
The COVID-19 pandemic has brought the focus of agent-based modeling and simulation (ABMS) to the public’s attention. It’s a powerful computational technique for the study of behavior, whether epidemiological, biological, social, or otherwise. The process is conceptually simple:
- Behaviors of individuals are described (the model).
- Inputs to the model are provided.
- The simulation of many interacting individuals (or agents) enables complex, system-level behavior to naturally emerge.
Here’s a classic example: the behavior of flocks, schools, and herds. Through the relatively simple behaviors of staying close to the group (cohesion), avoiding collisions (separation), and matching the speed of your neighbors (alignment), beautiful emergent patterns can be observed.
FLAME GPU is open-source software for the simulation of complex systems. It is domain-independent and can be used for any simulation that uses the idea of agent-based modeling. The agent-based modeling approach of describing individual behaviors and observing the emergent outputs enables FLAME GPU to be used for examples such as flocking, cellular biology, and transportation.
The following video shows an example of flocking as an output of the FLAME GPU software.
Regardless of the topic of a given simulation, using ABMS to simulate a large number of agents may incur a significant computational cost. Typically, such simulators have been designed for sequential execution on CPU architectures, resulting in prohibitively slow time to solution and limiting the feasible scale of simulated models.
The Flexible Large Scale Agent Modeling Environment for GPUs (FLAME GPU) library enables you to harness the power of GPU parallelism to significantly accelerate the computational performance and scale of ABMS. The software is extremely fast and, as a result, can enable scaling to hundreds of millions of agents on NVIDIA A100 and NVIDIA H100 GPUs.
Introducing FLAME GPU
The new FLAME GPU software abstracts the complexities of executing an agent-based model on GPUs by providing an intuitive interface for model and agent behavior specification. The software does this by providing an API that abstracts many of the complexities of the underlying implementation.
For example, technical considerations are all transparently handled to ensure excellent execution performance on the GPU. This could include the construction of spatial data structures, scheduling of CUDA kernel execution, or grouping of homogeneous dense arrays of agents in memory.
The FLAME GPU software is written in CUDA C++ to execute simulations on NVIDIA GPUs. Version 2 has been under development for roughly 5 years by a team of research software engineers at the University of Sheffield. It builds upon and replaces a legacy C version of the software by using modern features of C++ and CUDA. We had help optimizing the code from NVIDIA through their academic accelerator and hackathon programs.
FLAME GPU also has a Python library (pyflamegpu), which enables you to specify models natively in Python. This includes agent behavior, which is runtime transpiled and compiled using Jitify and NVRTC. For more information about using the library, see Creating the Circles Model.
Figure 1 shows the build process of a model using the FLAME GPU library. This post covers the specification of a model description in C++.
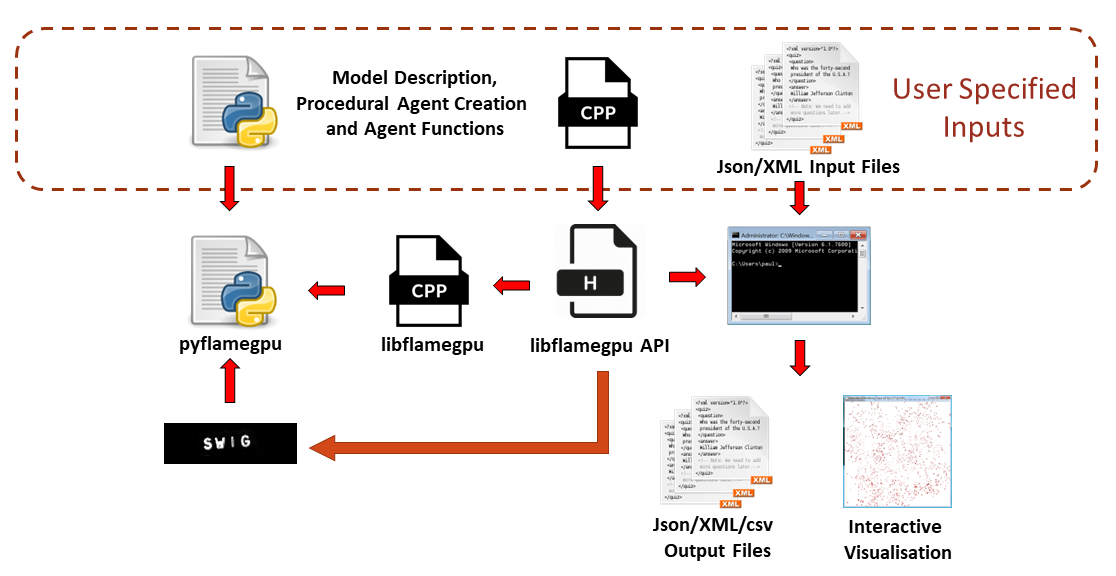
Agent behavior
The FLAME GPU software can be thought of as a more complex, general-purpose version of a particle simulation, such as that provided within the CUDA examples. It enables multiple arbitrary, user-defined, particle or agent types, exchange of information between agents, and complete control of the design of agent’s behavior.
Agent behavior is specified by an agent function, which acts as a stream process. An instance of an agent can update its internal state variables as well as optionally outputting or inputting message data.
Messages are a collection of state variables that are stored in lists, facilitating the indirect communication of information between agents. The inputting of message data to agent functions is through C++ iterators that traverse the message data. Different messaging types implement iterators in different ways but abstract the storage, data structure, and iteration mechanisms from the user and model.
The following example demonstrates a simple user-defined agent function, output_message, that requires three arguments representing the function name, and the input and output message type, respectively.
In the example, a MessageSpatial2D type message is output, which exists within a continuous space 2D environment. The singleton object, FLAMEGPU, is used to retrieve named variables of a specific type, using getVariable, and output these as a message to a message list, using message_out.setVariable.
FLAMEGPU_AGENT_FUNCTION(output_message, flamegpu::MessageNone, flamegpu::MessageSpatial2D) {
FLAMEGPU->message_out.setVariable<int>("id", FLAMEGPU->getID());
FLAMEGPU->message_out.setLocation(
FLAMEGPU->getVariable<float>("x"),
FLAMEGPU->getVariable<float>("y"));
return flamegpu::ALIVE;
}
A more complex agent function can then be specified to describe the behavior of an agent that processes the messages output by output_message. In input_message, described in the following code example, the message loop iterator traverses any spatial data structures to return candidate messages.
Given MessageSpatial2D messages as input, candidate messages are determined by distance. The behavior of this agent is to apply a repulsive force, which is determined by the location of neighbors. The repulsion factor is controlled by an environment variable; that is, a variable that is read-only for all agents in the model.
FLAMEGPU_AGENT_FUNCTION(input_message, flamegpu::MessageSpatial2D, flamegpu::MessageNone) {
const flamegpu::id_t ID = FLAMEGPU->getID();
const float REPULSE_FACTOR =
FLAMEGPU->environment.getProperty<float>("repulse");
const float RADIUS = FLAMEGPU->message_in.radius();
float fx = 0.0;
float fy = 0.0;
const float x1 = FLAMEGPU->getVariable<float>("x");
const float y1 = FLAMEGPU->getVariable<float>("y");
int count = 0;
// message loop iterator
for (const auto &message : FLAMEGPU->message_in(x1, y1)) {
if (message.getVariable<flamegpu::id_t>("id") != ID) {
const float x2 = message.getVariable<float>("x");
const float y2 = message.getVariable<float>("y");
float x21 = x2 - x1;
float y21 = y2 - y1;
const float separation = sqrt(x21*x21 + y21*y21);
if (separation < RADIUS && separation > 0.0f) {
float k = sinf((separation / RADIUS)*3.141f*-2)*REPULSE_FACTOR;
// Normalize without recalculating separation
x21 /= separation;
y21 /= separation;
fx += k * x21;
fy += k * y21;
count++;
}
}
}
fx /= count > 0 ? count : 1;
fy /= count > 0 ? count : 1;
FLAMEGPU->setVariable<float>("x", x1 + fx);
FLAMEGPU->setVariable<float>("y", y1 + fy);
FLAMEGPU->setVariable<float>("drift", sqrt(fx*fx + fy*fy));
return flamegpu::ALIVE;
}
The agent functions described here define a complete example of behavior specification for an agent-based system, which we refer to as the circles model. The behavior is analogous to that of a particle system, a flock or swarm, or even a simple cellular biology model.
Although not immediately obvious due to the abstraction mechanisms used, both agent functions in the example are compiled as CUDA device code.
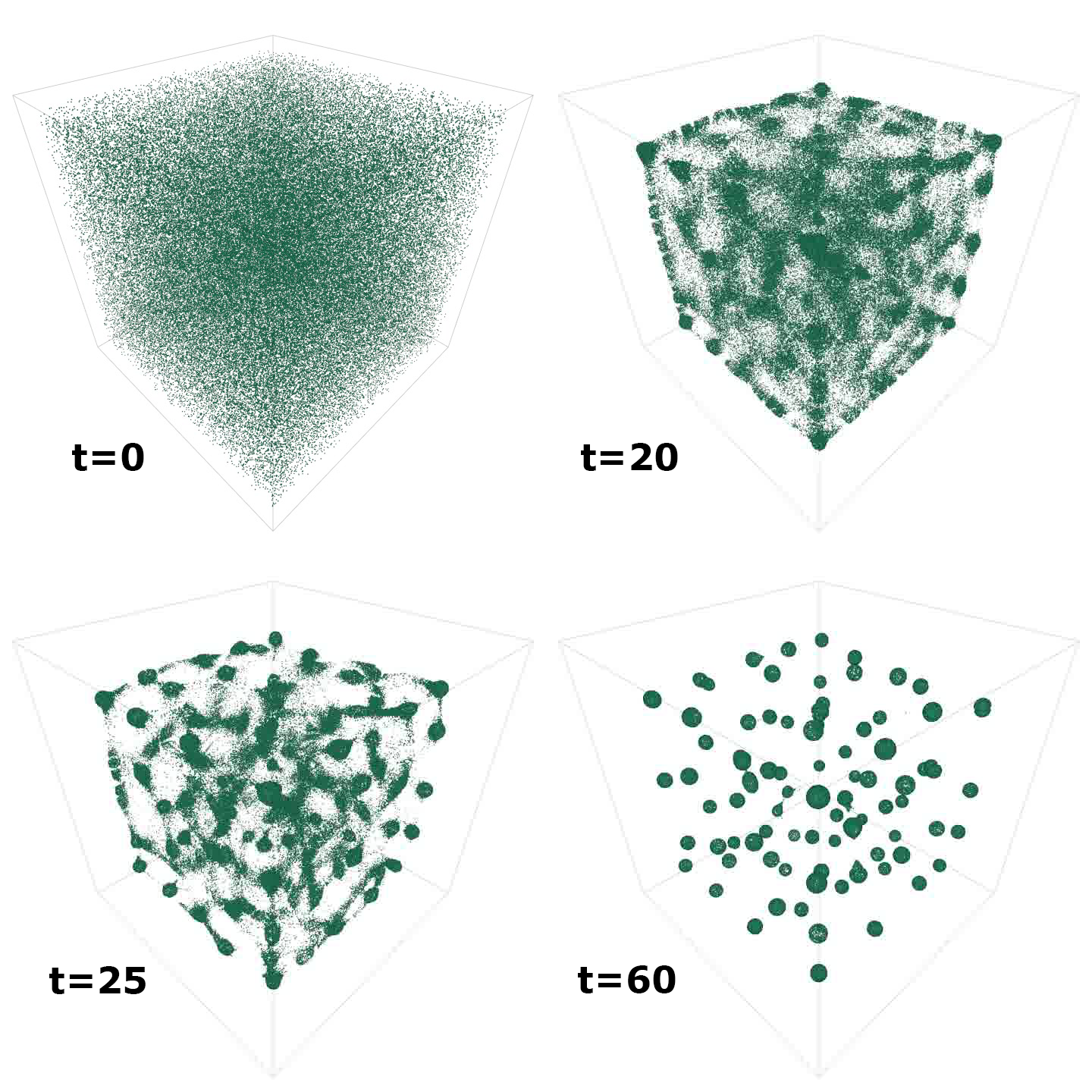
Figure 2 shows the emergent output of this model when simulated over time (but extended to 3D). The visualization is produced from screen captures from the in-built FLAME GPU visualizer.
Describing a model
One of the most important features of the FLAME GPU software is the state-based representation of agents, where states are simply a method of grouping agents. For an epidemiological model, an agent may be within a susceptible, exposed, infected, or recovered (SEIR) state. Within a biological model, a cell agent might be in different stages of the cell cycle. The state of an agent is likely to dictate the behavior the agent performs.
In FLAME GPU, agents can have multiple states and an agent function is applied only to agents in a specific state. The use of states ensures that within a model diverse, heterogeneous behavior can occur, avoiding highly divergent code execution. Put simply, agents are grouped with others that perform the same behaviors.
Models, such as the circles model in this worked example, can have a single (default) state, however, a complex model may have many. States also play an important role in determining the execution order of functions. Indirect communication occurs between agent states through message use in functions.
Dependencies between agents and functions can be procedurally determined through dependency analysis. The result is a directed acyclic graph (DAG) representing the behavior of all agents over a single iteration of a model.
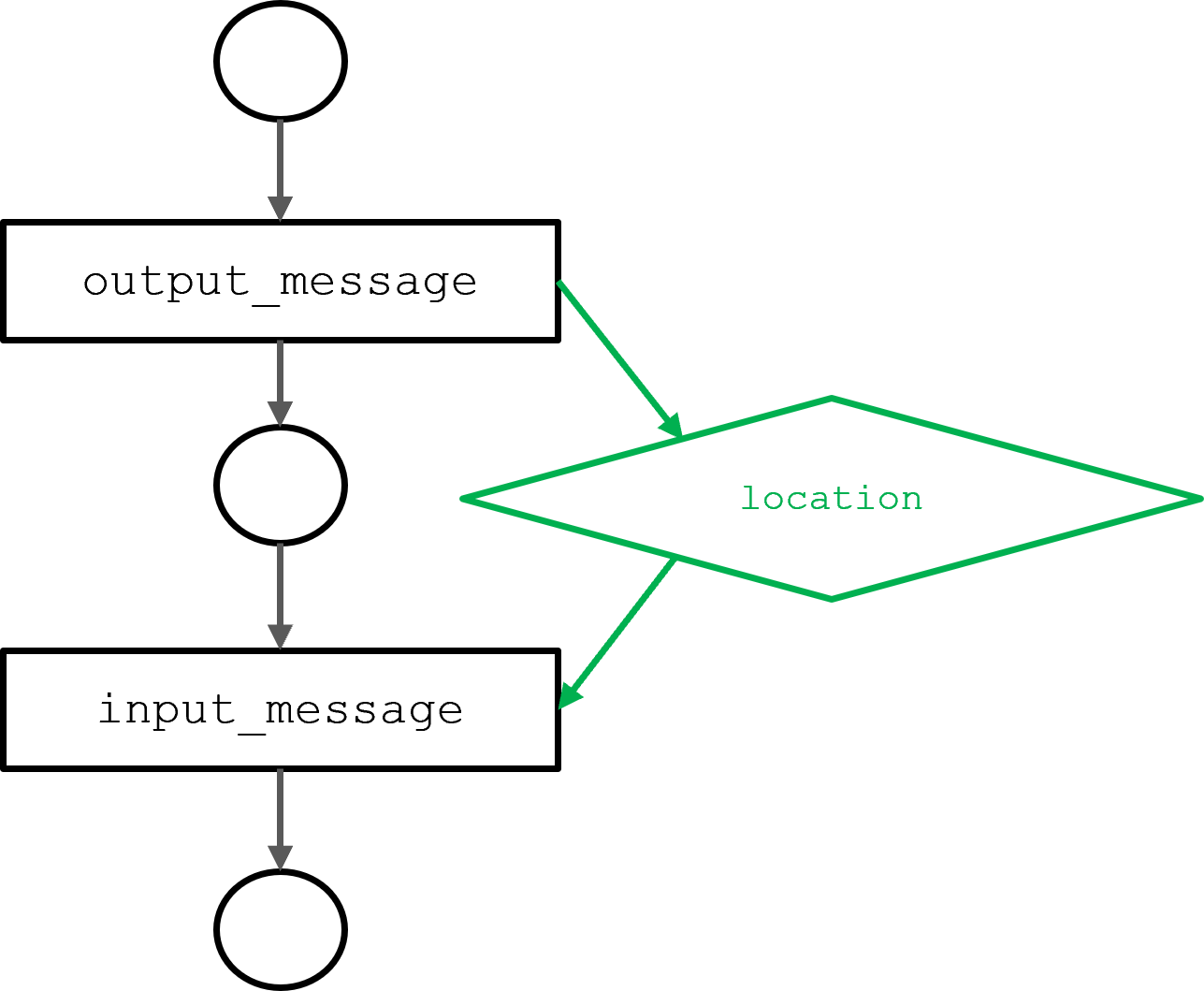
Figure 3 shows the DAG of the circles model resulting from the output_message and input_message agent functions described in the previous section. The input_message function is dependent on location messages, output by the output_message function. The dependency determines the execution order.
The complete state-based description of a FLAME GPU model is defined using the FLAME GPU API (Figure 4). A ModelDescription object acts as the root of a described model and can be described as follows:
// Define the FLAME GPU model
flamegpu::ModelDescription model("Circles Tutorial");
All further API objects are siblings of a ModelDescription object. In the following example, a (“circle”) agent is defined with three variables, where each variable has a specific string name and an explicit type. The variable names and types match those obtained within the agent functions:
// Define an agent named point
flamegpu::AgentDescription agent = model.newAgent("circle");
// Assign the agent some variables (ID is implicit to agents, so we don't define it ourselves)
agent.newVariable<float>("x");
agent.newVariable<float>("y");
agent.newVariable<float>("drift", 0.0f);
Like agents, messages contain a number of variables. For example, the message defined here has a variable to store the ID of the agent from which it originated. Messages also have a specialism that indicates how they are stored and iterated.
In the next example, the message is described as type flamegpu::MessageSpatial2D. Importantly, this type matches that of the input and output types of the previous agent functions. As the message type is 2D spatial, the message implicitly includes coordinate variables x and y.
The message type also requires the definition of an environment size (the bounds of which the messages exist within) and a spatial radius. The spatial radius determines the range within which messages are returned to agents querying the message list.
// Define a message of type MessageSpatial2D named location
flamegpu::MessageSpatial2D::Description message =
model.newMessage<flamegpu::MessageSpatial2D>("location");
// Configure the message list
message.setMin(0, 0);
message.setMax(ENV_WIDTH, ENV_WIDTH);
message.setRadius(1.0f);
// Add extra variables to the message
// X Y (Z) are implicit for spatial messages
message.newVariable<flamegpu::id_t>("id");
Message specialism forms an important performance consideration of the FLAME GPU software. Different message types have different implementations and optimizations. In all cases, they have been optimized using the NVIDIA Nsight Compute profiler to increase memory and computational throughput.
A message type of flamegpu::BruteForce is equivalent to every agent reading every message in a list. There are numerous message types, including types for discretized environments, buckets, and arrays, most of which use CUB sort and scan functions to build spatial data structures. The spatial messaging used in this worked example builds a binned data structure that enables messages from within a fixed area to be easily located.
The agent functions defined in the previous section can be linked to the model by assigning them to specific agents. The message input and output types defined in the following code example are required to match those of the FLAMEGPU_AGENT_FUNCTION definitions.
// Set up the two agent functions
flamegpu::AgentFunctionDescription out_fn =
agent.newFunction("output_message", output_message);
out_fn.setMessageOutput("location");
flamegpu::AgentFunctionDescription in_fn =
agent.newFunction("input_message", input_message);
in_fn.setMessageInput("location");
Within the FLAME GPU library, variable names (such as x) are translated to CUDA memory addresses through hashing. Compile time hashing is used to ensure that the translation has minimal overhead at runtime. Function-specific hash tables are loaded into shared memory at the start of each agent function to minimize latency.
During development, type checking can be enabled using the FLAMEGPU_SEATBELTS option within CMake. This option performs other additional runtime checks, which are useful during development. After a model is completed, FLAMEGPU_SEATBELTS can be disabled for maximum execution performance.
FLAME GPU also supports runtime-compiled agent functions. In this case, the agent function can be supplied as a string and is compiled using the NVIDIA Jitify library, which acts as a frontend for NVRTC. Runtime compilation of device code is essential in providing Python bindings (pyflamegpu).
To further improve the user experience in Python, pyflamegpu permits agent functions to be described in a subset of native Python. This is transpiled to C++ as part of the runtime compilation process.
Environment properties can be used to parameterize a model and can be read by all agents. The repulsion factor, AGENT_COUNT, and ENV_WIDTH are specified in the code sample. All environment properties are hashed using the same mechanism as agent variables.
// Define environment properties
flamegpu::EnvironmentDescription env = model.Environment();
env.newProperty<unsigned int>("AGENT_COUNT", AGENT_COUNT);
env.newProperty<float>("ENV_WIDTH", ENV_WIDTH);
env.newProperty<float>("repulse", 0.05f);
The final stage to model specification is to define the execution order of the agent functions. This can be specified manually as layers, or inferred through dependency analysis. The following example demonstrates the process of generating layers through dependency analysis:
// Dependency specification flamegpu::DependencyGraph dependencyGraph = model.getDependencyGraph(); dependencyGraph.addRoot(out_fn); dependencyGraph.generateLayers(model);
The separation of agent functions into layers provides a synchronization framework in which the indirect message communication avoids race conditions. More complex models enable overlapping the execution of functions within the same layer. Streams used within layers enable concurrent execution, the advantages of which can be significant in achieving good utilization of the device.
Scheduling of execution is static as the DAG does not change. However, aspects of the graph may not result in the execution of particular functions, for example, if agents do not exist within a particular state.
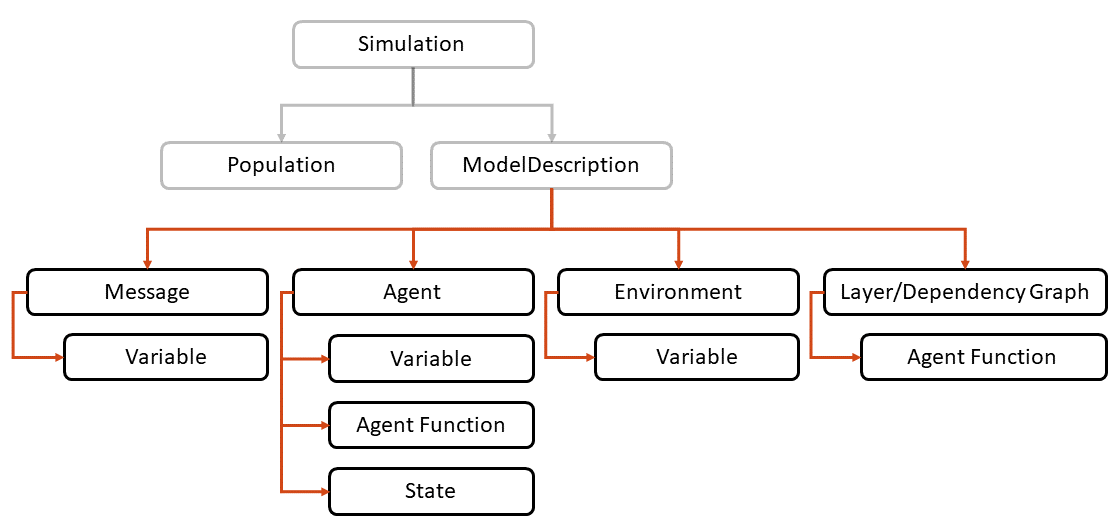
For more information about the API, see the FLAME GPU documentation.
Simulating agents
Execution of an agent model requires a CUDASimulation object to allocate the necessary memory for the model on the GPU device. The simulation object is responsible for configuring the inputs and outputs to the model and the launch configurations of the simulation itself.
The program’s main arguments are passed to the simulation object and can include the number of iterations (for example, --steps 100).
flamegpu::CUDASimulation cuda_sim(model, argc, argv);
Although not required, logging for a model can be specified using flamegpu::StepLoggingConfig, which sets the frequency of logging as well as the variables that should be logged. Agent variable values can be reduced using common reduction operators (min, man, mean, stdev, sum) or alternatively entire state variables of a population can be recorded.
flamegpu::StepLoggingConfig step_log_cfg(cuda_sim);
step_log_cfg.setFrequency(1);
step_log_cfg.agent("circle").logMean<float>("drift");
// Attach the logging config
cuda_sim.setStepLog(step_log_cfg);
For the circles model in the worked example, logging the drift enables a measure of overall agent movement. Drift is an emergent property that is expected to reduce over time as agents form structured circular shapes (Figure 2).
The final stage of simulation is to define the initial variables of agents. In the following example, a Mersenne Twister pseudo-random generator is used to generate the x and y variables of each agent in the population. The flamegpu::AgentVector object provides a mechanism to set agent data. This is stored in dense arrays in device memory to promote coalesced access from within agent functions.
std::mt19937_64 rng;
std::uniform_real_distribution<float> dist(0.0f, ENV_MAX);
flamegpu::AgentVector population(model.Agent("circle"), AGENT_COUNT);
for (unsigned int i = 0; i < AGENT_COUNT; i++) {
flamegpu::AgentVector::Agent instance = population[i];
instance.setVariable<float>("x", dist(rng));
instance.setVariable<float>("y", dist(rng));
}
cuda_sim.setPopulationData(population);
Finally, the simulation can be executed.
// Run the simulation cuda_sim.simulate();
In this worked example, a single simulation execution takes place. The step_log_cfg object could then be used to process outputs or to dump logged values to a file. FLAME GPU also supports ensemble simulations, which permits multiple instantiations of a simulation to be executed but with varying inputs and environment properties.
Simulation instantiations can be scheduled for execution on a single device or can be distributed between devices on a shared memory system. We have used this functionality extensively for calibrating biological models of cancer growth and treatment.
If graphical simulation is required, the simulation could be visualized using the FLAME GPU built-in 3D OpenGL visualizer (video). The visualizer supports instance-based rendering of agents and uses CUDA OpenGL interoperability to map agent data directly into the graphics pipeline.
If you watch the video of this simulation, you see that each agent is actually a 3D bird model with flapping animation. Interactive visualization of millions of agents is possible and the visualizer permits navigation and interactive manipulation of environment variables to observe emergent effects.
Performance
FLAME GPU is extremely efficient at agent-based simulation, however, making a fair comparison of agent-based simulators is difficult. Most existing simulators are designed for serial execution. In fact, lots of existing models are even dependent on serial operations to ensure fairness.”
A classic example of this is the movement of agents within a discrete (or checkerboard-like) environment. In serial, the movement of agents ensures that the environment cells are never occupied by more than one agent. Randomizing the order of movement ensures that the simulation is fair.
The parallel equivalent of this movement, implemented in FLAME GPU, requires the use of an iterative bidding process to ensure that all agents have the opportunity to move and avoid conflicts in cell occupation.
FLAME GPU introduces the novel concept of submodels to encapsulate recursive algorithms to resolve such conflicts. Agent-based models, which avoid spatial conflicts and operate in continuous space, are better performing with a parallel environment, as conflict does not occur during movement.
We chose to compare two different models to show how FLAME GPU compares to other well-known CPU simulators, Mesa, NetLogo, and Agents.jl (Julia). We picked two well-known models in which there are existing implementations in each framework.
The first of these, an implementation of a Boids model of flocking in 2D, operates in continuous space and is like the worked example in this post, only with slightly more complex interactions between agents.
The second, Schelling’s social model of segregation, is an example of a highly serialized model. It has movement within a checkerboard-type environment. Within FLAME GPU, it uses a submodel to resolve conflicts in movement.
The performance of the Boids model was measured over 100 iterations and was limited to 80k agents, which is not enough to fully use a modern GPU device. Beyond this scale, the serial simulators are a limiting factor to reasonable benchmarking times. Within the Schelling model, scale is increased to 250K agents (with 80% occupancy of cells) as it is more efficient in all simulators to execute due to the constrained grid-based environment.
The benchmark containing the two models is containerized and available on the FLAMEGPU/ABM_Framework_Comparisons GitHub repo. It is forked from an existing benchmark activity undertaken for the Agents.jl framework. To generate Figure 5, a total of 10 repetitions per simulation were used. In the interest of time, this was reduced to three repetitions for NetLogo and MESA.
The mean simulation time is reported by measuring the main simulation loop, excluding initialization of the mode, as is common in all simulators. The results were obtained from a machine with the following configuration:
- Ubuntu 22.04 Apptainer image
- AMD EPYC 7413 24-Core Processor
- NVIDIA A100-SXM4 80 GB (Driver 515.65.01)
- FLAME GPU 2.0.0-rc0
- Netlogo 6.3
- Mesa 1.0
- CUDA 11.7
- GCC 11.3
- Python 3.10
- Julia 1.8.2
- Agents.jl 5.5
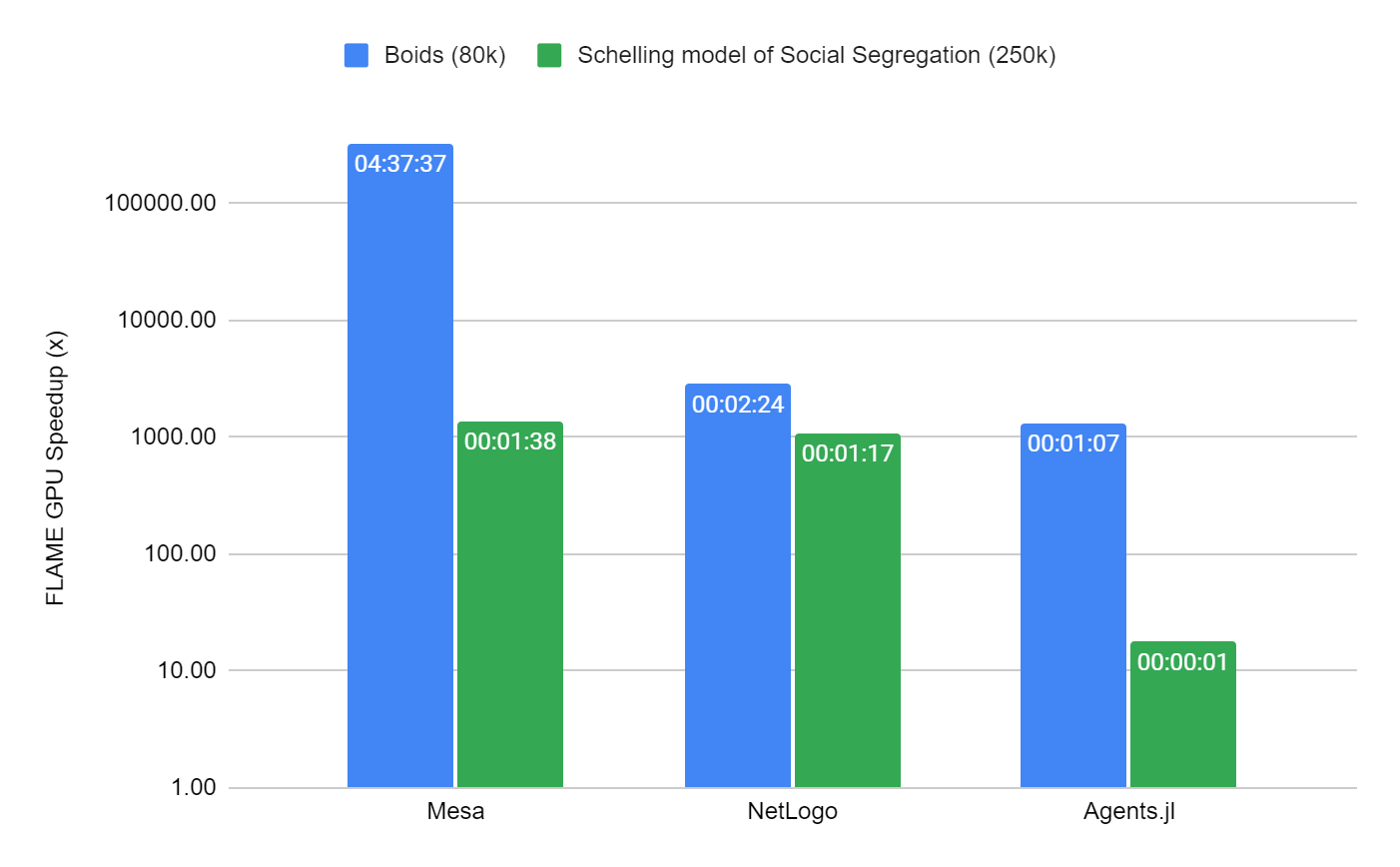
FLAME GPU is at least 1000x faster than the next best simulator (Agents.jl) when considering the performance of the Boids model, and hundreds of thousands of times faster than the worst (Mesa). The simulation time for FLAME GPU was only ~51 milliseconds.
For the Schelling model, FLAME GPU is ~18x faster than the next fastest simulator, Agents.jl, taking ~70 milliseconds, which is more than 1000x faster than NetLogo and Mesa.
The performance of FLAME GPU can be attributed to the ability of FLAME GPU to translate models to exploit the GPUs high levels of parallelism. The framework is designed with parallelism and performance in mind and balances both memory bandwidth and compute to achieve high levels of device utilization.
The FLAME GPU software does require some overhead for the serial initialization of models as well as for CUDA context creation. The other simulators have equivalent overheads, for example, Agents.jl uses just-in-time compilation. Fixed cost overheads can however easily be amortized through models with longer running execution.
FLAME GPU has the potential to vastly increase the performance and scale of simulation available to desktop users. An area of ongoing research activity is considering grand challenge problems where the simulation scale can extend to billions of agents.
One such example is the EU Horizon 2020 PRIMAGE project, which has supported the development of the software. Within this project, FLAME GPU is used to support decision-making and clinical management of neuroblastoma (NB), the most frequent solid cancer of early childhood. The project uses an orchestrated simulation approach to investigate the effect of drug treatment on full tumors with over three billion cells.
Try FLAME GPU today
The FLAME GPU software is open source under an MIT license. It can be downloaded from the FLAMEGPU/FLAMEGPU2 GitHub repo or the FLAME GPU website, which includes build instructions using CMake. You can install a prepackaged Python module hosted on GitHub using pip.
Acknowledgments
Support for this project was provided by the Applied Research Accelerator Program at NVIDIA.
