
In this post, we dive deeper into each of the GPU-accelerated indexes mentioned in part 1 and give a brief explanation of how the algorithms work, along with a summary of important parameters to fine-tune their behavior.
We then go through a simple end-to-end example to demonstrate cuVS’ Python APIs on a question-and-answer problem with a pretrained large language model and provide a performance comparison of cuVS’ algorithms against HNSW for a few different scenarios involving different numbers of query vectors being passed to the search algorithm concurrently.
This post provides:
- An overview of vector search index algorithms that can be used with GPUs
- An end-to-end example demonstrating how easy it can be to run vector search on the GPU with Python
- Performance comparison of vector search on the GPU against HNSW, the current state-of-the-art method on the CPU
The first post in this series introduced vector search indexes, explained the role they play in enabling a widespread range of important applications, and provided a brief overview of vector search on the GPU with the cuVS library. For more information, see Accelerating Vector Search: Using GPU-Powered Indexes with RAPIDS cuVS.
The third post in this series focuses on IVF-Flat, an ANN algorithm found in RAPIDS cuVS. We discuss how the algorithm works, and demonstrate the usage of both the Python and C++ APIs in cuVS. We cover setting parameters for index building and give tips on how to configure GPU-accelerated IVF-Flat search. For more information, see Accelerated Vector Search: Approximating with RAPIDS cuVS IVF-Flat.
Vector search indexes
When working with vector search, the vectors are often converted to an indexed format that is optimized for fast lookups. Choosing the right indexing algorithm is important as it can affect both index build and search times. Furthermore, each different index type comes with its own set of knobs for fine-tuning the behavior, trading off index construction time, storage cost, search quality, and search speed.
When the right indexing algorithm is paired with the correct parameter settings, vector search on the GPU provides both faster build and search times for all levels of recall.
IVF-Flat
As it’s the simplest index type, start with the IVF-Flat algorithm. In this algorithm, a set of training vectors are first split into some clusters and then stored in the GPU memory organized by their closest cluster centers. The index-building step is faster than that of other algorithms presented in this post, even at high numbers of clusters.
To search an IVF-Flat index, the closest clusters to each query vector are selected, and the k-nearest neighbors (k-NN) are computed from each of those closest clusters. Because IVF-Flat stores the vectors in an exact, or flat format, meaning without compression, it has the advantage of computing exact distances within each of the clusters it searches. As we describe later in this post, this provides an advantage that often has a higher recall than IVF-PQ when the same number of closest clusters are searched. IVF-Flat index is a good choice when the full index can fit in GPU memory.
cuVS’ IVF-Flat index contains a couple of parameters to help trade off the query performance and accuracy:
- When training the index, the
n_listsparameter determines the number of clusters to partition the training dataset. - The search parameter
n_probesdetermines the number of closest clusters to search through to compute the nearest neighbors for a set of query points.
In general, a smaller number of probes leads to a faster search at the expense of recall. When the number of probes is set to the number of lists, exact results are computed. However, in that case, a call to cuVS’ brute-force search is more performant.
IVF-PQ
When your dataset becomes too large to fit on the GPU, you gain some mileage by compressing the vectors using the IVF-PQ index type. Like IVF-Flat, IVF-PQ splits the points into a number of clusters (also specified by a parameter called n_lists) and searches the closest clusters to compute the nearest neighbors (also specified by a parameter called n_probes), but it shrinks the sizes of the vectors using a technique called product quantization.
Compressing the index ultimately allows for more vectors to be stored on the GPU. The amount of compression can be controlled with tuning parameters, which we describe later in this post, but higher levels of compression can provide a faster lookup time at the cost of recall. IVF-PQ is currently cuVS’ most memory-efficient vector index.
cuVS’ IVF-PQ provides two parameters that control memory usage:
pq_dimsets the target dimensionality of the compressed vector.pq_bitssets the number of bits for each vector element after compression.
We recommend setting the former to a multiple of 32 while the latter is limited to a range of 4-8 bits. By default, cuVS selects a dimensionality value that minimizes quantization loss according to pq_bits, but this value can be adjusted to lower the memory footprint for each vector. It is useful to play with these parameters to see which settings work best for you.
When using large amounts of compression, an additional refinement step can be performed by querying the IVF-PQ index for a larger number of neighbors than needed and computing an exact search over the resulting neighbors to reduce the set down to the final desired number. The refinement step requires the original uncompressed dataset on the host memory.
For more information about building an IVF-PQ index, with in-depth details and recommendations, see the complete guide to cuVS IVF-PQ notebook on our GitHub repo.
CAGRA
CAGRA is cuVS’ new state-of-the-art ANN index. It is a high-performance, GPU-accelerated, graph-based method that has been specifically optimized for small-batch cases, where each lookup contains only one or a few query vectors. Like other popular graph-based methods, such as hierarchical navigable small-world graphs (HNSW) and SONG, an optimized k-NN graph is built at index training time with various qualities that yield efficient search at reasonable levels of recall.
CAGRA performs a search by first randomly selecting candidate vertices from the graph and then expanding, or traversing, those vertices to compute distances to their children, storing off the nearest neighbors along the way (Figure 1). Each time it traverses a set of vertices, it has performed one iteration.
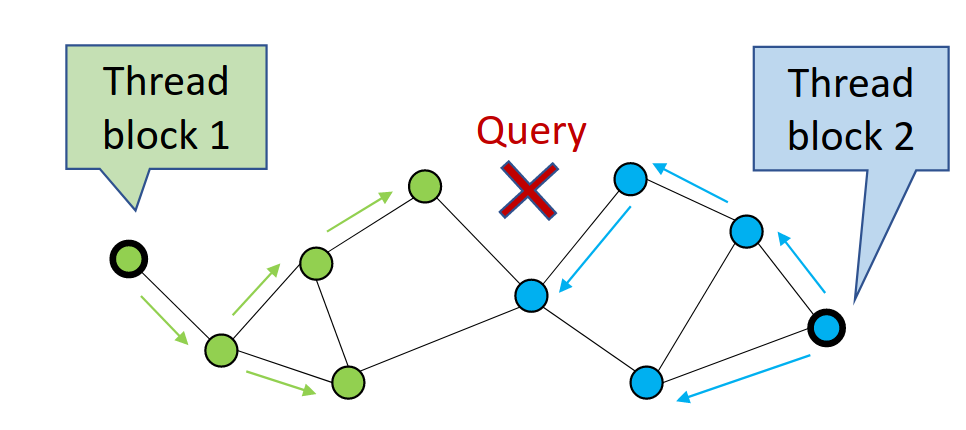
In Figure 1, CAGRA is using multiple thread blocks to visit more graph nodes in parallel. This is maximizing GPU utilization for single-query searches.
Because CAGRA returns the approximate nearest neighbors like the algorithms described earlier, it also provides a few parameters to control the recall and the speed.
The main parameter that can be adjusted to trade off search speed is itopk_size, which specifies the size of an internal sorted list that stores the nodes that can be explored in the next iteration. Higher values of itopk_size keep a larger search context in memory that improves recall at the cost of more time spent in maintaining the queue.
The parameter search_width defines the number of the closest parent vertices that are traversed to expand their children in each search iteration.
Another useful parameter is the number of iterations to perform. The setting is selected automatically by default, but this can be changed to a higher or lower value to trade off recall for a faster search.
CAGRA’s optimized graph is fixed-degree, which is tuned using the parameter graph_degree. The fixed-degree makes better use of GPU resources by keeping the number of computations uniform when searching the graph. It builds the initial k-NN graph by computing an actual k-NN, for example by using IVF-PQ explained earlier, to compute the nearest neighbors of all the points in the training dataset.
The number of k-nearest neighbors (k) of this intermediate k-NN graph can be tuned using a parameter called intermediate_graph_degree to trade off the quality of the final searchable CAGRA graph.
A higher quality graph can be built with a larger intermediate_graph_degree value, which means that the final optimized graph is more likely to find nearest neighbors that yield a high recall. cuVS provides several useful parameters to tune the CAGRA algorithm. For more information, see the CAGRA API documentation.
Again, this parameter can be used to control how thoroughly the overall space is covered by the search but again this comes at the cost of having to search more to find the nearest neighbors, which reduces the search performance.
Getting started with the cuVS Python library
The cuVS lightweight python library allows us to use cuVS’ ANN algorithms for vector search right in Python. cuvs can accept any object that supports “__cuda_array_interface__” such as Torch or CuPy array.
The following example briefly demonstrates how you can build and query a cuVS CAGRA index with cuVS.
from cuvs.neighbors import cagra
import cupy as cp
# On small batch sizes, using "multi_cta" algorithm is efficient
index_params = cagra.IndexParams(graph_degree=32)
search_params = cagra.SearchParams(algo="multi_cta")
corpus_embeddings = cp.random.random((1500,96), dtype=cp.float32)
query_embeddings = cp.random.random((1,96), dtype=cp.float32)
cagra_index = cagra.build(index_params, corpus_embeddings)
# Find the 10 closest vectors
hits = cagra.search(search_params, cagra_index, query_embeddings, k=10)
With the recent success of LLMs, semantic search is a perfect way to showcase vector similarity search in action using cuVS. In the following example, a DistilBERT transformer model combined with each of the three ANN indexes is used to solve a simple question retrieval problem. The Simple English Wikipedia dataset is used to answer the user’s search query.
The language model first transforms the training sentences into vector embeddings that are inserted into a cuVS ANN index. The inference is done by encoding the query and using our trained ANN index to find vectors similar to the encoded query vector. The answer that you return to the user is the nearest article in Simple Wikipedia, which you fetch using the closest vector from the similarity search.
You can get started with cuVS by installing the cuVS Python package and using the example notebook below for a question retrieval task:
Benchmarks
Using GPU as a hardware accelerator for your vector search application can lead to an increase in performance, and it is best showcased on large datasets. The benchmarks can be fully reproduced by following cuVS end-to-end benchmark documentation. Our benchmarks consider that the data is already available for computation, which means that data transfer is not taken into consideration, although this should not be a significant difference thanks to the high transfer speed of recent NVIDIA hardware (over 25 GB/s).
We used the DEEP-100M dataset on an H100 GPU to compare cuVS indexes with HNSW running on an Intel Xeon Platinum 8480CL CPU.
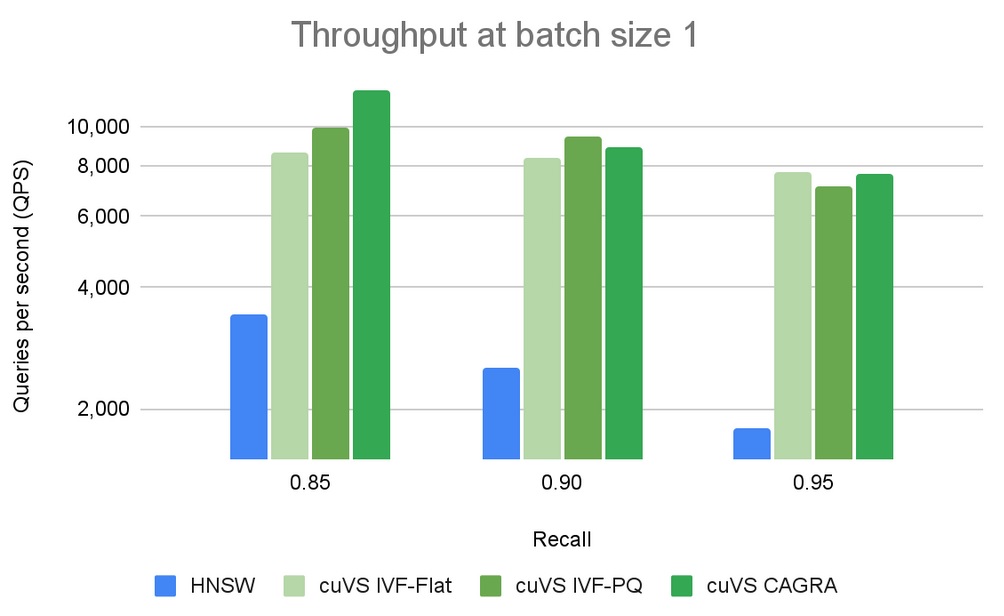
In Figure 2 we run a performance comparison on single queries, which is one of the main use-case for vector search and is also referred to as online search. We can notice that cuVS-based indexes provide a higher throughput, measured in Queries-Per-Second (QPS), than other libraries that are using CPU or GPU.

The benefits of using GPU for vector search applications are most prevalent at higher batch sizes. The performance gap between CPU and GPU is significant and can scale up easily. Figure 3 shows that for a batch size of 10, only cuVS-based indexes are relevant when comparing the number of queries per second. For a batch size of 10k (Figure 4), CAGRA outperforms all other indexes by far.

Summary
Each different vector search index type has benefits and drawbacks which ultimately depend on your needs. This post outlined some of those benefits and drawbacks, providing a brief explanation of how each different algorithm works, along with a few of the most important parameters that can be tuned to trade off storage costs, build times, search quality, and search performance. In all cases, GPUs can improve both index construction and search performance.
NVIDIA cuVS is fully open source and available on GitHub. You can get started with cuVS by reading through the docs, running our reproducible benchmarking suite, or building upon our example vector search example projects. Also be sure to check out our integrations documentation for options to enable cuVS indexes in FAISS, Milvus, and more. Finally, you can follow us on Twitter at @rapidsai.
