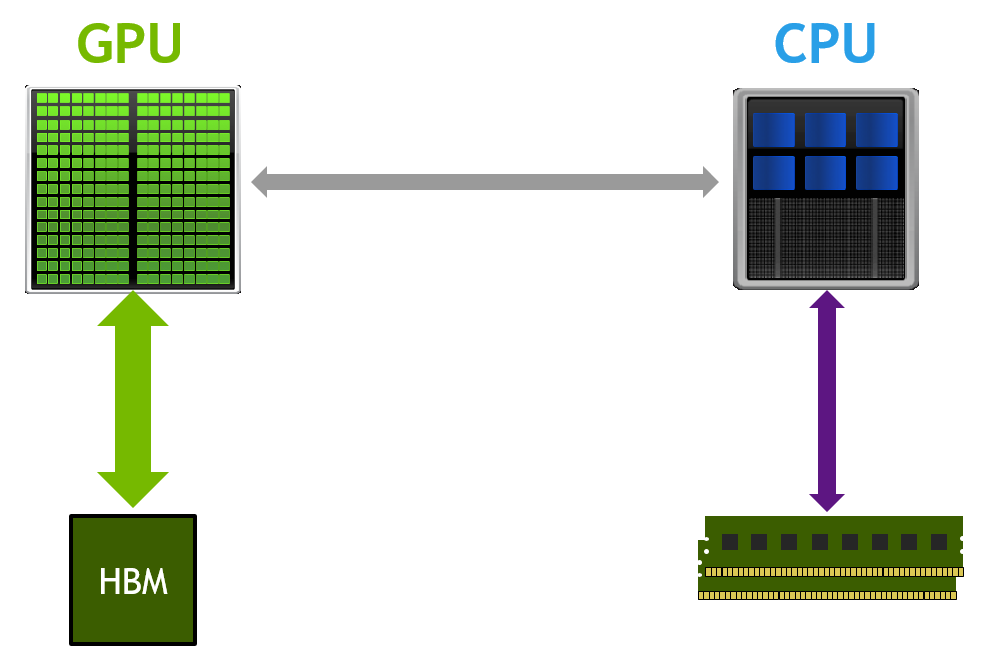
Since its introduction more than 7 years ago, the CUDA Unified Memory programming model has kept gaining popularity among developers. Unified Memory provides a simple interface for prototyping GPU applications without manually migrating memory between host and device.
Starting from the NVIDIA Pascal GPU architecture, Unified Memory enabled applications to use all available CPU and GPU memory in the system, enabling easier scaling to larger problem sizes. For more information about getting started with GPU computing using Unified Memory, see An Even Easier Introduction to CUDA.
Do you want to run your application seamlessly with large datasets and also keep memory management simple? Unified Memory can be used to make virtual memory allocations larger than available GPU memory. At the event of oversubscription, GPU automatically starts to evict memory pages to system memory to make room for active in-use virtual memory addresses.
However, application performance greatly depends on the memory access pattern, data residency, and the system you’re running on. Over the past few years, we’ve published a few posts on using Unified Memory for GPU memory oversubscription. We’ve helped you achieve higher performance for your applications through various programming techniques, such as prefetching and memory usage hints.
In this post, we dive into the performance characteristics of a micro-benchmark that stresses different memory access patterns for the oversubscription scenario. It helps you break down and understand all the performance aspects of Unified Memory: When it’s a good fit, when it’s not, and what you can do about it. As you will see from our results, the performance can vary up to 100x depending on the platform, oversubscription factor, and memory hints. We hope that this post makes it clearer when and how to use Unified Memory in your applications!
Benchmark setup and access patterns
To evaluate Unified Memory oversubscription performance, you use a simple program that allocates and reads memory. A large chunk of contiguous memory is allocated using cudaMallocManaged, which is then accessed on GPU and effective kernel memory bandwidth is measured. Different Unified Memory performance hints such as cudaMemPrefetchAsync and cudaMemAdvise modify allocated Unified Memory. We discuss their impact on performance later in this post.
We define a parameter called “oversubscription factor,” which controls the fraction of the available GPU memory allocated for the test.
- A value of 1.0 means that all the memory available on a GPU is allocated.
- A value less than 1.0 means that GPU is not oversubscribed
- A value greater than 1.0 can be interpreted as how much a given GPU is oversubscribed. For example, an oversubscription factor value of 1.5 for a GPU with 32-GB memory means that 48 GB memory was allocated using Unified Memory.
We tested three memory access kernels in our micro-benchmarks: grid-stride, block-side, and random-per-warp. Grid-stride and block-stride are the most common sequential access patterns in many CUDA applications. However, unstructured or random access is also widely popular in emerging CUDA workloads like graph applications, hash tables, and embeddings in recommendation systems. We decided to test all three.
Grid stride
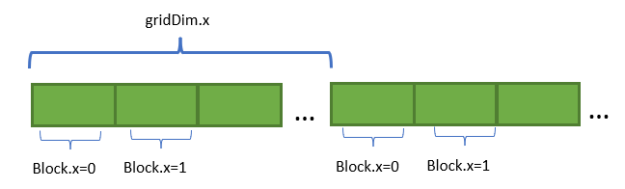
Each thread block accesses elements in neighboring memory region in a loop iteration and then takes a grid stride (blockDim.x * gridDim.x).
template<typename data_type>
__global__ void read_thread(data_type *ptr, const size_t size)
{
size_t n = size / sizeof(data_type);
data_type accum = 0;
for(size_t tid = threadIdx.x + blockIdx.x * blockDim.x; tid < n; tid += blockDim.x * gridDim.x)
accum += ptr[tid];
if (threadIdx.x == 0)
ptr[0] = accum;
}
Block stride
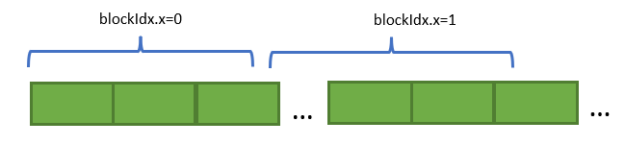
Each thread block accesses a large chunk of contiguous memory, which is determined based on total allocated memory size. At any given time, resident blocks on an SM can be accessing different pages of memory due to the large memory domains assigned to each of the blocks.
template<typename data_type>
__global__ void read_thread_blockCont(data_type *ptr, const size_t size)
{
size_t n = size / sizeof(data_type);
data_type accum = 0;
size_t elements_per_block = ((n + (gridDim.x - 1)) / gridDim.x) + 1;
size_t startIdx = elements_per_block * blockIdx.x;
for (size_t rid = threadIdx.x; rid < elements_per_block; rid += blockDim.x) {
if ((rid + startIdx) < n)
accum += ptr[rid + startIdx];
}
if (threadIdx.x == 0)
ptr[0] = accum;
}
Random warp
In this access pattern, for each loop iteration of the warp, a random page is selected and then a contiguous 128B (32 elements of 4B) region is accessed. This results in a random page being accessed by each warp of the thread block, across all thread blocks. The loop count of the warp is determined by total number of warps and total memory allocated.

The kernel is launched with thread block and grid parameters that achieve 100% occupancy. All the blocks of the kernel are always resident on the GPU.
Hardware setup
We used a single GPU of the following three different hardware setups for the benchmarks in this post.
| System | GPU architecture | GPU memory size | CPU-GPU Interconnect | Theoretical one-way interconnect bandwidth (GB/s) | Config name |
| DGX 1V | V100 | 32 GB | PCIe Gen3 | 16 | V100-PCIe3-x86 |
| DGX A100 | A100 | 40 GB | PCIe Gen4 | 32 | A100-PCIe4-x86 |
| IBM Power9 | V100 | 32 GB | NVLink 2.0 | 75 | V100-NVLink-P9 |
We’ve investigated different memory residency techniques to improve oversubscription performance for these access patterns. Fundamentally, we have tried to remove Unified Memory page faults and find the optimal data-partition strategy to get best read bandwidth for the benchmark. In this post, we discuss the following memory modes:
- On-demand migration
- Zero-copy
- Data partitioning between CPU and GPU
In the following sections, we dive into performance analysis and an explanation of all the optimizations. We also discuss what workloads work well with Unified Memory for oversubscription.
Baseline implementation: On-demand migration
In this test case, the memory allocation is performed using cudaMallocManaged and then pages are populated on system (CPU) memory in the following way:
cudaMallocManaged(&uvm_alloc_ptr, allocation_size); // all the pages are initialized on CPU for (int i = 0; i < num_elements; i++) uvm_alloc_ptr[i] = 0.0f;
Then, a GPU kernel is executed and the performance of the kernel is measured:
read_thread<float><<<grid, block, 0, task_stream>>>((float*)uvm_alloc_ptr, allocation_size);
We used one of the three access patterns described in the previous section. This is the easiest way to use Unified Memory for oversubscription, because no hints are required by the programmer.
Upon kernel invocation, GPU tries to access the virtual memory addresses that are resident on the host. This triggers a page-fault event that results in memory page migration to GPU memory over the CPU-GPU interconnect. The kernel performance is affected by the pattern of generated page faults and the speed of CPU-GPU interconnect.
The page fault pattern is dynamic, as it depends on the scheduling of blocks and warps on streaming multiprocessors. This is followed by the memory load instruction issue from the GPU threads.

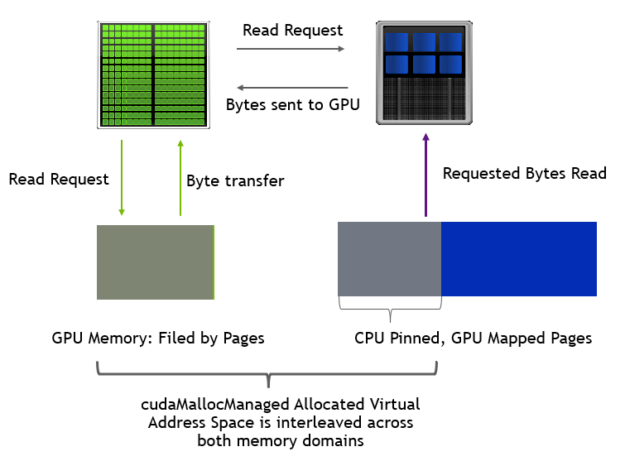
Figure 5 shows how page fault is serviced on an empty GPU and an oversubscribed GPU. At oversubscription, a memory page is first evicted from GPU memory to system memory, followed by transfer of requested memory from CPU to GPU.
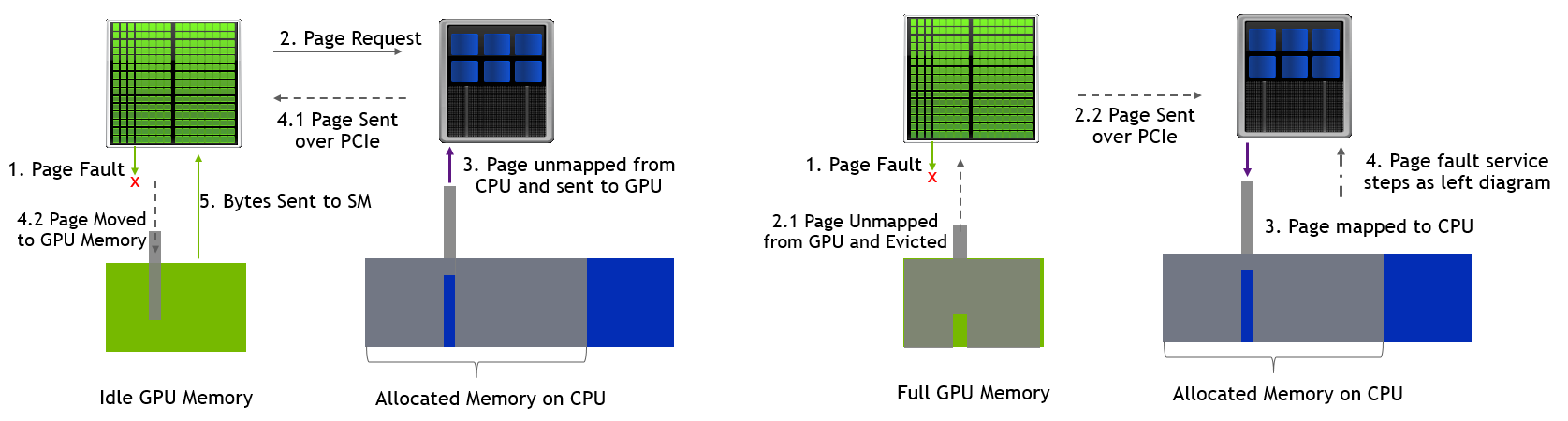
Figure 6 shows the memory bandwidth achieved by the different access patterns on V100, A100, and V100 with Power9 CPU.

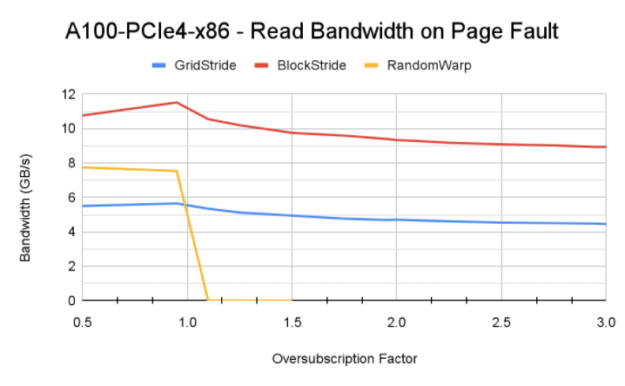
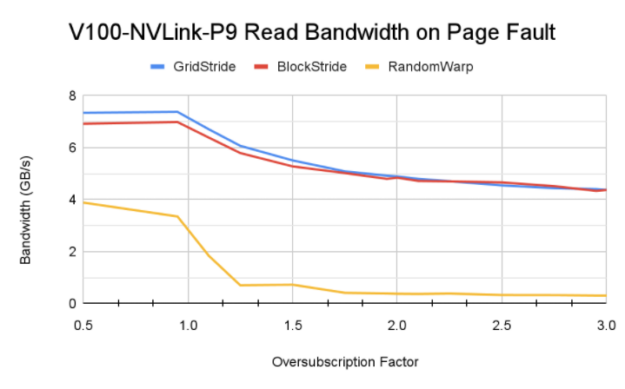
Sequential access analysis
The difference in page fault driven memory read bandwidth between access pattern and different platforms can be explained by following factors:
- Impact of the access pattern: The grid stride access pattern is traditionally known to achieve maximum memory bandwidth when accessing GPU-resident memory. Here, the block stride access pattern achieves higher memory bandwidth due to the page fault traffic that this pattern generates. It is also worth noting that the default system memory page size on Power9 CPU is 64 KB, compared to 4 KB on x86 systems. This helps Unified Memory fault migration move larger chunks of memory from CPU to GPU when a page-fault event is triggered.
- Sensitivity to GPU architecture and interconnect: DGX A100 has faster PCIe Gen4 interconnect between CPU and GPU. This could be the reason for higher bandwidth achieved for A100. However, interconnect bandwidth is not saturated. The primary factor for higher bandwidth is that A100 GPU with 108 streaming multiprocessors can generate more page faults due to a higher number of active thread blocks on the GPU. This understanding is also confirmed by the P9 test, where despite the NVLink connection between GPU-CPU with theoretical peak bandwidth of 75 GB/s, lower read bandwidth than A100 is achieved.
Tip: During the experiments for this post, we discovered that the streaming grid and block stride kernel access patterns are not sensitive to thread block size and intra-block synchronization. However, to achieve better performance using the other optimization methods discussed, we used 128 threads in a block with intra-block synchronization at each loop unroll. This ensured that all the warps of the block used the SM’s address translation units efficiently. To look at kernel design for intra-block synchronization, see the source code released with this post. Try out the variant with and without synchronization with different block sizes.
Random access analysis
Random warp access pattern yields only a few hundred KB/s read bandwidth in the oversubscription domain for x86 platform due to many page faults and the resulting memory migration from CPU to GPU. Since accesses are random, a small fraction of migrated memory is used. The migrated memory may end up evicted back to the CPU to make space for other memory fragments.
However, access counters are enabled on Power9 systems that lead to CPU mapped memory access from GPU and not all accessed memory fragments are immediately migrated to GPU. This results in consistent memory read bandwidth with less memory thrashing than x86 systems.
Optimization 1: Direct access to system memory (zero-copy)
As an alternative to moving memory pages from system memory to GPU memory over the interconnect, you can also directly access the pinned system memory from the GPU. This memory allocation methodology is also known as zero-copy memory.
The pinned system memory can be allocated using CUDA API call cudaMallocHost or from the Unified Memory interface by setting the preferred location of a virtual address range to the CPU.
cudaMemAdvise(uvm_alloc_ptr, allocation_size, cudaMemAdviseSetPreferredLocation, cudaCpuDeviceId); cudaMemAdvise(uvm_alloc_ptr, allocation_size, cudaMemAdviseSetAccessedBy, current_gpu_device);

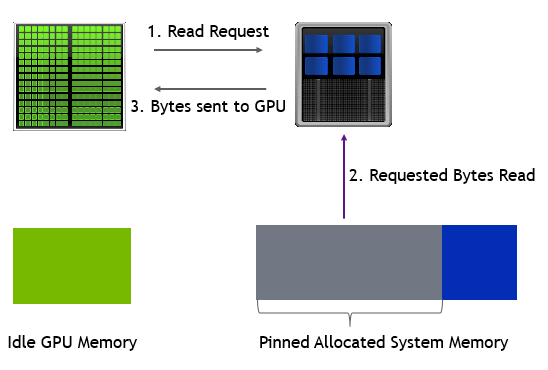
Figure 9 shows the memory bandwidth achieved by the read kernels. On the x86 platform, an A100 GPU can achieve higher bandwidth compared to a V100 because of the faster PCIe Gen4 interconnect between CPU and GPU on DGX A100. Similarly, the Power9 system achieves peak bandwidth close to interconnect bandwidth with the grid stride access pattern. The grid stride bandwidth pattern on an A100 GPU degrades with oversubscription due to the GPU MMU address translation misses that add to latency for load instructions.
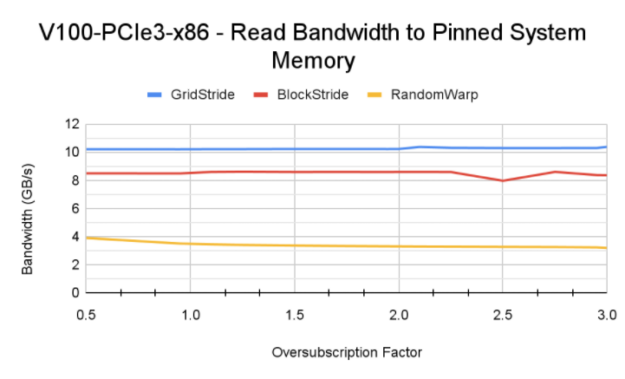
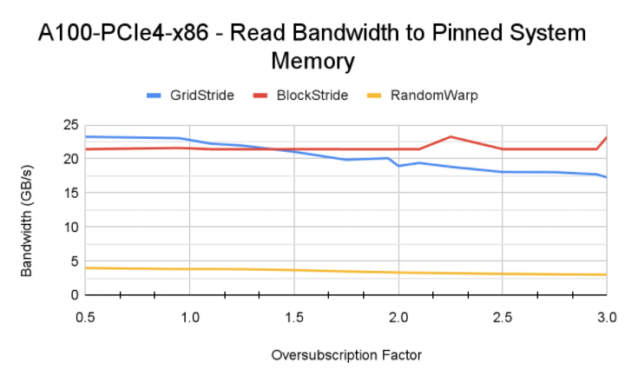
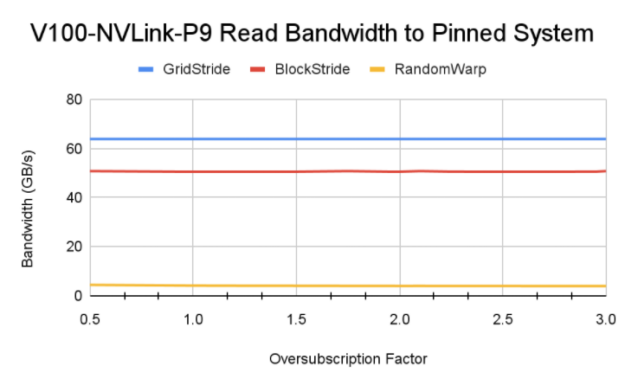
Random warp access yields a constant bandwidth of 3-4 GB/s across the oversubscription domain for all the systems tested. This is much better than the fault-driven scenario covered earlier.
Tip: The performance of the block stride pattern can be improved to the same level as grid stride by making the per-warp memory access 128-byte aligned. 128-byte aligned access ensures that the CPU-GPU link and system DRAM are used efficiently. The grid stride access pattern has this characteristic implicitly and performs optimal memory operations.
Takeaway
It is clear from the data that the zero-copy approach achieves higher bandwidth than the baseline. Pinned system memory is advantageous when you want to avoid the overhead of memory unmap and map from CPU and GPU. If an application is going to use the allocated data just one time, then directly accessing using zero-copy memory is better. However, if there is reuse of data in the application, then faulting and migrating data to GPU can yield a higher aggregate bandwidth, depending on the access pattern and reuse.
Optimization 2: Direct memory access with data partitioning between CPU-GPU
For the fault-driven migration explained earlier, there is an additional overhead of the GPU MMU system stalling until the required memory range is available on GPU. To overcome this overhead, you can distribute memory between CPU and GPU, with memory mappings from GPU to CPU to facilitate fault-free memory access.
There are a couple of methods to distribute memory between CPU and GPU:
- A
cudaMemPrefetchAsyncAPI call with theSetAccessedByUnified Memory hint set for the memory allocation. - Manual hybrid memory distribution between CPU and GPU with manual prefetching and using
SetPreferredLocationandSetAccessedByhints.
We’ve found that both methods perform similarly for many access-pattern and architecture combinations, with a few exceptions. In this section, we primarily discuss the manual page distribution. You can look up the code for both in the unified-memory-oversubscription GitHub repo.
In hybrid memory distribution, few memory pages can be pinned to CPU and memory mapped explicitly using cudaMemAdvise API call with the setAccessedBy hint set to the GPU device. In our test case, we map the excess memory pages to CPU in a round-robin manner, where the map to CPU is determined by how much GPU is oversubscribed by. For example, at an oversubscription factor value of 1.5, every third page is mapped to CPU. At an oversubscription factor of 2.0, every other page is mapped to CPU.
In our experiments, a memory page is set to be 2 MB, which is the largest page size at which GPU MMU can operate.
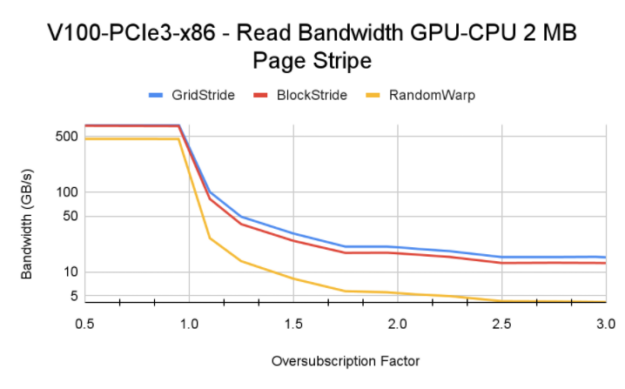
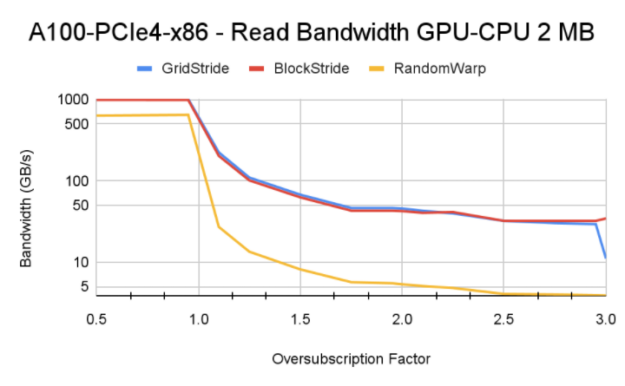
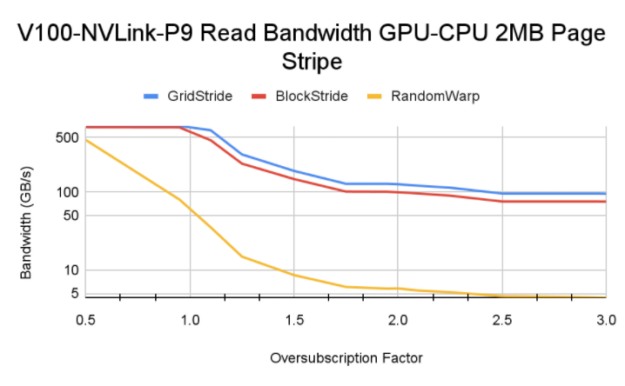
For oversubscription values less than 1.0, all the memory pages are resident on GPU. You see higher bandwidth there compared to cases with a greater than 1.0 oversubscription factor. For oversubscription values greater than 1.0, factors like base HBM memory bandwidth and CPU-GPU interconnect speed steer the final memory read bandwidth.
Tip: When testing on a Power9 system, we came across an interesting behavior of explicit bulk memory prefetch (option a). Because access counters are enabled on P9 systems, the evicted memory doesn’t always stay pinned to CPU and Unified Memory driver can initiate data migration from CPU to GPU. This results in evictions from GPU and the cycle continues throughout the lifetime of a kernel. This process negatively affects the streaming block and grid stride kernels, and they get lower bandwidth than the manual page distribution.
Tip: As described in the tip for optimization 1 earlier, having 128-byte warp-aligned access for transaction to CPU memory results in better performance for all block stride access test cases.
Solution: Single GPU oversubscription
Of the three different memory allocation strategies for GPU oversubscription using Unified Memory, the optimal choice for an allocation method for a given application depends on the memory access pattern and reuse of on-GPU memory.
When you are choosing between the fault and the pinned system memory allocation, the latter performs consistently better across all platforms and GPUs. If GPU residency of the memory subregion benefits from overall application speed, then memory page distribution between GPU and CPU is a better allocation strategy.
Try Unified Memory optimizations
In this post, we reviewed a benchmark with some common access patterns and analyzed performance on various platforms from x86 to P9, and V100 and A100 GPUs. You can use this data as a reference to make projections and consider whether using Unified Memory in your code would be beneficial. We also covered multiple data distribution patterns and Unified Memory modes, which can sometimes yield significant performance benefits. For more information, see the unified-memory-oversubscription microbenchmark source code on GitHub.
In a previous post, we demonstrated that Unified Memory–based oversubscription is especially effective for large data analytics and large deep learning models. Try Unified Memory for oversubscription in your code and let us know how it helps you improve application performance.
