
This post is the first in a series about optimizing end-to-end AI.
The great thing about the GPU is that it offers tremendous parallelism; it allows you to perform many tasks at the same time. At its most granular level, this comes down to the fact that there are thousands of tiny processing cores that run the same instruction at the same time. But that is not where such parallelism stops. There are other ways that you can leverage parallelism that are often overlooked, particularly when it comes to AI.
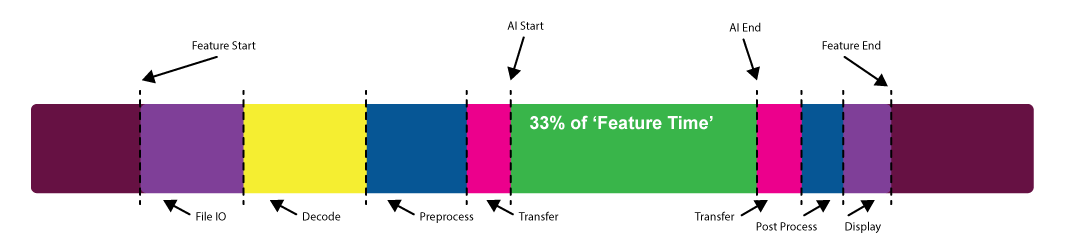
When you consider the performance of an AI feature, what exactly do you mean? Are you just considering the time the model itself takes to run or are you considering the time it takes to load the data, preprocess the data, transfer the data, and write back to disk or display?
This question is perhaps best answered by the user who will experience the feature in question. It can often transpire that the actual model execution time is only a small part of that overall experience.
This post is the first in a series that walks you through several use cases that are specific to APIs, including:
- ONNX Runtime and Microsoft WinML
- NVIDIA TensorRT
- NVIDIA cuDNN
- Microsoft DirectML
AI on workstation is a relatively new phenomenon. It’s traditionally been the stuff of servers and the cloud, but that is changing, particularly in the content creation space. As such, there are many existing code bases now being complemented with new AI features.
One of the first questions to ask when implementing an AI feature is, how do you run inference? What are the constraints? What platforms do you need to support?
Depending on the constraints that you identify, you may choose a DirectML and WinML–based approach or a CUDA and TensorRT–based approach. Whatever approach you choose, you should also consider how to integrate your feature into an existing workflow or pipeline.
Consider a relatively common workflow for generative AI in the content creation space: a denoise feature. To run this denoiser, the following steps must happen:
- Load the model into GPU memory.
- Make input data available to the model.
- Pass the input data through the model.
- Do something with the output data.
There are a lot of ambiguities in this list, so I want to discuss each step.
Load the model into GPU memory
When and how do you do this?
Models come in all sorts of shapes and sizes, from just a few kilobytes to many gigabytes. If your model executes as a part of a long-running pipeline, you may not be able to keep a large model in memory persistently.
Ideally, you would keep the model loading as far from the performance path as possible, but there may be times that this is intractable. You may have to load and unload models as a pipeline runs.
The best-case scenario is to load a model one time and use it as many times as possible. In cases where this can’t be done, most frameworks enable a serialized model to be unloaded and streamed back to the GPU relatively quickly.
Make input data available to the model

This step is where things can get interesting. Usually, this is where there is a lot of low-hanging fruit to improve your performance.
Ultimately, the model expects to consume input data in a specific format. This almost always means a particular scaling and offset, format conversion (for example, UINT8 to FP16), and possibly some layout transformation as well. On NVIDIA hardware, Tensor Cores prefer the NHWC layout.
Often, there is other preprocessing that must be done. Perhaps there is a conversion from or to frequency space or a decode from some compressed format.
This is all work that the GPU can do effectively so it’s important that you allow the GPU to do it. It can be tempting to either allow the CPU to do this work or offload the work to third-party libraries. The latter is a perfectly sensible way to do this. In either case, you must ensure that you minimize the transfers to and from the GPU and speed up the operations themselves. If you are using third-party GPU solutions for pre- and postprocessing, can you ensure that the data remains on the GPU for as long as possible?
In many cases, there may be solutions to preprocessing and format conversion that can be performed by the model itself using native operators. Conversion to FP16, scaling, and offsetting can be performed in most cases by adding those operators to the beginning and end of the model.
However you do your preprocessing, at some point, you will of course have to transfer your input data to the GPU so that the model can consume it. This raises another important consideration.
When your input data is large, you have to perform inference in tiles, if you can. This means that you load a batch of one or more tiles and run inference before loading the next batch.
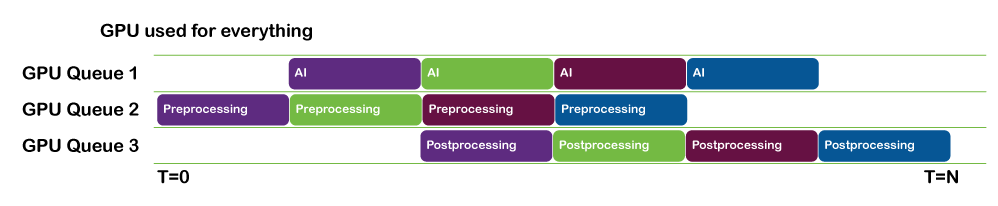
Loading data and running inference can be done in parallel. You can pipeline this work so that by the time batch N has finished inferencing, batch N+1 has finished loading and is ready to be run.
- If you are using NVIDIA CUDA or NVIDIA TensorRT, use CUDA streams to facilitate this.
- If you are using a DML-based inference solution, use DirectX queues in parallel to keep things moving.
Tiling operations such as this are highly parallelizable and a good candidate for performing on the GPU itself. In cases where it is intractable to deal with an entire image in GPU memory, you can split the image up into sections that can be tiled while the next section is streamed onto the GPU.
Pass the input data through the model
To get the best possible performance out of the model by the time that you run the inference itself, make sure that all the following statements are true:
- The input data is provided in the fastest device local memory
- You are making use of the features that NVIDIA hardware provides, such as Tensor Cores.
- The GPU is fully saturated, by which I mean that the GPU is given enough work to keep it busy.
Using the right memory
There are several physical heaps that most GPUs can access. Generally speaking, the programmable heaps are usually one of the following:
- Host-visible
- Lives in system memory and is read over the PCI bus on a PCI system
- You can write to this memory but may not be the fastest for GPU access
- Device-local
- Lives in device (GPU) memory
- Fast memory but you can’t write to this directly
The general workflow to get the fastest memory access is to write your data to host-visible memory. Then, issue a GPU command to copy the data from host-visible to device-local memory
If you are using a CUDA-based platform such as TensorRT or cuDNN, then this is relatively easy to manage as the driver does this for you. However, one thing you can do on the host to speed things up is to use pinned memory on the host. That is, when allocating host memory, use hostAlloc rather than malloc. This enables the GPU DMA to directly dispatch a memory transfer without having to involve a separate CPU transfer into the DMA memory pool, resulting in lower latencies.
If you are using a DirectML-based approach, then you must manage this transfer to fast memory yourself. It is worth the effort, as it gives you full control over exactly when your data is transferred, as well as the opportunity to perform your transfers in parallel with other work.
Saturating the GPU
One commonly overlooked bottleneck when doing any GPU-related work is not giving the GPU enough work to do. When this happens, you may find that there is not enough work to keep all the streaming multiprocessors (SMs) on the GPU busy.
In such cases, strategies such as increasing the spatial dimensions or batch size can help significantly. You may find that a batch size of eight runs at the same speed as a batch size of one.
Just as models can vary in size and complexity, so do GPUs. What is an optimum batch size for one GPU may not be optimal for another. Profiling using NVIDIA NSight Systems can help you identify cases where utilization is low on a given system and help you to design your inferencing strategy accordingly.
Other strategies to keep the GPU busy is to do other compute or even AI work in parallel using multiple CUDA streams or DirectX Command queues.
Every case is unique but both CUDA and DirectML and DirectX provide you with the means to keep the GPU as busy as possible for a given problem.
Do something with the output data
When inference is complete and you have your output, you can apply similar principles as you did for the input data. That is, you can post-process the data in a similar way to the input data, either by adding nodes to your graph or by employing a custom compute step.
If your data must be read back to host memory, this can also be done in parallel with the next inference batch. If your data must go directly to display, then you should avoid any unnecessary round trip to the CPU by making use of the appropriate interop capabilities of the platforms involved (for example, CUDA to OpenGL).
Conclusion
Remember that every case is different and what works well for one particular use case may not work for another.
To read the next posts in this series, see End-to-End AI for NVIDIA-Based PCs: Transitioning AI Models with ONNX and End-to-End AI for NVIDIA-Based PCs: ONNX Runtime and Optimization.
Sign up to learn more about accelerating your creative application with NVIDIA technologies.
