
Speech recognition technology is growing in popularity for voice assistants and robotics, for solving real-world problems through assisted healthcare or education, and more. This is helping democratize access to speech AI worldwide. As labeled datasets for unique, emerging languages become more widely available, developers can build AI applications readily, accurately, and affordably to enhance technology developments and experiences for their native regions.
Kinyarwanda is the native language of 9.8 million people in Rwanda, Uganda, DR Congo, and Tanzania with over 20 million total speakers across the globe.
In April 2022, Mozilla Common Voice (MCV), a crowdsourced project aimed at making voice recognition open and accessible to everyone, made a significant contribution to building the Kinyarwanda dataset, as detailed in the article, Lessons from Building for Kinyarwanda on Common Voice. It is a 57 GB dataset with 2,000+ hours of audio, making it the largest dataset on the MCV platform.
To bring the value of the effort and dataset to developers, an automatic speech recognition (ASR) model was trained on this dataset that achieved state-of-the-art performance on the published checkpoints.
This post provides an overview of the training process using NeMo ASR toolkit. It briefly covers challenges with the dataset, converting characters to longer units using byte-pair encoding, and the training process for improved model performance. Developers can refer to the step-by-step tutorial on GitHub for the reference code and details.
Obtaining the dataset
MCV has the largest publicly available multi-language dataset. You can download language-specific datasets from the Mozilla Common Voice Hub.
In the Kinyarwanda dataset used for the model, there are 1,404,853 sentences that are pre-split into train/dev/test data. Each entry in the dataset consists of a unique MP3 file and corresponding information such as name of the file, transcription, and meta information in TSV format.
NeMo ASR requires data that includes a set of utterances in individual audio files plus a manifest that describes the dataset, with information about one utterance per line.
Once the dataset is downloaded, in the training split, TSV files are converted to JSON manifests and MP3 files are converted to WAV files, which are recommended formats for NeMo toolkit. The same steps are then repeated for test and dev data separately.
The manifest format is provided below:
{"audio_filepath": "/path/to/audio.wav", "text": "the transcription of the utterance", "duration": 23.147}Data preprocessing
Before training the model, the data requires preprocessing to reduce ambiguity and inconsistencies and make the data easy to interpret. The preprocessing steps for this model are:
- Replace all punctuation with a space (except for apostrophes)
- Replace different types of apostrophes [’’‘`ʽ’] by 1
- Make all text lowercase for consistency
- Replace rare characters with diacritics ([éèëēê] → e, for example)
- Delete all remaining out-of-vocabulary characters
(combined Latin letters, space, and apostrophe, for example)
Because 99% of the dataset has an audio duration of 11 seconds or shorter, it is suggested to restrict the maximum audio duration to 11 seconds during preprocessing for faster training.
The final Kinyarwanda transcript consists of sentences with Latin letters, spaces, and apostrophes after preprocessing.
Subword tokenization
It is possible to train character-based ASR models but they will regard each letter as a separate token, taking more time to generate the output. Using longer units improves both quality and speed.
This process involves a tokenization algorithm called byte-pair encoding that splits words into subtokens and marks the beginning of the word with a special symbol so it’s easy to restore the original words.
To make the process easier, NeMo toolkit supports on-the-fly subword tokenization by passing the tokenizer through the model config so there is no need to modify transcripts. This does not affect the model performance and potentially helps to adapt to other domains without retraining the tokenizer.
Visit NVIDIA/NeMo on GitHub for a detailed description and tutorial on subword tokenization for NeMo ASR.
Training models
Two approaches lead to trained model. The first approach involves training the model from scratch using two model architectures: Conformer-CTC and Conformer-Transducer. The second approach involves
fine-tuning the Kinyarwanda Conformer-Transducer model from different pretrained checkpoints.
To train a Conformer-CTC model, use speech_to_text_ctc_bpe.py with the default config conformer_ctc_bpe.yaml. To train a Conformer-Transducer model, use speech_to_text_rnnt_bpe.py with the default config conformer_transducer_bpe.yaml.
For fine-tuning, use the pretrained STT_EN_Conformer_Transducer model for a checkpoint that is not self-supervised. Use the SSL_EN_Conformer_Large for a self-supervised checkpoint from NVIDIA GPU Cloud.
You can find more details about the training process in the step-by-step tutorial on GitHub.
The reference code for Self-supervised Checkpoint Initialization (SSL_EN_Conformer_Large) is provided below.
import nemo.collections.asr as nemo_asr
ssl_model = nemo_asr.models.ssl_models.SpeechEncDecSelfSupervisedModel.from_pretrained(model_name='ssl_en_conformer_large')
# define fine-tune model
asr_model = nemo_asr.models.EncDecCTCModelBPE(cfg=cfg.model, trainer=trainer)
# load ssl checkpoint
asr_model.load_state_dict(ssl_model.state_dict(), strict=False)
del ssl_model
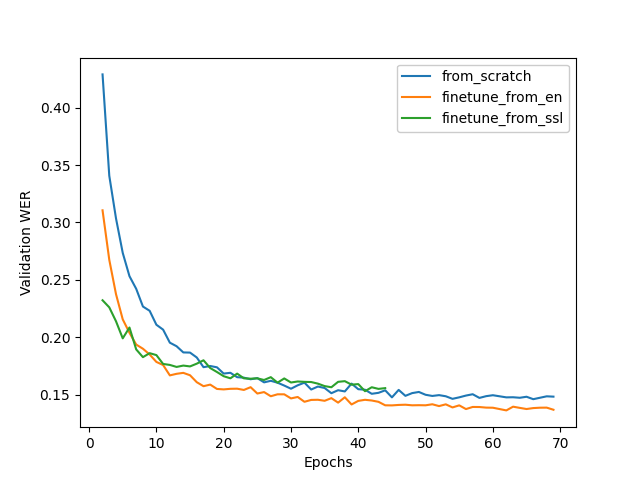
Figure 1 shows a comparison of training dynamics. The fine-tuning approach is quick and easy for training, and also leads to faster convergence and better quality.
Test results
While building a model, the goal is to minimize the Word Error Rate (WER) while transcribing the speech input. In simple words, Word Error Rate is the number of errors divided by the total number of words. It is often used to test the performance of a model but should not be the only standard, as out-of-scope variables like noise, echo, and accents can have a substantial impact on speech recognition.
Character Error Rate (CER) is also considered. CER gives the percentage of characters that were incorrectly predicted. Our models have the lowest percentage of WER and CER in the Kinyarwanda ASR models (Table 1).
| Model | WER % | CER % |
| Conformer-CTC-Large | 18.73 | 5.75 |
| Conformer-Transducer-Large | 16.19 | 5.7 |
Key takeaways
We have built two high-quality Kinyarwanda checkpoints from scratch with the NeMo toolkit. The Conformer-Transducer checkpoint has better quality but the Conformer-CTC is 4x faster at inference, so they are both potentially useful based on the need.
The high performance of the pretrained model is another step towards new developments in the speech AI community. The state-of-the-art model can be improved further by fine-tuning it with more data that has more dialects, accents, and rare words and is a true representation of how people speak their native languages. NVIDIA NeMo pretrained models are open source and meet the goal of democratization and inclusivity across the globe.
Additional resources
Explore the MVC initiative to access or provide voice data for your language. For more information on models, see the following resources:
- Explore NeMo ASR Collection on NVIDIA GPU Cloud and download the model
- Download NeMo pretrained models
- Browse NeMo toolkit on GitHub for sample codes, examples, and tutorials
Join experts from Google, Meta, NVIDIA, and more at the first annual NVIDIA Speech AI Summit. Register now.
