Many of today’s applications process large volumes of data. While GPU architectures have very fast HBM or GDDR memory, they have limited capacity. Making the most of GPU performance requires the data to be as close to the GPU as possible. This is especially important for applications that iterate over the same data multiple times or have a high flops/byte ratio. Many real-world codes have to selectively use data on the GPU due to its limited memory capacity, and it is the programmer’s responsibility to move only necessary parts of the working set to GPU memory.
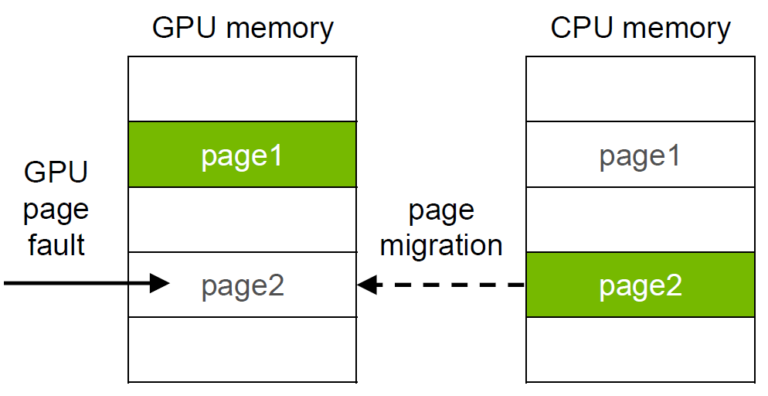
Traditionally, developers have used explicit memory copies to transfer data. While this usually gives the best performance, it requires very careful management of GPU resources and predictable access patterns. Zero-copy access provides fine-grained direct access to the entire system memory, but the speed is limited by the interconnect (PCIe or NVLink) and it’s not possible to take advantage of data locality.
Unified Memory combines the advantages of explicit copies and zero-copy access: the GPU can access any page of the entire system memory and at the same time migrate the data on-demand to its own memory for high bandwidth access. To get the best Unified Memory performance it’s important to understand how on-demand page migration works.
In a new NVIDIA Developer Blog post, Nikolay Sakharnykh, a Senior Developer Technology Engineer at NVIDIA, breaks down Unified Memory page migration step by step and shows you what you can do to optimize your code to get the most out of Unified Memory.
Read more >
Maximizing Unified Memory Performance in CUDA
Nov 20, 2017
Discuss (0)
AI-Generated Summary
- Unified Memory allows the GPU to access any page of the entire system memory while migrating data on-demand to its own memory for high bandwidth access.
- To optimize Unified Memory performance, it is crucial to understand how on-demand page migration works, as explained by Nikolay Sakharnykh, a Senior Developer Technology Engineer at NVIDIA.
- Applications with limited GPU memory capacity can benefit from Unified Memory by avoiding explicit memory copies and leveraging its ability to manage data migration.
AI-generated content may summarize information incompletely. Verify important information. Learn more