
RAPIDS is a suite of accelerated libraries for data science and machine learning on GPUs:
In many data analytics and machine learning algorithms, computational bottlenecks tend to come from a small subset of steps that dominate the end-to-end performance. Reusable solutions for these steps often require low-level primitives that are non-trivial and time-consuming to write well.
NVIDIA made RAPIDS RAFT to address these bottlenecks and maximize reuse when building algorithms for multidimensional data, such as what is often encountered in machine learning and data analytics.
The highly optimized RAFT computational patterns constitute a rich catalog of modular drop-in accelerators, providing you with powerful elements to compose new algorithms or speed up existing libraries.
This is just the beginning: RAFT components will continue to be optimized as new GPU architectures are released, ensuring that you are always getting the best performance out of your hardware.
RAFT enables you to spend your time designing and developing your applications, rather than having to worry about whether you are getting the most out of your GPU hardware.
In this post, I discuss where RAFT belongs in a developer’s toolbox, the circumstances in which to use it, and more importantly, the power to wield RAFT when it is needed.
Removing common bottlenecks
NVIDIA built RAFT to present the essential elements as building blocks for developers.
Nearest Neighbors is a good example. It’s common, useful, and computationally intensive. Neighborhood methods cover a large portion of algorithms for machine learning, such as clustering and reducing dimensionality. The core tools of applied math such as linear algebra, sparse matrix operations, sampling, optimization, and statistical moments are supported.
In fact, RAFT composes nearly all the algorithms in RAPIDS cuML, including but not limited to the popular HDBSCAN, TSNE, UMAP, and all other algorithms for clustering and visualization.
| Category | Examples |
| Data Formats | Sparse and dense, conversions, data generation |
| Dense Operations | Linear algebra, matrix and vector operations, slicing, norms, factorization, least squares, svd, and eigenvalue problems |
| Sparse Operations | Linear algebra, eigenvalue problems, slicing, symmetrization, components, and labeling |
| Spatial | Pairwise distances, nearest neighbors, neighborhood graph construction, vector search |
| Basic Clustering | Spectral clustering, hierarchical clustering, k-means |
| Solvers | Combinatorial optimization, iterative solvers |
| Statistics | Sampling, moments and summary statistics, metrics |
| Tools and Utilities | Common utilities for developing CUDA applications, multi-node multi-gpu infrastructure |
You are now limited only by your creativity if you want to build new work on top of the absolute fastest available. In addition to all the basic methods, the best in class in vector search is unlocking exciting advances in searching large language models (LLM) and recommender systems.
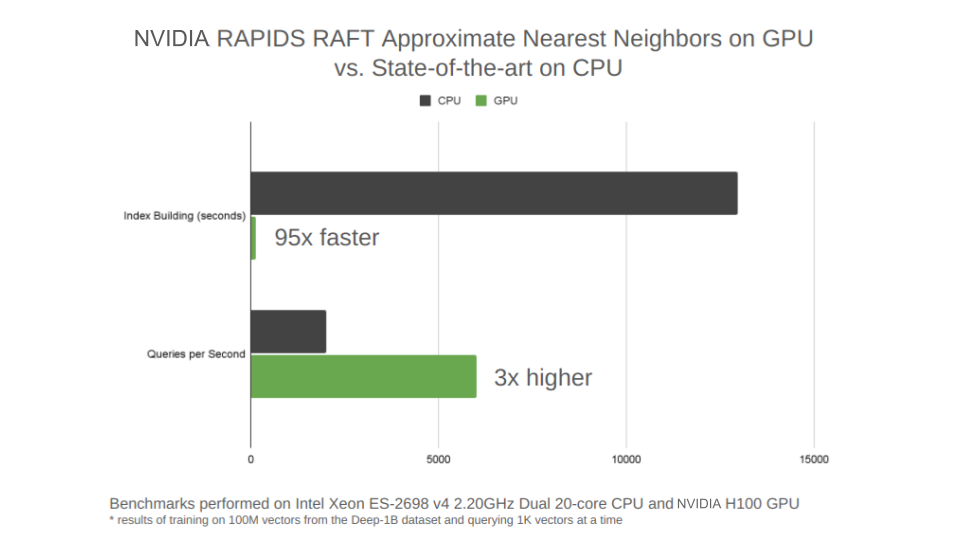
Figure 1 highlights one of the new RAFT state-of-the-art approximate nearest neighbors algorithms for vector search. IVF-PQ is a variant of product quantization (PQ) in a class of algorithms known as inverted file indexes (IVFs). IVFs partition the training data into a set of clusters and reduce the queries to only a subset of the nearest clusters. This is the IVF version of the PQ algorithm, known as IVF-PQ.
The RAFT IVF-PQ implementation has been tuned for the small batch-size query that production vector similarity search systems require. The current state-of-the-art in this class of algorithms tuned for small batch size is called the hierarchical navigable small world graphs (HNSW) algorithm. It’s especially known for being fast on the CPU. The new RAFT IVF-PQ algorithm is 95x faster to train than HNSW and 3x faster at performing small batch-size queries.
Building blocks for a consistent experience
RAFT is a header-only C++ template library at its core, which requires a minimal set of dependencies. It relies mostly on libraries already shipped with the CUDA toolkit. This gives you the flexibility to specialize the templates for your desired data types according to your needs (Figure 2).

Figure 2 shows that the stack begins with a header-only template library. Built on top of the header-only library is a shared library containing precompiled template specializations and a host-accessible runtime API. PyLibRAFT makes the powerful RAFT building blocks available to Python users.
An optional shared library can be used to reduce compile times by precompiling template specializations for common types. Also provided in the shared library is a runtime API that can be linked into your build. It enables RAFT APIs to be called from regular C++ source files in a similar manner to the cuBLAS, cuSOLVER, and cuSPARSE APIs being called from C source files.
Making direct use of the runtime APIs in the shared library is a Python API called pylibraft, which contains lightweight wrappers around the C++ API.
Managing device resources
RAFT uses a raft::resources object to manage different resources like CUDA streams, stream pools, and handles to various CUDA libraries, such as cuBLAS and cuSOLVER. A raft::device_resources instance is the easiest way to configure and manage GPU-specific resources for invoking RAFT APIs.
#include <raft/core/device_resources.hpp>
raft::device_resources resource_handle;
Here’s the same example in Python:
from pylibraft.common.handle import DeviceResources
resource_handle = DeviceResources()
Building complicated end-to-end algorithms with CUDA has traditionally required low-level expertise and advanced knowledge about each GPU architecture’s capabilities to consistently keep the hardware busy.
Libraries like Cub, Thrust, and CUTLASS make it much easier to write CUDA applications. They abstract lower-level APIs into higher-level primitives that are reusable for developing an assortment of algorithms.
RAFT provides a similar layer of abstraction but does so with a specific focus on slightly higher-level primitives for ML and information retrieval, such as vector search. If you are already familiar with the CUDA library of drop-in accelerators for deep neural networks, cuDNN, you can say that RAFT has a similar relationship to a library like RAPIDS cuML as cuDNN has to a library like TensorFlow.
Handling multi-dimensional data
While there are standards beginning to emerge for interacting with the GPU, the RAFT C++ APIs are based on mdspan (multi-dimensional non-owning view) in the C++ 23 STL standard.
mdspan is a non-owning view structure that is highly expressive, flexible, and self-documenting. It has a flexible API for representing multi-dimensional data, similar in spirit to NumPy’s ndarray but in C++. mdspan provides a clean and consistent API experience, as it wraps around any existing pointer, whether in main (host) memory or device memory.
Here’s an example of creating a one-dimensional (vector) mdspan in host memory:
#include <vector>
#include <raft/core/host_mdspan.hpp>
std::vector<float> my_floats(10);
… populate vector …
auto my_mdspan = raft::make_host_vector<float>(my_floats.data(), 10);
Here’s an example of creating an mdspan vector in device (GPU) memory:
#include <raft/core/device_mdspan.hpp>
float *my_floats;
… allocate and populate device memory …
auto my_mdspan = raft::make_device_vector<float>(my_floats, 10);
To streamline the allocation of memory with the multi-dimensional representation, the mdarray standard provides an RAII-compliant memory-owning counterpart to mdspan which RAFT has also adopted. The examples can be made easier by using mdarray to allocate and contain the memory as well.
Here’s an example of using mdarray for device (GPU) memory:
#include <raft/core/device_mdarray.hpp>
#include <raft/core/device_resources.hpp>
raft::device_resources handle;
int n_rows = 10;
int n_cols = 10;
auto scalar = raft::make_device_scalar<float>(handle, 1.0);
auto vector = raft::make_device_vector<float>(handle, n_cols);
auto matrix = raft::make_device_matrix<float>(handle, n_rows, n_cols);
Here’s the same example but for host memory:
#include <raft/core/host_mdarray.hpp>
int n_rows = 10;
int n_cols = 10;
auto scalar = raft::make_host_scalar<float>(1.0);
auto vector = raft::make_host_vector<float>(n_cols);
auto matrix = raft::make_host_matrix<float>(n_rows, n_cols);
After the memory is allocated and contained within an mdarray instance, create an mdspan view to invoke RAFT APIs using the .view method.
// Scalar mdspan on device
auto scalar_view = scalar.view();
// Vector mdspan on device
auto vector_view = vector.view();
// Matrix mdspan on device
auto matrix_view = matrix.view();
Using the C++ and Python APIs
As an example, use the new RAFT approximate nearest neighbor APIs for vector search by building and querying an index in both C++ and Python. The following code example builds an index using the RAFT IVF-PQ algorithm.
#include <raft/neighbors/ivf_pq.cuh>
raft::device_resources handle;
raft::neighbors::ivf_pq::index_params idx_params;
auto index = raft::neighbors::ivf_pq::build(handle, idx_params, dataset);
You can use the following code example to query the newly built index.
#include <raft/core/device_mdarray.hpp>
raft::neighbors::ivf_pq::search_params search_params;
uint32_t n_query_rows = 1000;
uint32_t k = 5;
…
auto out_inds = raft::make_device_matrix<int64_t>(handle, n_query_rows, k);
auto out_dists = raft::make_device_matrix<float>(handle, n_query_rows, k);
raft::neighbors::ivf_pq::search(handle, search_params, index, queries,
out_inds.view(), out_dists.view());
Here’s an example of building an index in Python:
import cupy as cp
from pylibraft.neighbors import ivf_pq
n_samples = 50000
n_query_rows = 1000
index_params = ivf_pq.IndexParams(
n_lists=1024,
metric="sqeuclidean",
pq_dim=10)
index = ivf_pq.build(index_params, dataset)
Here’s an example of searching the index in Python:
search_params = ivf_pq.SearchParams(n_probes=20)
k = 10
…
distances, neighbors = ivf_pq.search(ivf_pq.SearchParams(), index,
queries, k)
PyLibRAFT can interoperate with any library that supports the __cuda_array_interface__ (CAI), such as PyTorch, CuPy, Numba, TensorFlow, and JAX. By default, PyLibRAFT functions can accept any CAI-compliant array, even for writing the outputs in place if desired. You can customize this behavior to the library of your choice for more seamless integration by configuring a function that performs the output conversions.
The following code examples configure PyLibRAFT to return CuPy ndarray or PyTorch tensors.
import pylibraft.config
pylibraft.config.set_output_as("cupy") # All compute APIs will return cupy arrays
pylibraft.config.set_output_as("torch") # All compute APIs will return torch tensors
You can also configure a custom function. As an example, the following code example converts all outputs from PyLibRAFT functions to NumPy arrays in main (host) memory.
pylibraft.config.set_output_as(lambda device_ndarray: return device_ndarray.copy_to_host())
Getting RAFT
The following steps provide information about different ways RAFT can be installed. Conda and PIP are the easiest routes, especially when interacting with PyLibRAFT. As RAFT is a C++ library at its core, I also show briefly how easily it can be integrated into Cmake.
Conda
An easy way to install RAFT, both for C++ and Python usage, is by means of conda. Install the C++ headers into your conda environment.
conda install -c rapidsai -c conda-forge -c nvidia libraft-headers
Install the precompiled binary into your environment as well (this will also install libraft-headers).
conda install -c rapidsai -c conda-forge -c nvidia libraft
The Python library, of course, is also available in conda (this will also install libraft-headers and libraft):
conda install -c rapidsai -c conda-forge -c nvidia pylibraft
Pip
RAPIDS also provides pip packages, which can be installed easily in pure Python environments.
pip install pylibraft-cu11 --extra-index-url=https://pypi.nvidia.com
pip install raft-dask-cu11 --extra-index-url=https://pypi.nvidia.com
CMake
RAFT can also be integrated easily into your cmake projects using the CMake Package Manager (CPM) and rapids-cmake, which also downloads the desired version and configures the raft::raft cmake target. For more information about building RAFT from the source, see build and install instructions.
If RAFT has already been installed, such as with the conda command earlier, use cmake’s find_package to make the raft::raft target available to your project.
find_package(raft)
The raft::raft target carries along the base set of dependencies needed for many of the main RAFT features, such as RAPIDS Memory Manager (RMM) and the CUDA Toolkit libraries. However, you might need additional dependencies if you are relying on any distributed APIs that use raft::comms.
RAFT makes use of optional cmake components, which enables new cmake targets for passing these dependencies through to your project. These components also allow you to specify that you would like to use the precompiled libraft binary.
find_package (raft COMPONENTS compiled distributed)
This cmake function enables targets raft::compiled and raft::distributed in addition to raft::raft. Add them to the necessary build targets for passing through include paths and link library information for dependencies. For example, raft::compiled will make sure your cmake targets link against the libraft binary and raft::distributed will make sure your code links against NVIDIA Collective Communications Library (NCCL) and Unified Communication X (UCX).
Key takeaways
RAFT is a library of highly reusable computational patterns for machine learning and data analytics. Centralizing important computations enables you to reap the benefits of improved performance automatically whenever optimizations are made, such as when new GPU architectures and capabilities are released.
RAFT also contains highly reusable infrastructure for building production-quality accelerated libraries with clean and flexible interfaces, following the lead of important standards like the C++ STL to guarantee longevity.
RAFT eases integration by covering the whole stack, from C++ to Python, further enabling interoperability with other popular GPU-accelerated libraries like PyTorch, CuPy, and Numba, in addition to the libraries in the RAPIDS ecosystem.
For more information, see the RAFT User’s Guide and /rapidsai/raft GitHub repo and attend the following NVIDIA GTC 2023 sessions: