

One year ago today, NVIDIA announced the NVIDIA® DGX-1™, an integrated system for deep learning. DGX-1 (shown in Figure 1) features eight Tesla P100 GPU accelerators connected through NVLink, the NVIDIA high-performance GPU interconnect, in a hybrid cube-mesh network. Together with dual socket Intel Xeon CPUs and four 100 Gb InfiniBand network interface cards, DGX-1 provides unprecedented performance for deep learning training. Moreover, the DGX-1 system software and powerful libraries are tuned for scaling deep learning on its network of Tesla P100 GPUs to provide a flexible and scalable platform for the application of deep learning in both production and research settings.
To celebrate the first birthday of DGX-1 , NVIDIA is releasing a detailed new technical white paper about the DGX-1 system architecture. This white paper includes an in-depth look at the hardware and software technologies that make DGX-1 the fastest platform for deep learning training. In this post, I will summarize those technologies, but make sure to read the DGX-1 white paper for complete details.
, NVIDIA is releasing a detailed new technical white paper about the DGX-1 system architecture. This white paper includes an in-depth look at the hardware and software technologies that make DGX-1 the fastest platform for deep learning training. In this post, I will summarize those technologies, but make sure to read the DGX-1 white paper for complete details.
DGX-1 System Architecture
DGX-1 is a deep learning system architected for high throughput and high interconnect bandwidth to maximize neural network training performance. The core of the system is a complex of eight Tesla P100 GPUs connected in a hybrid cube-mesh NVLink network topology. (For more details about the NVIDIA Pascal-architecture-based Tesla P100, see the post Inside Pascal.) In addition to the eight GPUs, DGX-1 includes two CPUs for boot, storage management and deep learning framework coordination. DGX-1 is built into a three-rack-unit (3U) enclosure that provides power, cooling, network, multi-system interconnect and SSD file system cache, balanced to optimize throughput and deep learning training time. Figure 2 shows the DGX-1 system components.
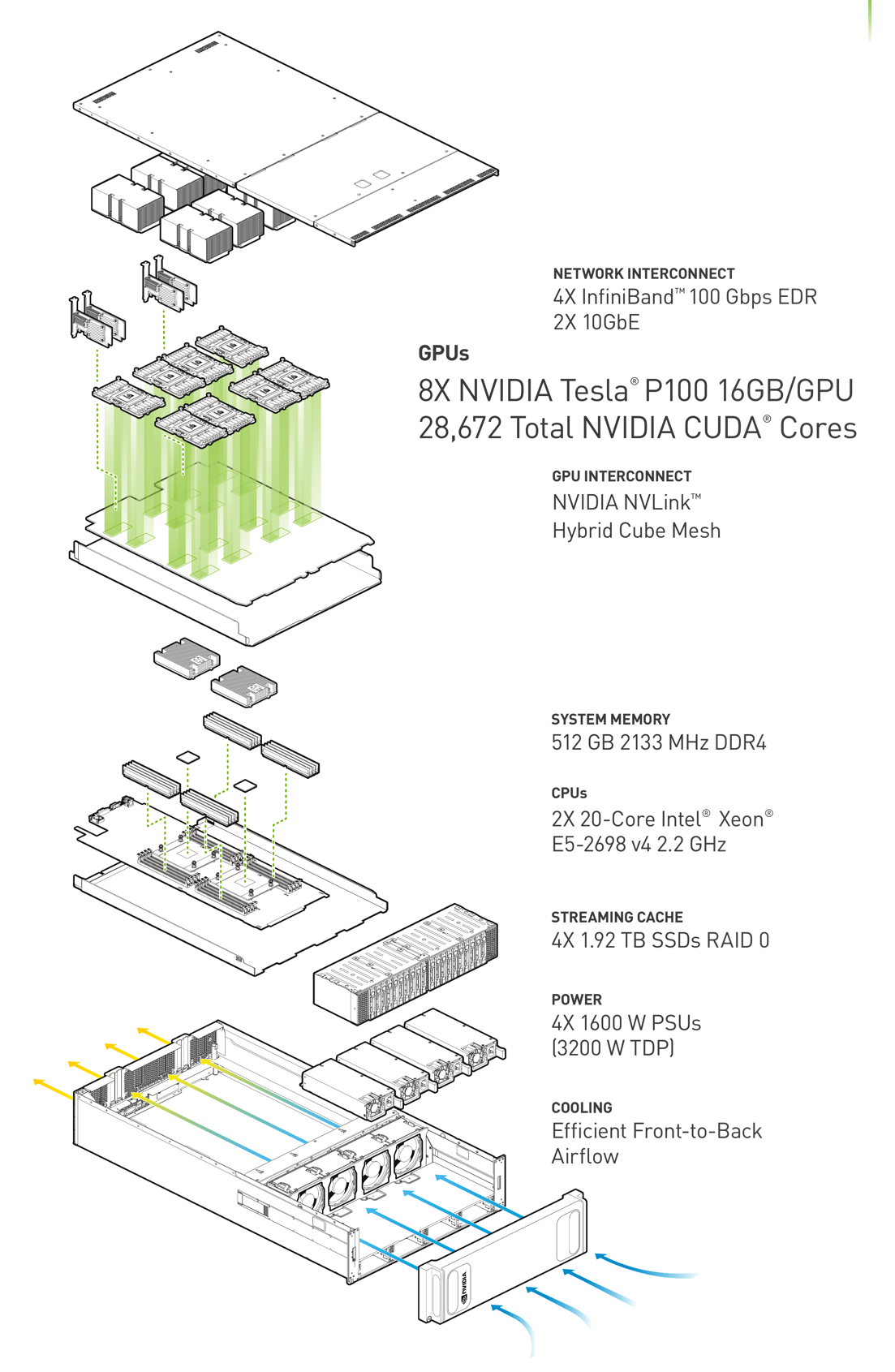
NVLink is an energy-efficient, high-bandwidth interconnect that enables NVIDIA Pascal GPUs to connect to peer GPUs or other devices within a node at an aggregate bidirectional bandwidth of 160 GB/s per GPU: roughly five times that of current PCIe Gen3 x16 interconnections. The NVLink interconnect and the DGX-1 architecture’s hybrid cube-mesh GPU network topology enable the highest bandwidth data interchange between a group of eight Tesla P100 GPUs.
Tesla P100’s Page Migration Engine allows high bandwidth, low overhead sharing of data between the GPUs and bulk host memory. For scaling to many-node high-performance clusters, DGX-1 provides high system-to-system bandwidth through InfiniBand (IB) networking.
NVLink for Efficient Deep Learning Scaling

To provide the highest possible computational density, DGX-1 includes eight NVIDIA Tesla P100 accelerators (Figure 3). Application scaling on this many highly parallel GPUs is hampered by today’s PCIe interconnect. NVLink provides the communications performance needed to achieve good (weak and strong) scaling on deep learning and other applications. Each Tesla P100 GPU has four NVLink connection points, each providing a point-to-point connection to another GPU at a peak bandwidth of 20 GB/s. Multiple NVLink connections can be bonded together, multiplying the available interconnection bandwidth between a given pair of GPUs. The result is that NVLink provides a flexible interconnect that can be used to build a variety of network topologies among multiple GPUs. Pascal also supports 16 lanes of PCIe 3.0. In DGX-1, these are used for connecting between the CPUs and GPUs. PCIe is also used for high-speed networking interface cards.
The design of the NVLink network topology for DGX-1 aims to optimize a number of factors, including the bandwidth achievable for a variety of point-to-point and collective communications primitives, the flexibility of the topology, and its performance with a subset of the GPUs. The hybrid cube-mesh topology (Figure 4) can be thought of as a cube with GPUs at its corners and with all twelve edges connected through NVLink, and with two of the six faces having their diagonals connected as well. It can also be thought of as two interwoven rings of single NVLink connections.
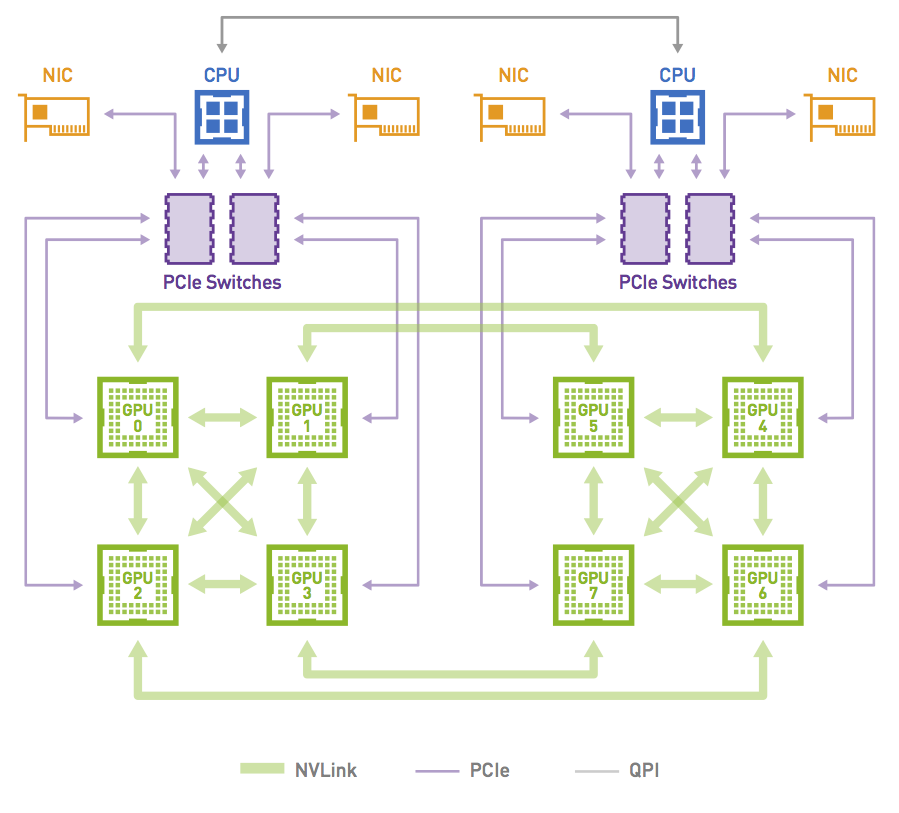
Figure 5 shows deep learning training performance and scaling on DGX-1. The bars in Figure 5 represent training performance in images per second for the ResNet-50 deep neural network architecture using the Microsoft Cognitive Toolkit (CNTK), and the lines represent the parallel speedup of 2, 4, or 8 P100 GPUs versus a single GPU. The tests used a minibatch size of 64 images per GPU.
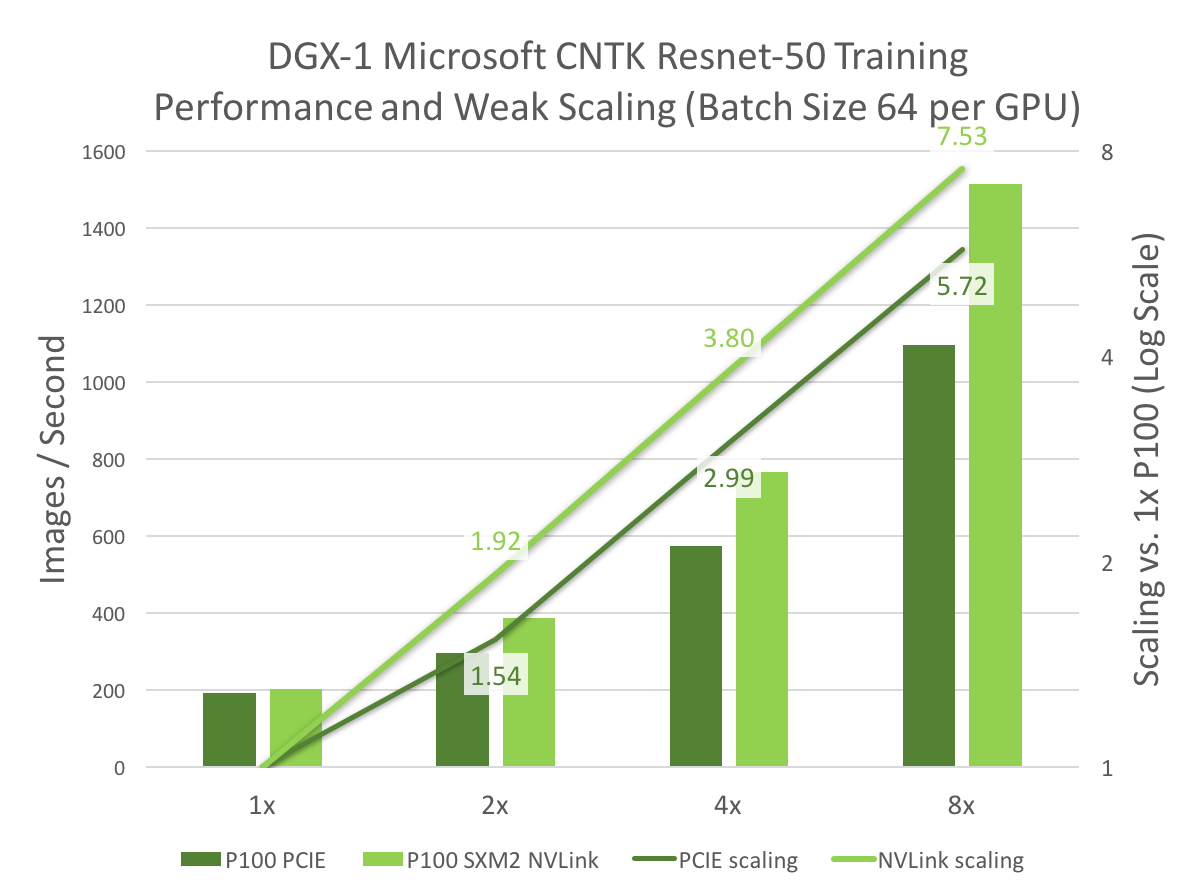
The benefits of NVLink show clearly when comparing deep learning training using 1, 2, 4 and 8 GPUs on PCIe (tree topology) to the 8-GPU hybrid cube-mesh NVLink interconnect of DGX-1, as Figure 5 shows. NVLink really shines in the 4x and 8x cases, where DGX-1 aggregates multiple NVLink connections in a way that cannot be done with PCIe, achieving nearly 1.4x total speedup vs. PCIe. Not only does the DGX-1 architecture’s NVLink interconnect achieve better scaling than PCIe, the NVLink hybrid cube-mesh network topology provides the best overall scaling for deep learning, compared to alternative NVLink network configurations such as a ring topology.
InfiniBand for Multi-System Scaling of DGX-1 Systems
Multi-system scaling of the latest computational workloads, especially deep learning, requires strong communications between GPUs both inside the system and between systems to match the significant GPU performance of each system. In addition to NVLink for high speed communication internally between GPUs, DGX-1 also uses Mellanox ConnectX-4 EDR InfiniBand ports to provide significant bandwidth between systems and reduce bottlenecks. The latest InfiniBand standard, EDR IB, configured in DGX-1 provides:
- For each port, 8 data lanes operating at 25 Gb/s or 200 Gb/s total (4 lanes in (100 Gb/s) and 4 lanes out (100 Gb/s) simultaneously);
- Low-latency communication and built-in primitives and collectives to accelerate large computations across multiple systems;
- High performance network topology support to enable data transfer between multiple systems simultaneously with minimal contention;
- NVIDIA GPUDirect RDMA across InfiniBand for direct transfers between GPUs in multiple systems.
DGX-1 comes configured with four EDR IB ports providing 800 Gb/s (400 Gb/s in and 400 Gb/s out of the system simultaneously) that can be used to build a high-speed cluster of DGX-1 systems. Four EDR IB ports balance intra- and inter-node bandwidth, and in certain use cases can be fully consumed by inter-node communication. When compared to typical networking technologies such as Ethernet, InfiniBand provides twenty times the bandwidth and four times lower latency even across a large multi-system cluster (see the white paper for details).
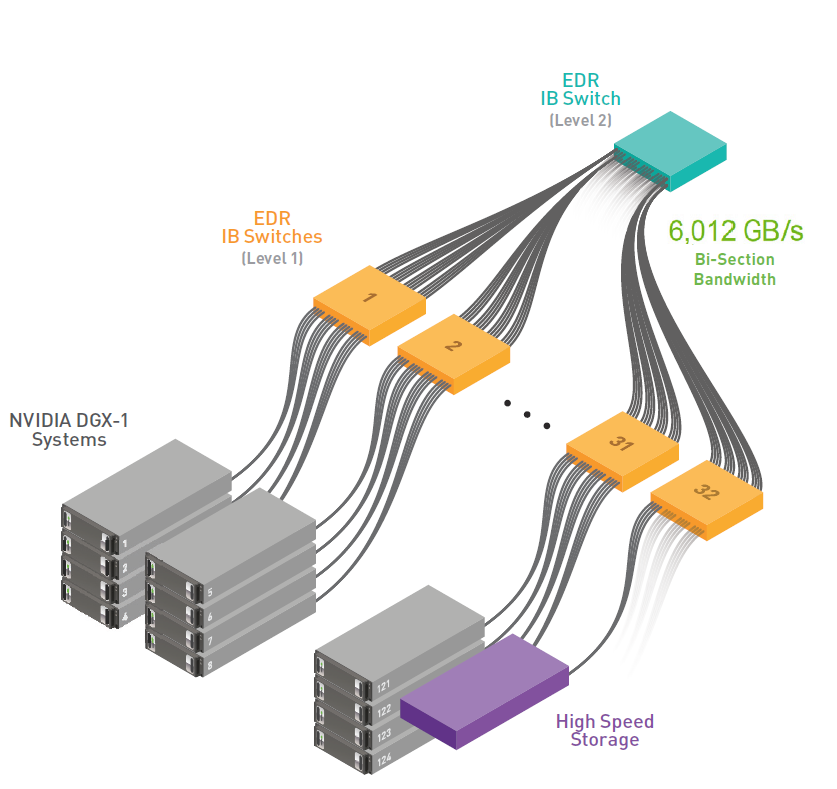
The latest DGX-1 multi-system clusters use a network based on a fat tree topology providing well-routed, predictable, contention-free communication from each system to every other system (see Figure 6). A fat tree is a tree-structured network topology with systems at the leaves that connect up through multiple switch levels to a central top-level switch. Each level in a fat tree has the same number of links providing equal bandwidth. The fat tree topology ensures the highest communication bisection bandwidth and lowest latency for all-to-all or all-gather type collectives that are common in computational and deep learning applications.
DGX-1 Software
The DGX-1 software has been built to run deep learning at scale. A key goal is to enable practitioners to deploy deep learning frameworks and applications on DGX-1 with minimal setup effort. The design of the platform software is centered around a minimal OS and driver install on the server, and provisioning of all application and SDK software in NVIDIA Docker containers through the DGX Container Registry, maintained by NVIDIA. Containers available for DGX-1 include multiple optimized deep learning frameworks, the NVIDIA DIGITS deep learning training application, third party accelerated solutions, and the NVIDIA CUDA Toolkit. Figure 7 shows the DGX-1 deep learning software stack.
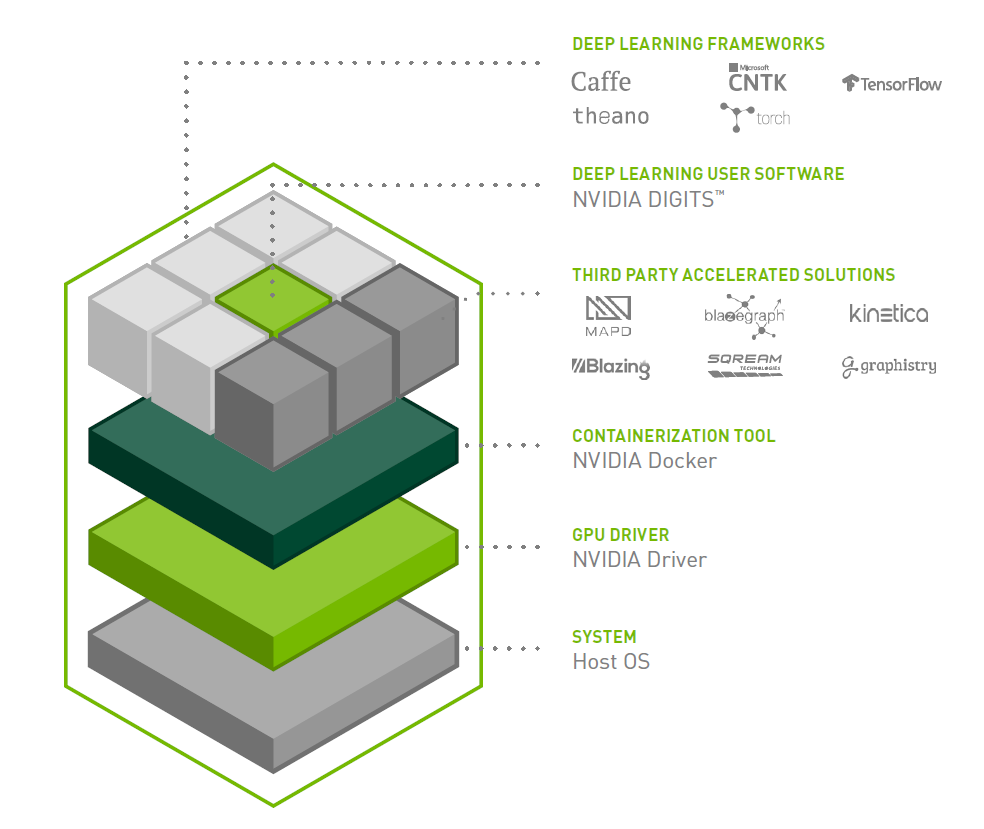
The DGX-1 software stack includes the following major components.
- The NVIDIA CUDA Toolkit. Read about what’s new in the CUDA Toolkit version 8.0.
- NVIDIA Docker, a wrapper around the popular Docker containerization engine that transparently provisions a container with the necessary components to execute code on the GPU. Click here for a detailed blog post about NVIDIA Docker.
- The NVIDIA Deep Learning SDK, which provides powerful tools and libraries for designing and deploying GPU-accelerated deep learning applications. It includes libraries for deep learning primitives (cuDNN), inference (TensorRT), video analytics, linear algebra (cuBLAS), sparse matrices (cuSPARSE), and more.
- The NVIDIA Collective Communication Library (NCCL, pronounced “Nickel”), a library of topology-aware multi-GPU collective communication primitives. NVIDIA Docker containers for DGX-1 include a version of NCCL that optimizes these collectives for the DGX-1 architecture’s 8-GPU hybrid cube-mesh NVLink network. Learn more about NCCL in this Parallel Forall blog post.
- Deep Learning Frameworks for DGX-1. The NVIDIA Deep Learning SDK accelerates widely-used deep learning frameworks such as Caffe, CNTK, MXNet, TensorFlow, Theano, and Torch. The DGX-1 software stack provides containerized versions of these frameworks optimized for the system. These frameworks, including all necessary dependencies, are pre-built, tested, and ready to run. For users who need more flexibility to build custom deep learning solutions, each framework container image also includes the framework source code to enable custom modifications and enhancements, along with the complete software development stack.
DGX-1 Provides the Highest Deep Learning Performance
The performance of DGX-1 for training popular deep neural networks speaks volumes about the value of an integrated system for deep learning. The graph in Figure 8 shows the training speedup of DGX-1 compared to an off-the shelf system with the same GPUs for the ResNet-50 and ResNet-152 deep neural networks using the Microsoft Cognitive Toolkit, TensorFlow, and Torch. This graph demonstrates two clear benefits:
- The P100 GPUs in DGX-1 achieve much higher throughput than the previous-generation NVIDIA Tesla M40 GPUs for deep learning training.
- DGX-1 achieves significantly higher performance than a comparable system with eight Tesla P100 GPUs interconnected using PCIe.
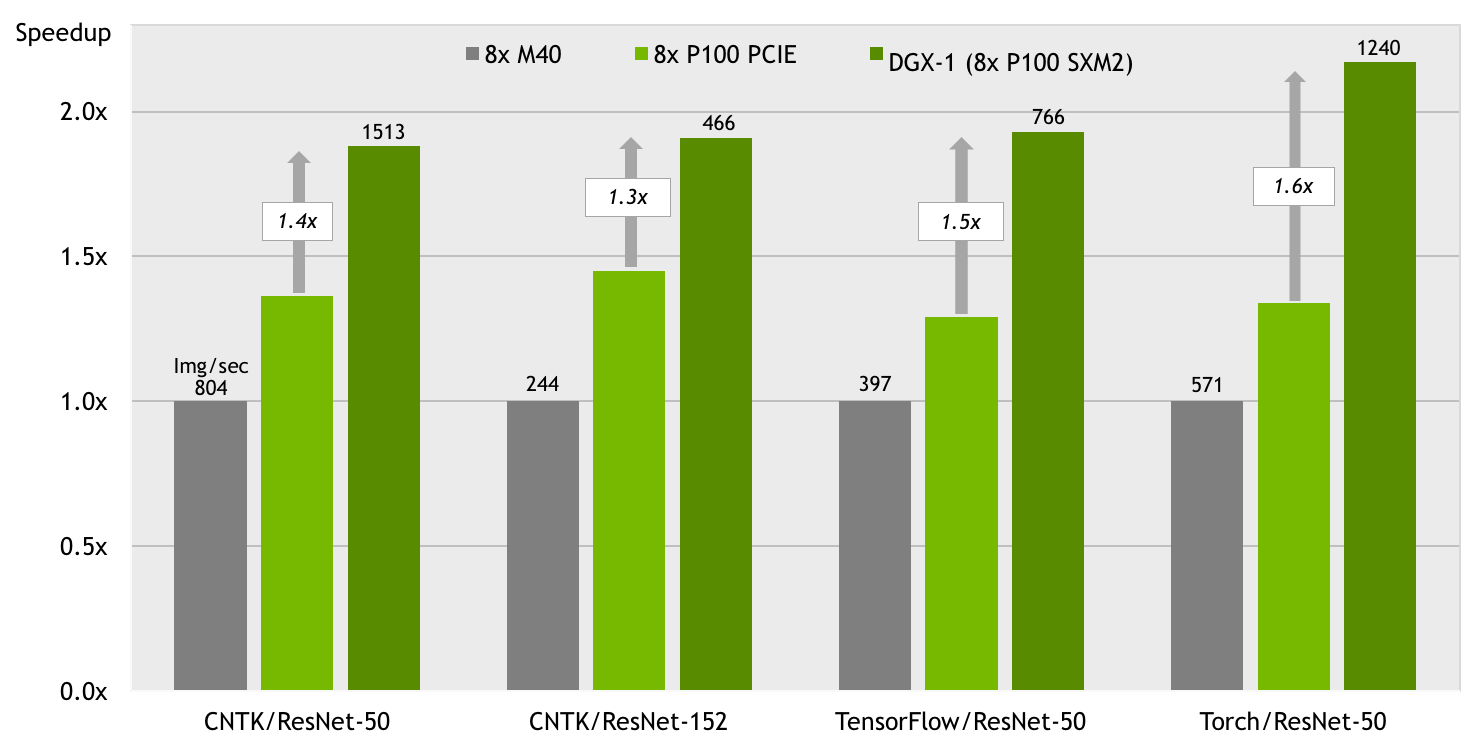
The high performance of DGX-1 is due in part to the NVLink hybrid cube-mesh interconnect between its eight Tesla P100 GPUs, but that is not the whole story. Much of the performance benefit of DGX-1 comes from the fact that it is an integrated system, with a complete software platform aimed at deep learning. This includes the deep learning framework optimizations such as those in NVIDIA Caffe, cuBLAS, cuDNN, and other GPU-accelerated libraries, and NVLink-tuned collective communications through NCCL. This integrated software platform, combined with Tesla P100 and NVLink, ensures that DGX-1 outperforms similar off-the-shelf systems.
The NVIDIA DGX-1 white paper contains much more detail on the system architecture, platform software, and performance of DGX-1. Download the NVIDIA DGX-1 white paper today.
For more on DGX-1, visit NVIDIA DGX-1.