
This post was originally published on the RAPIDS AI blog.
Why signal processing?
Signal processing is all around us. Broadly defined as the manipulation of signals — or mechanisms of transmitting information from one place to another — the field of signal processing exploits embedded information to achieve a certain goal. In the case of noise cancellation, the goal is to cancel out or suppress (via filtering!) the specific frequencies containing the baby’s cry.
If you’ve ever used a radio, cell phone, garage door opener, GPS device, or heard an auto-tuned hip-hop song, and used a speech to text transcription tools, you’ve interacted with elements of a signal processing workflow.
A walk in time
Signal processing applications have always been driven by real-time requirements. That cell phone app for spoken Spanish to English translation would be pretty worthless if it took thirty seconds to process 5 seconds of speech. Similarly, in one major subset of the signal processing domain — Software Defined Radio (SDR) — real-time response is critical for spectrum estimation, geolocation, and other forms of rapid response.
Historically, these applications have leveraged accelerator hardware like specialized ASICS or FPGAs. While these devices can provide ultra-low latency response, they can be difficult to program, expensive, and tend to be inflexible if the signal processing goal changes. As a result, when NVIDIA released CUDA over a decade ago, many signal processing engineers jumped to GPUs for their dense linear algebra needs.
NVIDIA offers a plethora of C/CUDA accelerated libraries targeting common signal processing operations. cuFFT GPU accelerates the Fast Fourier Transform while cuBLAS, cuSOLVER, and cuSPARSE speed up matrix solvers and decompositions essential to a myriad of relevant algorithms.
CUDA can be challenging. If a developer is comfortable with C or C++, they can learn the basics of the API in a few days, but manual memory management and decomposition of desired algorithms to exploit parallelism can be quite difficult. To be productive, software engineers and developers need an additional layer of abstraction, sacrificing a modicum of processing speed for a boost in development speed.
The NVIDIA led RAPIDS initiative scratches this itch. With cuDF, cuML, cuGraph, and cuSpatial — the GPU open source data science community is bringing GPU speeds to common Python APIs. No longer is CUDA the only way to see performance gains on NVIDIA GPUs.
cuSignal was built with this design philosophy in mind.
What is cuSignal?
cuSignal GPU-accelerates the popular SciPy Signal library with CuPy (GPU-accelerated NumPy) and custom Numba CUDA kernels.
SciPy Signal provides a feature rich API that’s an easy on-ramp for MATLAB programmers and Pythonistas alike. By containing functionality for many base signal processing transformations and techniques like convolutions, correlations, spectrum estimation techniques, and filtering, SciPy Signal allows for both complex and fast applications to be built from the Python layer. While certain SciPy Signal functions, like upfirdn (upsample, filter, downsample) and lfilter (linear filter) consist of Cython wrapped C code, much of the codebase leverage base NumPy API calls.
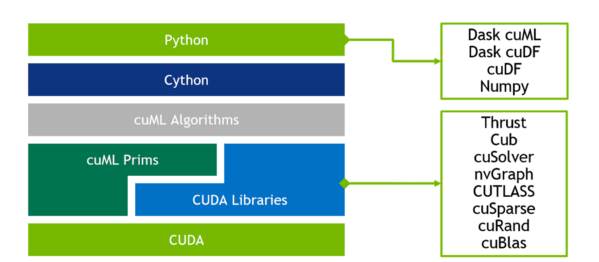
cuSignal differs from the traditional RAPIDS software development philosophy. Figure 1 shows a typical software stack, in this case for cuML. In this library, GPU development takes place at the CUDA level where special primitives are constructed, tied into existing CUDA libraries, and then given Python bindings via Cython. Development for cuSignal, as seen in Figure 2, takes place entirely in the GPU-accelerated Python layer.
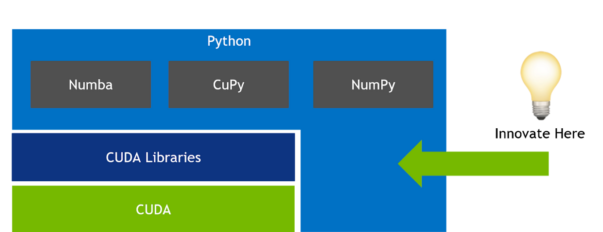
cuSignal heavily relies on CuPy, and a large portion of the development process simply consists of changing SciPy Signal NumPy calls to CuPy. Since CuPy already includes support for the cuBLAS, cuDNN, cuFFT, cuSPARSE, cuSOLVER, and cuRAND libraries, there wasn’t a driving performance-based need to create hand-tuned signal processing primitives at the raw CUDA level in the library.
In some cases, cuSignal leverages Numba CUDA kernels when CuPy replacement of NumPy wasn’t an option. In the case of upfirdn, for example, a custom Python-based CUDA JIT kernel was created to perform this operation. More performance could have been obtained with a raw CUDA kernel and a Cython generated Python binding, but again — cuSignal stresses both fast performance and go-to-market. Numba’s cuda_array_interface standard for specifying how data is structured on GPU is critical to pass data without incurring an extra copy between CuPy, Numba, RAPIDS, and PyTorch for deep learning.
The overarching design philosophy of cuSignal was:
“let’s see how far we can get by gluing together work of the community and providing targeted performance improvements when needed.”
With this in mind, cuSignal was able to put features first — accelerating much of the SciPy Signal API in a quick time frame. This encourages others to build GPU-accelerated libraries in a similar manner going forward.
A complete list of GPU accelerated features can be found in the cuSignal CHANGELOG but generally includes spectral analysis (periodogram, spectrogram, etc), peak finding, windowing, waveform generation, resampling, and convolution.
Performance
As is true with all GPU applications, cuSignal sees the most performance increase between GPU and CPU when using large signal sizes. Tables 1 and 2 show CPU (Intel 2x E5) performance versus both an NVIDIA P100 and V100. In both cases, these functions were run on a real valued, FP64 signal containing 1e8 samples. Additional performance can be achieved with a reduction of precision.
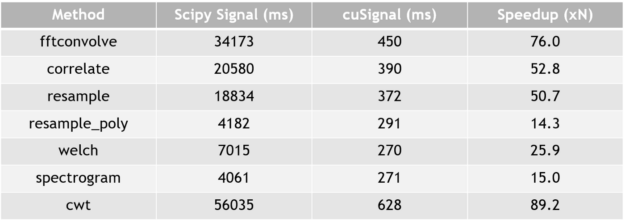
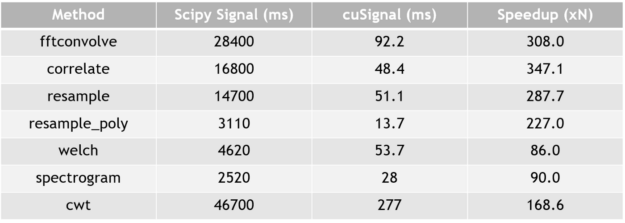
Timeit turns off Python garbage collection and contains cached memory. This can be considered to be the best case scenario.
The notebooks section of the cuSignal repository has extensive examples of both performance benchmarking and API usage.
Online signal processing — memory handling and FFT benchmarking
While offline signal processing on highly sampled signals may be valuable as a pre-processing step in a signal processing pipeline, many applications, particularly within the SDR domain, depend on frequent, relatively small copies from the radio buffer to the CPU or accelerator before further processing is invoked. In the case of some software defined radios, the buffer size tends to max-out around 32,768 complex samples (4MB).
GPUs are a latency hiding device, so the naive approach of transferring 4MB files over PCIe from the CPU to the GPU for further processing would cripple workflow performance. As a result, cuSignal makes use of Numba’s cuda.mapped_array function to establish a zero-copy memory space between the CPU and GPU. The mapped array call removes a user specified amount of memory from the Page Table (pins the memory) and then virtually addresses it so both CPU and GPU calls can be made with the same memory pointer.
cuSignal hides the mapped_array call with _arraytools.get_shared_mem and _arraytools.get_shared_array where get_shared_mem acts like np.empty and get_shared_array physically loads data into a CPU/GPU shared array.

Figure 3 demonstrates the performance gains one can see by creating an arbitrary shared GPU/CPU memory space — with data loading and FFT execution occuring in 0.454ms, versus CPU/Numpy with 0.734ms.
As a special note, the first CuPy call to FFT includes FFT plan creation overhead and memory allocation. This cost is only paid once and can be ‘pre-paid’ before starting an online signal processing workflow. Further, CuPy is expanding support for manual FFT plan creation. You can read more about CuPy.
cuSignal to PyTorch
One of the most exciting features of cuSignal and the GPU-accelerated Python ecosystem is the ability to zero-copy move data from one library/framework to another with Numba’s __cuda_array_interface__.The End-to-End notebook in the cuSignal repository demonstrates a collection to inferencing workflow with signals data. In this example, 2000 signals of length 215 are generated with 1 to 5 carriers spaced at one of 10 different center frequencies. Then use cuSignal to polyphase resample the signal ensemble to up sample by 2 and then run a periodogram with a flattop filter over each signal. Finally, this data structure is passed to PyTorch via DLPack to train and predict the number of carriers in an arbitrary signal.
As of PyTorch 1.2, the __cuda_array_interface__ has been merged into the library, and data movement will no longer need to move via DLPack. More information can be found with this CuPy GitHub issue.
Try cuSignal today
cuSignal is currently available via a source build only at the cuSignal GitHub repository. Conda packaging is in the works, and this blog will be updated when available.
cuSignal is still in its infancy and would benefit from community driven support and development. Whether you’re interested in audio signal processing, software defined radios, or noise suppression, we welcome your PRs and Issues. Please help profile performance, optimize code, and add new features! Further, if you’re interested in cuSignal, please star the repository on GitHub!
Acknowledgements
cuSignal is thankful for the SciPy Signal core development team, particularly Travis Oliphant. Further, cuSignal thanks all beta testers of cuSignal, including Expedition Technology, Deepwave Digital, and Fusion Data Science, among many others. Finally, thanks to NVIDIA engineer Matthew Nicely for his work on zero-copy memory and Numba CUDA optimization.
