
GPUs have been PCIe devices for many generations in client systems, and more recently in servers. The rapid growth in deep learning workloads has driven the need for a faster and more scalable interconnect, as PCIe bandwidth increasingly becomes the bottleneck at the multi-GPU system level. As deep learning neural networks become more sophisticated, their size and complexity will continue to expand, as will the data sets they ingest to deliver meaningful insights. This expansion will in turn drive demand for compute, as well as memory capacity to further accelerate deep learning innovations.
In addition to general growth of workloads, there are a number of emerging techniques that will also require more GPUs that can quickly communicate with one another. Advanced approaches such as model parallel training, which involves training different parts of the AI model in parallel, have been developed but require large memory and extremely fast connections between GPUs to work. A critical operation of deep learning training is for GPUs to exchange updated model weights, biases and gradients so that all GPUs working on a network remain synchronized. This operation necessitates significant memory traffic to complete these exchanges. In HPC, large FFTs are a key workload for seismic imaging, defense or life sciences, a single NVIDIA DGX-2 system can be up to 2.4 faster than two DGX-1 system. NVIDIA’s new DGX-2 brings a 16-GPU system to market, and NVIDIA’s new NVSwitch technology is the backbone of this system.

NVSwitch is implemented on a baseboard as six chips, each of which is an 18-port, NVLink switch with an 18×18-port fully-connected crossbar. Each baseboard has six NVSwitch chips on it, and can communicate with another baseboard to enable 16-GPUs in a single server node.
Read the NVSwitch technical overview for more details.
Each NVSwitch chip has the following:
Vital Statistics:
| Port Configuration | 18 NVLINK ports |
| Speed per Port | 50 GByte/s per NVLINK port (total for both directions) |
| Connectivity | Fully-connected crossbar internally |
| Transistor Count | 2 billion |
Each of the eight GPUs on one baseboard are connected using a single NVLink to each of six NVSwitch chips on the baseboard. Eight ports on each of the NVSwitch chips are used to communicate with the other baseboard. Each of eight GPUs on a baseboard can communicate with any of the other GPUs on the baseboard at full bandwidth of 300 GB/sec with a single NVSwitch traversal.
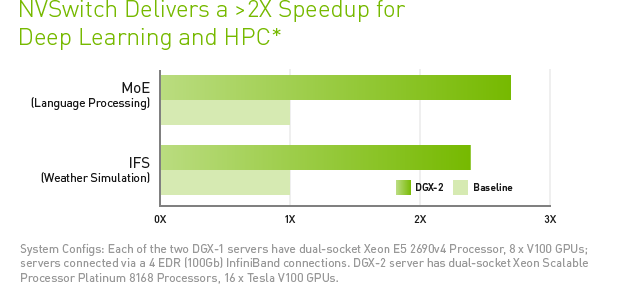
With the continuing explosive growth of neural networks’ size, complexity and designs, it’s difficult to predict the exact form those networks will take, but one thing remains certain: the appetite for deep learning compute will continue to grow along with it. In the HPC domain, workloads like weather modeling using large-scale, FFT-based computations will also continue to drive demand for compute horsepower. And with a 16-GPU configuration with 2 petaFLOPS of compute horsepower and a half-terabyte of GPU memory in a unified address space, applications can scale up without requiring knowledge of the underlying physical topology.
Learn more >