
NVIDIA and Mozilla are proud to announce the latest release of the Common Voice dataset, with over 13,000 hours of crowd-sourced speech data, and adding another 16 languages to the corpus.
Common Voice is the world’s largest open data voice dataset and designed to democratize voice technology. It is used by researchers, academics, and developers around the world. Contributors mobilize their own communities to donate speech data to the MCV public database, which anyone can then use to train voice-enabled technology. As part of NVIDIA’s collaboration with Mozilla Common Voice, the models trained on this and other public datasets are made available for free via an open-source toolkit called NVIDIA NeMo.
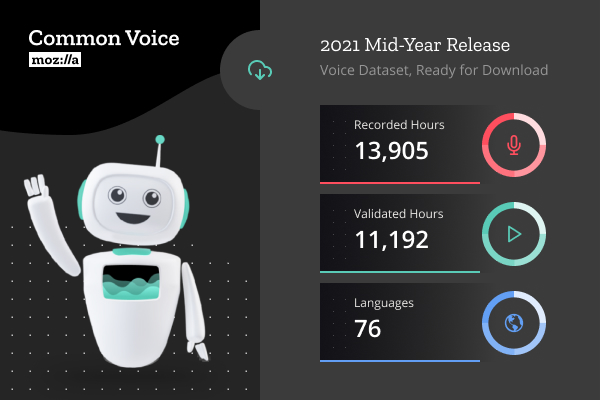
Highlights of this release include:
- Common Voice dataset release is now 13,905 hours, an increase of 4,622 hours from the previous release.
- Introduces 16 new languages to the Common Voice dataset: Basaa, Slovak, Northern Kurdish, Bulgarian, Kazakh, Bashkir, Galician, Uyghur, Armenian, Belarusian, Urdu, Guarani, Serbian, Uzbek, Azerbaijani, Hausa.
- The top five languages by total hours are English (2,630 hours), Kinyarwanda (2,260), German (1,040), Catalan (920), and Esperanto (840).
- Languages that have increased the most by percentage are Thai (almost 20x growth, from 12 hours to 250 hours), Luganda (9x growth, from 8 hours to 80 hours), Esperanto (more than 7x growth, from 100 hours to 840 hours), and Tamil (more than 8x growth, from 24 hours to 220 hours).
- The dataset now features over 182,000 unique voices, a 25% growth in contributor community in just six months.
Pretrained Models:
NVIDIA has released multilingual speech recognition models in NGC for free as part of the partnership mission to democratize voice technology. NeMo is an open-source toolkit for researchers developing state-of-the-art conversational AI models. Researchers can further fine-tune these models on multilingual datasets. See an example in this notebook that fine tunes an English speech recognition model on the MCV Japanese dataset.
Contribute Your Voice, and Validate Samples:
The dataset relies on the amazing effort and contribution from many communities across the world. Take the time to feed back into the dataset by recording your voice and validating samples from other contributors: https://commonvoice.mozilla.org/speak
You can download the latest MCV dataset from https://commonvoice.mozilla.org/datasets, including the repo for full stats https://github.com/common-voice/cv-dataset/, and NVIDIA NeMo from NGC Catalog and GitHub.
Dataset ‘Ask Me Anything’:
August 4, 2021 from 3:00 – 4:00 p.m. UTC / 2:00 – 3:00 p.m. EDT / 11:00 a.m. – 12:00 p.m. PDT:
In celebration of the dataset release, on August 4th Mozilla is hosting an AMA discussion with Lead Engineer Jenny Zhang. Jenny will be available to answer your questions live, to join and ask a question please use the following AMA discourse topic.
