Recommender systems (RecSys) have become a key component in many online services, such as e-commerce, social media, news service, or online video streaming. However with their growth in importance, the growth in scale of industry datasets, and more sophisticated models, the bar has been raised for computational resources required for recommendation systems.
After NVIDIA introduced Merlin – a Framework for Deep Recommender Systems – to meet the computational demands for large-scale DL recommender systems, and a NVIDIA team won the ACM RecSys Challenge 2020, now a NVIDIA team has won the WSDM WebTour 21 Challenge organized by Booking.com. The Booking.com challenge focused on predicting the last city destination for a traveler’s trip given their previous booking history within the trip. NVIDIA’s interdisciplinary team included colleagues from NVIDIA’s KGMON (Kaggle Grandmasters), NVIDIA’s RAPIDS (Data Science), and NVIDIA’s Merlin (Recommender Systems) who collaborated on the winning solution.
This post is the first of a three-part series that gives an overview of the NVIDIA team’s first-place solution for the booking.com challenge. This first post gives an overview of recommender system concepts. The second post will discuss deep learning for recommender systems. The third post will discuss the winning solution, the steps involved, and also what made a difference in the outcome.
What is a Recommendation System?
Recommender systems are trained to understand the preferences, previous decisions, and characteristics of people and products, using data gathered about their interactions, which include impressions, clicks, likes, and purchases. Recommender systems help solve information overload by helping users find relevant products from a wide range of selections by providing personalized content. Because of their capability to predict consumer interests and desires on a highly personalized level, recommender systems are a favorite with content and product providers because they drive consumers to just about any product or service that interests them, from books to videos to health classes to clothing.
Types of Recommendation Systems
Traditionally, recommender systems approaches could be divided into these broad categories: collaborative filtering, content filtering, and hybrid recommenders systems. More recently, some variations have been proposed to leverage explicitly the user context (context-aware recommendation), the sequence of user interactions (sequential recommendation) and the interactions of the current user session for next-click prediction (session-based recommendation).
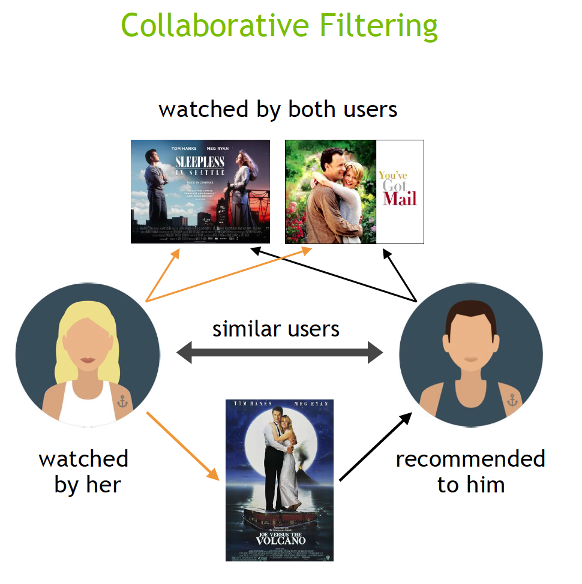
Collaborative filtering algorithms recommend items (this is the filtering part) based on preference information from many users (this is the collaborative part). This approach uses similarity of user preference behavior, given previous interactions between users and items, recommender algorithms learn to predict future interaction. These recommender systems build a model from a user’s past behavior, such as items purchased previously or ratings given to those items and similar decisions by other users. The idea is that if some people have made similar decisions and purchases in the past, like a movie choice, then there is a high probability they will agree on additional future selections. For example, if a collaborative filtering recommender knows you and another user share similar tastes in movies, it might recommend a movie to you that it knows this other user already likes.
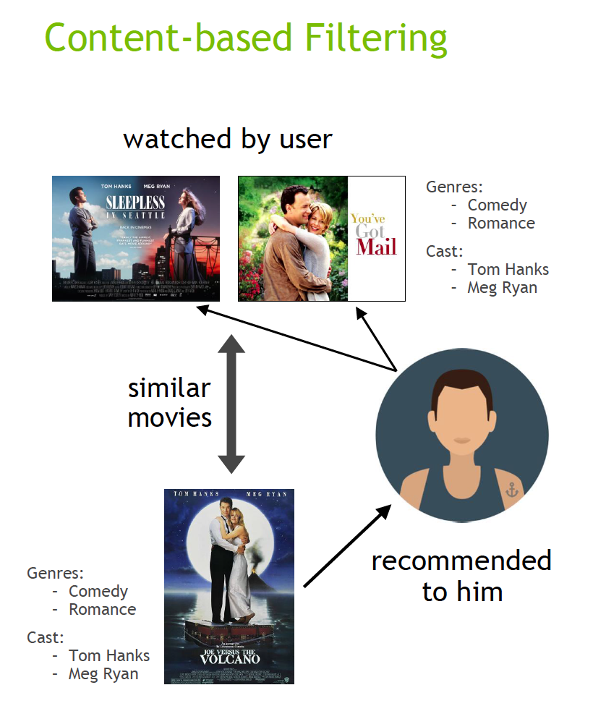
Content filtering, by contrast, uses the attributes or features of an item (this is the content part) to recommend other items similar to the user’s preferences. This approach is based on similarity of items and user features, given information about a user and items they have interacted with, (e.g. a user’s demographics, like age or gender, the category of a restaurant’s cuisine, the average review for a movie), model the likelihood of a new interaction. For example, if a content filtering recommender sees you liked the movies “You’ve Got Mail” and “Sleepless in Seattle,” it might recommend another movie to you with the same genres and/or cast, such as “Joe Versus the Volcano.”
Collaborative filtering is straightforward to apply, as it only requires as input the user id and item id for each interaction. However, it requires a minimum number of interactions by user and by item before starting to provide meaningful recommendations, which is characterized as the cold-start problem. On the other hand, as content-based filtering only leverages the interactions of each user, it deals nicely with the user cold-start problem. But it tends to create a filter bubble, recommending only items very similar to those the user has interacted with before.
Hybrid recommender systems combine the advantages of the types above to create a more comprehensive recommending system.
Session or sequence-based recommender systems use the sequence of user item interactions within a session in the recommendation process. Examples include predicting the next item in an online shopping cart, the next video to watch, or in the booking.com example, the next travel destination of a traveler.
Netflix spoke at NVIDIA GTC about making better recommendations by framing a recommendation as a contextual sequence prediction. Their approach uses a sequence of user actions, plus the current context, to predict the probability of the next action. In the Netflix example, given one sequence for each user—the country, device, date, and time when they watched a movie—they trained a model to predict what to watch next.

How Recommenders Work
Recommender systems are trained using data gathered about the users, items, and their interactions, which include impressions, clicks, likes, mentions, and so on. How a recommender model makes recommendations will depend on the type of data you have. If you only have data about which interactions have occurred in the past, you’ll probably be interested in collaborative filtering. If you have data describing the user and items they have interacted with (e.g. a user’s age, the category of a restaurant’s cuisine, the average review for a movie), you can model the likelihood of a new interaction given these properties at the current moment by adding content and context filtering.
Matrix Factorization for Recommendation
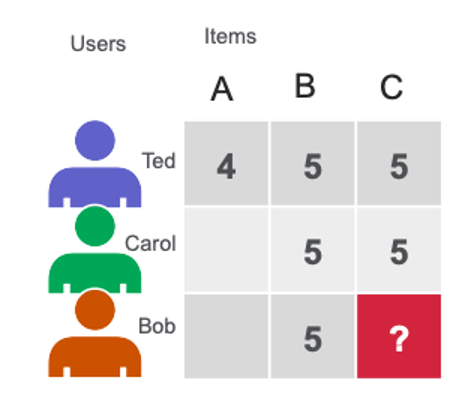
Matrix factorization (MF) techniques are the core of many popular algorithms, including word embedding and topic modeling, and have become a dominant methodology within the collaborative-filtering-based recommendations. MF can be used to calculate the similarity in user’s ratings or interactions to provide recommendations. In the simple user-item matrix below, Ted and Carol like movies B and C. Bob likes movie B. To recommend a movie to Bob, matrix factorization calculates that users who liked B also liked C, so C is a possible recommendation for Bob.
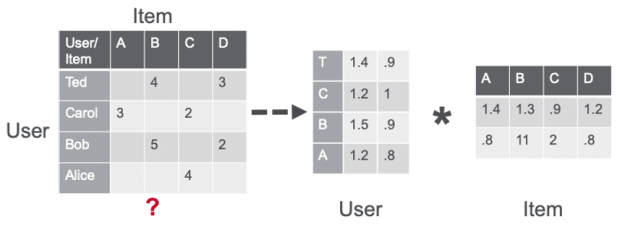
Matrix factorization using the alternating least squares (ALS) algorithm approximates the sparse user item rating matrix u-by-i as the product of two dense matrices, user and item factor matrices of size u × f and f × i (where u is the number of users, i the number of items and f the number of latent features) . The factor matrices represent latent or hidden features which the algorithm tries to discover. One matrix tries to describe the latent or hidden features of each user, and one tries to describe latent properties of each movie. For each user and for each item, the ALS algorithm iteratively learns (f) numeric “factors” that represent the user or item. In each iteration, the algorithm alternatively holds one factor matrix fixed and optimizes for the other by minimizing the loss function with respect to the other. This process continues until it converges.
Conclusion
In this blog, we gave an overview of recommender system concepts and matrix factorization. In part two we will go over deep learning models for recommender systems and in part three we will go over the booking.com winning solution. To learn more, be sure to:
- Read the blog: What’s a Recommender System?
- Read the blog: Accelerating ETL for Recommender Systems on NVIDIA GPUs with NVTabular
- Listen to the on demand session: Recommender Systems Demystified
- Listen to the GTC sessions: NVIDIA Deepens Commitment to Streamlining Recommender Workflows with GTC Spring Sessions
