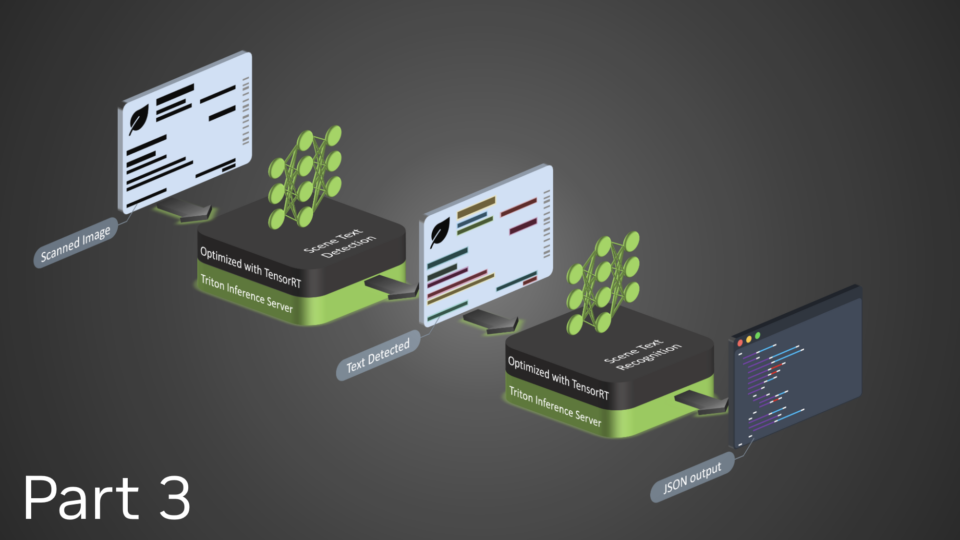
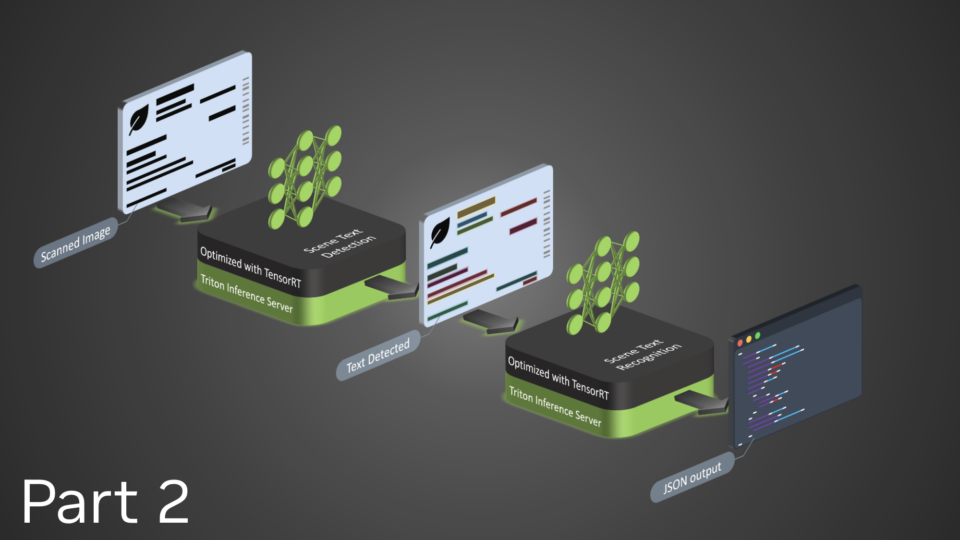
NVIDIA Triton Inference Server streamlines and standardizes AI inference by enabling teams to deploy, run, and scale trained ML or DL models from any framework on any GPU- or CPU-based infrastructure. It helps developers deliver high-performance inference across cloud, on-premises, edge, and embedded devices.
The nvOCDR library is integrated into Triton for inference. The nvOCDR library wraps the entire inference pipeline for optical character detection and recognition (OCD/OCR). This library consumes OCDNet and OCRNet models that are trained on TAO Toolkit. For more details, refer to the nvOCDR documentation.
This post is part of a series on using NVIDIA TAO and pretrained models to create and deploy custom AI models to accurately detect and recognize handwritten texts. Part 1 explains the training and fine-tuning of character detection and recognition models using TAO. This part walks you through the steps to deploy the model using NVIDIA Triton. The steps presented can be used with any other OCR tasks.
Build the Triton sample with OCD/OCR models
The following steps show the simple and recommended way to build and use OCD/OCR models in Triton Inference Server with Docker images.
Step 1: Prepare the ONNX models
Once you follow ocdnet.ipynb and ocrnet.ipynb to finish the model training and export, you could get two ONNX models, such as ocdnet.onnx and ocrnet.onnx. (In ocdnet.ipynb, the exported ONNX is named model_best.onnx. In ocrnet.ipynb, the exported ONNX is named best_accuracy.onnx.)
# bash commands
$ mkdir onnx_models
$ cd onnx_models
$ cp <ocd results dir>/export/model_best.onnx ./ocdnet.onnx
$ cp <ocr results dir>/export/best_accuracy.onnx ./ocrnet.onnx
The character list file, generated in ocrnet.ipynb, is also needed:
$ cp <ocr DATA_DIR>/character_list ./Step 2: Get the nvOCDR repository
To get the nvOCDR repository, use the following script:
$ git clone https://github.com/NVIDIA-AI-IOT/NVIDIA-Optical-Character-Detection-and-Recognition-Solution.gitStep 3: Build the Triton server Docker image
The building process of Triton server and client Docker images can be launched automatically by running related scripts:
$ cd NVIDIA-Optical-Character-Detection-and-Recognition-Solution/triton
# bash setup_triton_server.sh [input image height] [input image width] [OCD input max batchsize] [DEVICE] [ocd onnx path] [ocr onnx path] [ocr character list path]
$ bash setup_triton_server.sh 1024 1024 4 0 ~/onnx_models/ocd.onnx ~/onnx_models/ocr.onnx ~/onnx_models/ocr_character_listStep 4: Build the Triton client Docker image
Use the following script to build the Triton client Docker image:
$ cd NVIDIA-Optical-Character-Detection-and-Recognition-Solution/triton
$ bash setup_triton_client.sh
Step 5: Run nvOCDR Triton server
After building the Triton server and Triton client docker image, create a container and launch the Triton server:
$ docker run -it --net=host --gpus all --shm-size 8g nvcr.io/nvidian/tao/nvocdr_triton_server:v1.0 bashNext, modify the config file of nvOCDR lib. nvOCDR lib can support high-resolution input images (4000 x 4000 or larger). If your input images are large, you can change the configure file to /opt/nvocdr/ocdr/triton/models/nvOCDR/spec.json in the Triton server container to support the high resolution images inference.
# to support high resolution images
$ vim /opt/nvocdr/ocdr/triton/models/nvOCDR/spec.json
"is_high_resolution_input": true,
"resize_keep_aspect_ratio": true,
The resize_keep_aspect_ratio will be set to True automatically if you set the is_high_resolution_input to True. If you are going to infer images that have smaller resolution (640 x 640 or 960 x 1280, for example) you can set the is_high_resolution_input to False.
In the container, run the following command to launch the Triton server:
$ CUDA_VISIBLE_DEVICES=<gpu idx> tritonserver --model-repository /opt/nvocdr/ocdr/triton/models/
Step 6: Send an inference request
In a separate console, launch the nvOCDR example from the Triton client container:
$ docker run -it --rm -v <path to images dir>:<path to images dir> --net=host nvcr.io/nvidian/tao/nvocdr_triton_client:v1.0 bash
Launch the inference:
$ python3 client.py -d <path to images dir> -bs 1

Conclusion
NVIDIA TAO 5.0 introduced several features and models for Optical Character Detection (OCD) and Optical Character Recognition (OCR). This post walks through the steps to customize and fine-tune the pretrained model to accurately recognize handwritten texts on the IAM dataset. This model achieves 90% accuracy for character detection and about 80% for character recognition. All the steps mentioned in the post can be run from the provided Jupyter notebook, making it easy to create custom AI models with minimal coding.
For more information, see: