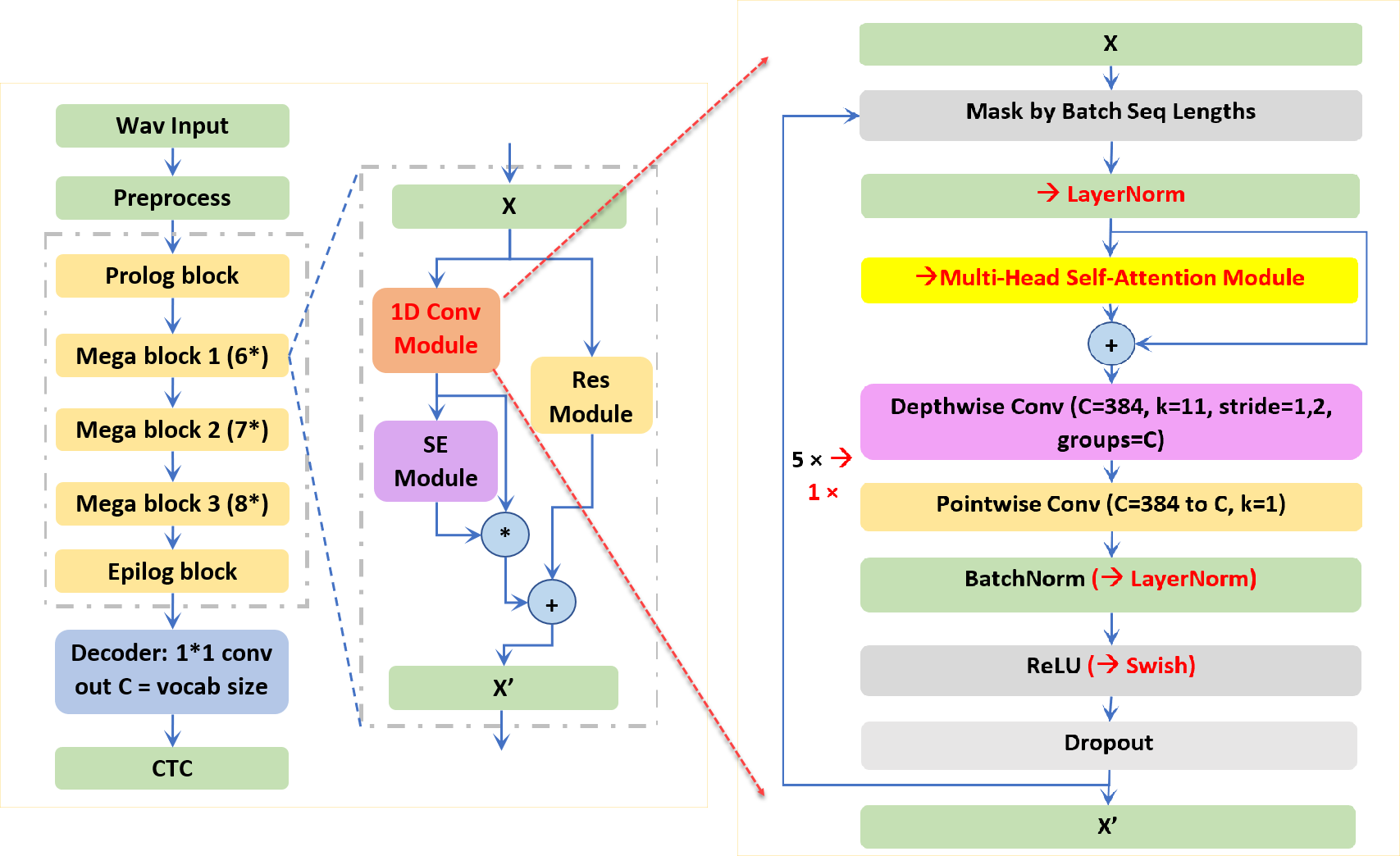
As shown in Figure 2, speeding up the training time involves reducing eight convolution layers in each attention-enhanced Citrinet block. In addition, considering that self-attention has time/memory complexities of quadratic to the length of input audio waves, we reduced the original 23 Jasper blocks to eight blocks with a significant model size reduction. This design ensures the attention-enhanced Citrinet reaches comparable inference time for long speech sequences with layers from the 20s to the 100s.
Preliminary experiments show that attention-based models converge at 100 to 200 epochs while 500 to 1,000 epochs are required for Citrinet’s convergence to the best error rates. Experiments on the Japanese CSJ-500-hour dataset show that the attention-Citrinet requires fewer layers of blocks and converges faster with lower character error rates than Citrinet with 80% training time and Conformer with 40% training time and 18.5% model size.
Summary
Generally, we propose two novel architectures to build end-to-end Japanese ASR models. In one direction, we improved the transformer-based Conformer training and inferencing speed and retained its accuracy. We successfully built sparser and deeper Conformer models. We also improved the CNN-based Citrinet convergence speed and accuracy by introducing a multi-head self-attention mechanism and pruning 80% of the CNN layers. These proposals are general and applicable to other Asian languages.
To learn more about Japanese language ASR models, see Deep Sparse Conformer for Speech Recognition and Attention Enhanced Citrinet for Speech Recognition, or watch the related INTERSPEECH 2022 session, Neural Transducers, Streaming ASR, and Novel ASR Models.
