
This is the fourth post in the Accelerating IO series. It addresses storage issues and shares recent results and directions with our partners. We cover the new GPUDirect Storage release, benefits, and implementation.
Accelerated computing needs accelerated IO. Otherwise, computing resources get starved for data. Given that the fraction of all workflows for which data fits in memory is shrinking, optimizing storage IO is of increasing importance. The value of stored data, efforts to pilfer or corrupt data, and regulatory requirements to protect it are also all ratcheting up. To that end, there is growing demand for data center infrastructure that can provide greater isolation of users from data that they shouldn’t access.
GPUDirect Storage
GPUDirect Storage streamlines the flow of data between storage and GPU buffers for applications that consume or produce data on the GPU without needing CPU processing. No extra copies that add latency and impede bandwidth are needed. This simple optimization leads to game-changing role reversals where data can be fed to GPUs faster from remote storage rather than CPU memory.
The newest member of the GPUDirect family
The GPUDirect family of technologies enables access and efficient data movement into and out of the GPU. Until recently, it was focused on memory-to-memory transfers. With the addition of GPUDirect Storage (GDS), access and data movement with storage are also accelerated. GPUDirect Storage makes the significant step of adding file IO between local and remote storage to CUDA.
Release v1.0 with CUDA 11.4
GPUDirect Storage has been vetted for more than two years and is currently available as production software. Previously available only through a separate installation, GDS is now incorporated into CUDA version 11.4 and later, and it can be either part of the CUDA installation or installed separately. For an installation of CUDA version X-Y, the libcufile-X-Y.so user library, gds-tools-X-Y are installed by default and the nvidia-fs.ko kernel driver is an optional install. For more information, see the GDS troubleshooting and installation documentation.
GDS is now available in RAPIDS. It is also available in a PyTorch container and an MXNet container.
GDS description and benefits
GPUDirect Storage enables a direct datapath between storage and GPU memory. Data is moved using the direct memory access (DMA) engine in local NVMe drives or in a NIC that communicates with remote storage.
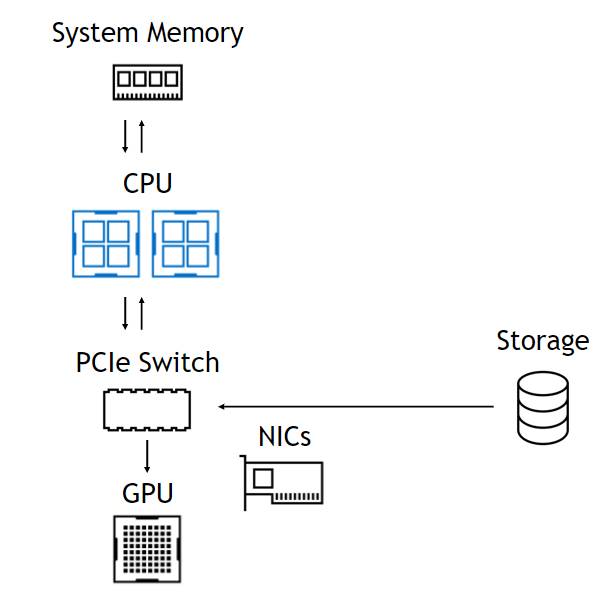
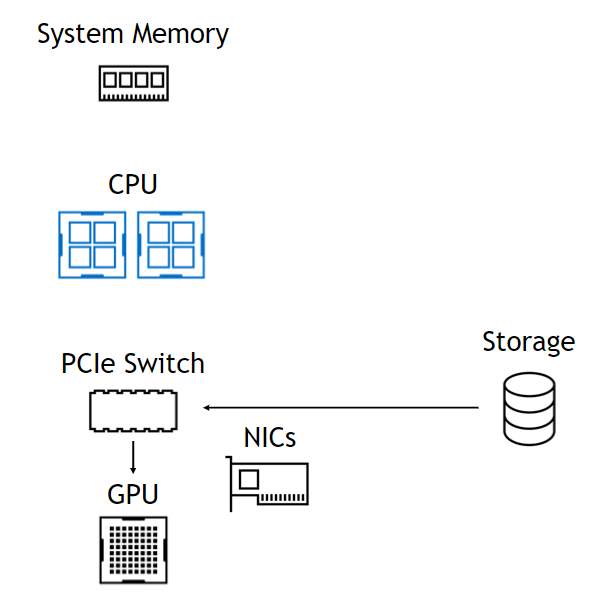
Use of that DMA engine means that, although the setup of the DMA is a CPU operation, the CPU and GPU are totally uninvolved in the datapath, leaving them free and unencumbered (Figure 1). On the left, data from storage comes in through a PCIe switch, goes through the CPU to system memory and all the way back down to the GPU. On the right, the datapath skips the CPU and system memory. The benefits are summarized at the bottom.
WITHOUT GPUDIRECT STORAGE
Limited by bandwidth into and out of the CPU. Incurs the latency of a CPU bounce buffer. Memory capacity is limited to O(1TB). Storage is not part of CUDA. No topology-based optimization.
WITH GPUDIRECT STORAGE
Bandwidth into GPUs limited only by NICs. Lower latency due to direct copy. Access to O(PB) capacity. Simple CUDA programming model. Adaptively route through NVLink, GPU buffers.
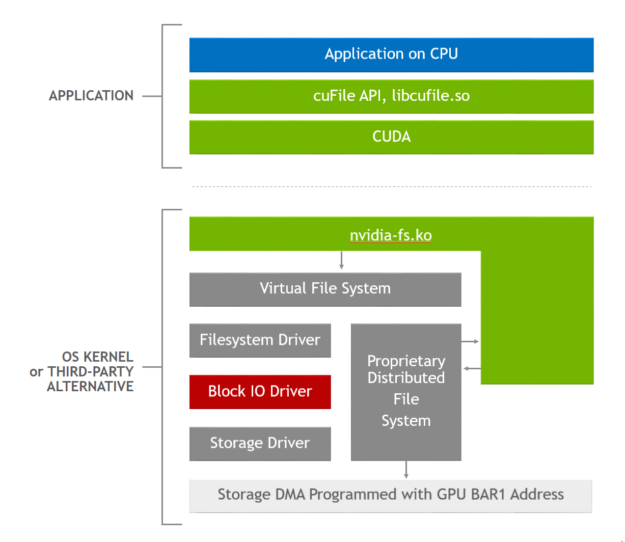
Figure 1. GDS software stack, where the applications use cuFile APIs, and the GDS-enabled storage drivers call out to the nvidia-fs.ko kernel driver to obtain the correct DMA address.
GPUDirect storage offers three basic performance benefits:
- Increased bandwidth: By removing the need to go through a bounce buffer in the CPU, alternate paths become available on some platforms, including those that may offer higher bandwidth through a PCIe switch or over NVLink. While DGX platforms have both PCIe switches and NVLinks, not all platforms do. We recommend using both to maximize performance. The Mars lander example achieved an 8x bandwidth gain.
- Decreased latency: Reduce latency by avoiding the delay of an extra copy through CPU memory and the overhead of managing memory, which can be severe in extreme cases. A 3x reduction in latency is common.
- Decreased CPU utilization: Use of a bounce buffer introduces extra operations on the CPU, both to perform the extra copy and to manage the memory buffers. When CPU utilization becomes the bottleneck, effective bandwidth can drop significantly. We’ve measured 3x improvements in CPU utilization with multiple file systems.
Without GDS, there’s only one available datapath: from storage to the CPU and from the CPU to the relevant GPU with cudaMemcpy. With GDS, there are additional optimizations available:
- The CPU threads used to interact with the DMA engine are affinitized to the closest CPU core.
- If the storage and GPU hang off different sockets and NVLink is an available connection, then data may be staged through a fast bounce buffer in the memory of a GPU near the storage, and then transferred using CUDA to the final GPU memory target buffer. This can be considerably faster than using the intersocket path, for example, UPI.
- There is no
cudaMemcpyinvolved to take care of segmenting the IO transfer to fit in the GPU BAR1 aperture, whose size varies by GPU SKU, or into prepinned buffers in case the target buffer is not pinned withcuFileBufRegister. These operations are managed with thelibcufile.souser library code. - Handle unaligned accesses, where the offset of the data within the file to be transferred does not align with a page boundary.
- In future GDS releases, the
cuFileAPIs will support asynchronous and batched operations. This enables a CUDA kernel to be sequenced after a read in the CUDA stream that provides inputs to that kernel, and a write to be sequenced after a kernel that produces data to be written. In time,cuFileAPIs will be usable in the context of CUDA Graphs as well.
Table 1 shows the peak and measured bandwidths on NVIDIA DGX-2 and DGX A100 systems. This data shows that the achievable bandwidth into GPUs from local storage exceeds the maximum bandwidth from up to 1 TB of CPU memory in ideal conditions. Commonly measured bandwidths from petabytes of remote memory can be well more than double of the bandwidth that CPU memory provides in practice.
Spilling data that won’t fit in GPU memory out to even petabytes of remote storage can exceed the achievable performance of paging it back to the 1 TB of memory in the CPU. This is a remarkable reversal of history.
| Endpoint | DGX-2 (Gen3), GB/s | DGX A100 (Gen4), GB/s | |
| CPU | 50, peak | 100, peak | |
| Switch/GPU | 100, peak | 200*, peak | |
| Endpoint | Capacity | Measured | |
| CPU sysmem | O(1TB) | 48-50 @ 4 PCIe | 96-100 @ 4 PCIe |
| Local storage | O(100TB) | 53+ @ 16 drives | 53+ @ 8 drives |
| RAID cards | O(100TB) | 112 (MicroChip) @ 8 | N/A |
| NICs | O(1PB) | 90+ @ 8 NICs | 185+ @ 8 NICs |
Table 1. Access to petabytes of data is possible at bandwidths that exceed those to only 1 TB of CPU memory.
* Performance numbers shown here with NVIDIA GPUDirect Storage on NVIDIA DGX A100 slots 0-3 and 6-9 are not the officially supported network configuration and are for experimental use only. Sharing the same network adapters for both compute and storage may impact the performance of standard or other benchmarks previously published by NVIDIA on DGX A100 systems.
How GDS works
NVIDIA seeks to embrace existing standards wherever possible, and to judiciously extend them where necessary. The POSIX standard’s pread and pwrite provide copies between storage and CPU buffers, but do not yet enable copies to GPU buffers. This shortcoming of not supporting GPU buffers in the Linux kernel will be addressed over time.
A solution, called dma_buf, that enables copies among devices like a NIC or NVMe and GPU, which are peers on the PCIe bus, is in progress to address that gap. In the meantime, the performance upside from GDS is too large to wait for an upstreamed solution to propagate to all users. Alternate GDS-enabled solutions have been provided by a variety of vendors, including MLNX_OFED (Table 2). The GDS solution involves new APIs, cuFileRead or cuFileWrite, that are similar to POSIX pread and pwrite.
Optimizations like dynamic routing, use of NVLink, and async APIs for use in CUDA streams that are only available from GDS makes the
cuFileAPIs an enduring feature of the CUDA programming model, even after gaps in the Linux file system are addressed.
Here’s what the GDS implementation does. First, the fundamental problem with the current Linux implementation is passing a GPU buffer address as a DMA target down through the virtual file system (VFS) so that the DMA engine in a local NVMe or a network adapter can perform a transfer to or from GPU memory. This leads to an error condition. We have a way around this problem for now: Pass down an address for a buffer in CPU memory instead.
When the cuFile APIs like cuFileRead or cuFileWrite are used, the libcufile.so user-level library captures the GPU buffer address and substitutes a proxy CPU buffer address that’s passed to VFS. Just before the buffer address is used for a DMA, a call from a GDS-enabled driver to nvidia-fs.ko identifies the CPU buffer address and provides a substitute GPU buffer address again so that the DMA can proceed correctly.
The logic in libcufile.so performs the various optimizations described earlier, like dynamic routing, use of prepinned buffers, and alignment. Figure 2 shows the stack used for this optimization. The cuFile APIs are an example of the Magnum IO architectural principles of flexible abstraction that enable platform-specific innovation and optimization, like selective buffering and use of NVLink.
To learn more
The GPUDirect Storage post was the original introduction to GPUDirect Storage. We recommend the NVIDIA GPUDirect Storage Design Guide to end customers and OEMs, and the NVIDIA GPUDirect Storage Overview Guide to end customers, OEMs, and partners. For more information about programming with GDS, see the cuFile API Reference Guide.
