
CUDA Graphs are a way to define and batch GPU operations as a graph rather than a sequence of stream launches. A CUDA Graph groups a set of CUDA kernels and other CUDA operations together and executes them with a specified dependency tree. It speeds up the workflow by combining the driver activities associated with CUDA kernel launches and CUDA API calls. It also enforces the dependencies with hardware accelerations, instead of relying solely on CUDA streams and events, when possible.
CUDA Graphs are particularly important for AI frameworks, as they enable you to capture and replay a sequence of CUDA operations, reducing CPU overhead and improving performance. With the latest improvements, you can now take even greater advantage of CUDA Graphs to accelerate AI workloads.
NVIDIA has improved the performance of CUDA Graphs in several respects between CUDA Toolkit 11.8 and CUDA Toolkit 12.6 and the accompanying driver builds:
- Graph construction and instantiation time
- CPU launch overhead
- General performance in several edge cases
In this post, we present some microbenchmark numbers for various graphs and discuss the improvements since the initial release. The benchmark code is included. As always, performance characteristics depend on the CPU, GPU, and clock settings. For our testing, we used an Intel Xeon Silver 4208 Processor @ 2.10GHz and an NVIDIA GeForce RTX 3060 GPU. The OS was Ubuntu 22.04. The results in this post were collected using default clock settings.
This is a snapshot of performance improvements as of CUDA 12.6, so future CUDA releases may not demonstrate the same performance as documented in this post. This snapshot is presented assuming familiarity with CUDA Graphs and how their performance characteristics impact applications. For more information, see Getting Started with CUDA Graphs.
Definitions
Here are some graph topology terms and performance characteristics discussed later in this post.
- Straight line kernel graph: A CUDA Graph made completely out of kernel nodes, where every node has a single dependent node except for the last node.
- Parallel straight line: A CUDA Graph that has width as the number of entry points. Each entry point is followed by its own set of lengths as the number of nodes arrayed in a straight-line formation. This is also referred to as parallel chain in the charts and source code.
- First launch: The first launch of a graph, which also includes uploading the instantiated graph to the device.
- Repeat launch: Launching a graph that has already been uploaded to the device.
- CPU overhead for a launch: CPU time between invoking
CUDAGraphLaunchand the completion of the function. - Device side runtime: The amount of time for the operation to run on the device.
- Repeat launch device side runtime: The amount of time it takes for a graph that was previously uploaded to run on the device.
- Time to solution: Time from the launch call to the completion of the graph running on the device.
Constant time CPU overhead for repeat launch
One notable improvement highlighted is related to CPU overhead for repeat launch on the NVIDIA Ampere architecture. For straight-line kernel graphs, there has been a significant reduction in time taken during repeat launches. Specifically, the time decreased from 2μs + 200 ns extra time per node to a nearly constant time of 2.5us + (~1ns per node), showcasing consistent speed enhancements for graphs with 10 nodes or more.
Launch still takes \(O(n)\) time on pre-NVIDIA Ampere architecture hardware.


Because the parallel straight-line graphs measured here have four root nodes, the repeat launch with one node takes 6μs instead of 2μs. The impact of chain length on the CPU launch overhead is still negligible for this topology. The exact scaling of having multiple root nodes is not analyzed here, although the impact is expected to be linear with the number of root nodes. Similarly, graphs with non-kernel nodes would have different performance characteristics.
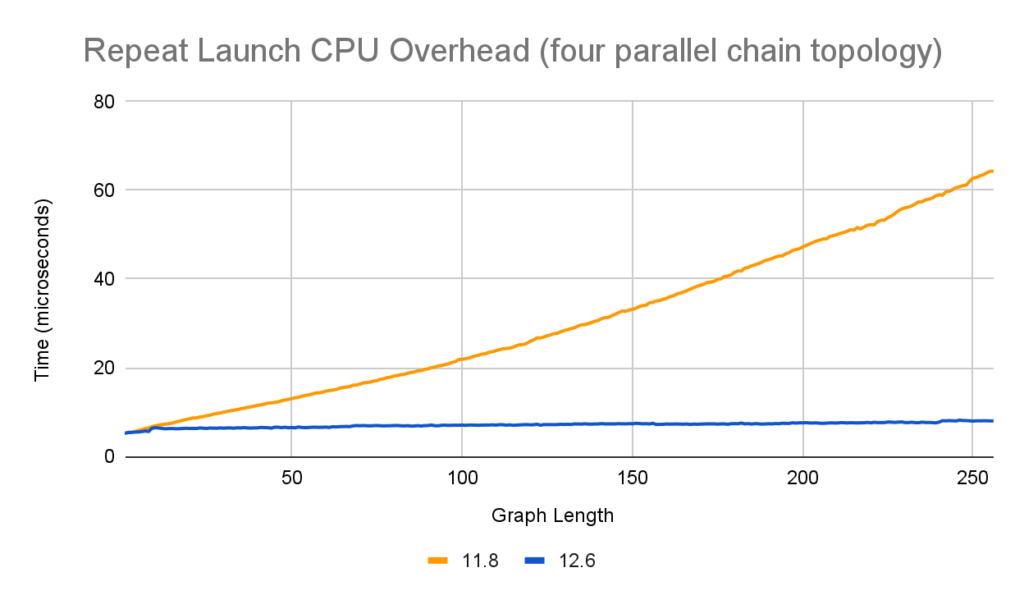
Other measurable performance gains
Several other aspects of performance can matter for applications benefitting from graphs:
- Instantiation time
- First launch CPU overhead
- Repeat launch device runtime
- End-to-end time for repeat graph launch into an empty stream
| metric | topology | Topology length | 11.8 (r520.61.05) | 12.6 (r560.28.03) | %speedup |
| Instantiation | Straight line | 10 | 20 uS | 16 uS | 25% |
| 100 | 168 uS | 127 uS | 32% | ||
| 1025 | 2143 uS | 1526 uS | 40% | ||
| 4 parallel chains | 10 | 71 uS | 58 uS | 22% | |
| 100 | 695 uS | 552 uS | 26% | ||
| First Launch Cpu Overhead | Straight line | 10 | 4 uS | 4uS | 0% |
| 100 | 25 uS | 15 uS | 66% | ||
| 1025 | 278 uS | 175 uS | 59% | ||
| 4 parallel chains | 100 | 73 uS | 67 uS | 9% | |
| Repeat Launch Device Runtime | Straight line | 10 | 7 uS | 7 uS | 0% better |
| 100 | 61 uS | 53 uS | 15% better | ||
| 1025 | 629 uS | 567 uS | 11% better | ||
| End to end time for repeat graph launch into an empty stream | Straight line | 10 | 12 uS | 9 uS | 30% better |
| 100 | 69 uS | 55 uS | 25% better | ||
| 1025 | 628 uS | 567 uS | 11% better |
Instantiation time
The amount of time to instantiate a graph dominates the runtime cost of adopting a graph. This is a one-time cost per graph instantiation. Graph creation time often appears on the critical path of application startup or for workflows that need to periodically create new graphs at times they do not have work running on the GPU.
Improvements here can impact application startup time for applications that prepare many graphs at program start and minimize the end-to-end latency penalty to other applications that file to hide graph construction latency behind other work execution.
First launch CPU overhead
As first launch is responsible for uploading the work descriptions for a CUDA Graph to the GPU, it still has an \(O(N)\) CPU cost. This cost is paid the first time and doesn’t need to be repaid except partially when the graph is updated. Most of this cost can be paid by performing a separate upload operation, which is not discussed in this post because it’s already available to CUDA Graphs users.
Repeat launch device runtime
Running even empty kernels takes time. Optimizing some inter-kernel latency for straight-line graphs reduces device times by up to a noticeable 60 ns/node.
End-to-end time for repeat graph launch into an empty stream
CUDA Graphs contains logic that may allow execution to begin before the launch operation processes all the nodes in a graph, hiding part of the launch cost. Due to this, the launch overhead benefits aren’t fully seen in the time to work completion.
Instead, you see a more modest improvement of about 60ns/node benefit in time to solution for straight line graphs.
Scheduling based on node creation order
In CUDA Toolkit 12.0, CUDA started paying attention to node creation order as a heuristic to scheduling decisions. CUDA started loosely preferring to schedule node operations for nodes created earlier over nodes created later.
Specifically, the order of the root nodes was fixed and a pass that ordered the nodes by a breadth-first traversal was removed. The logic originally was designed to keep root nodes at the start of the graph’s node list and to prioritize making parallel work available for the GPU to run.
In cases where memcopy operations would be assigned to the same copy engine and falsely serialize, the old heuristic would often wind up unintentionally serializing the memcopy operations needed for the first compute items after memcopy operations that were only needed for later compute tasks. This caused the graph to have bubbles in the work available to the compute engines. So, developers often created the graph nodes in a deliberate order: nodes needed early in the graph were created first and nodes needed later were created later.
By paying attention to node creation order when making some scheduling decisions, CUDA can give you scheduling that better matches your intuitive expectations.
Microbenchmark source code
The microbenchmarks code has been added to the /NVIDIA/cuda-samples as the cudaGraphsPerfScaling application. Compile the app and run the dataCollection.bash script with your GPU name and CUDA driver version to generate the data.
Summary
New optimizations to CUDA graphs make a compelling argument for seeing if they translate to real performance improvements in applications using graphs.
In this post, we discussed CUDA Graphs performance improvements after CUDA 11.8. These improvements include enhancements in graph construction and instantiation time, CPU launch overhead, and overall performance in various scenarios.
For more information, see the following resources:
- Getting Started with CUDA Graphs
- CUDA C++ Programming Guide: CUDA Graphs
- CUDA Runtime API: Graph Management
- A Guide to CUDA Graphs in GROMACS
- Employing CUDA Graphs in a Dynamic Environment
- Constructing CUDA Graphs with Dynamic Parameters
- CUDA Graphs (OLCF presentation)
- Accelerating PyTorch with CUDA Graphs
