神经科学领域的一个主要目标是了解大脑如何控制运动。通过改进姿势估计,神经生物学家可以更精确地量化自然运动,进而更好地了解驱动自然运动的神经活动。这增强了科学家表征动物智力、社交和健康的能力。
哥伦比亚大学的研究人员最近开发了一个以视频为中心的深度学习包,可以从视频中更有力地跟踪动物的运动,这有助于:
- 在面对遮挡和数据集偏移时获得可靠的姿态预测。
- 同时在图像和视频上进行训练,同时显著缩短训练时间。
- 简化训练模型、形成预测和可视化结果所需的软件工程
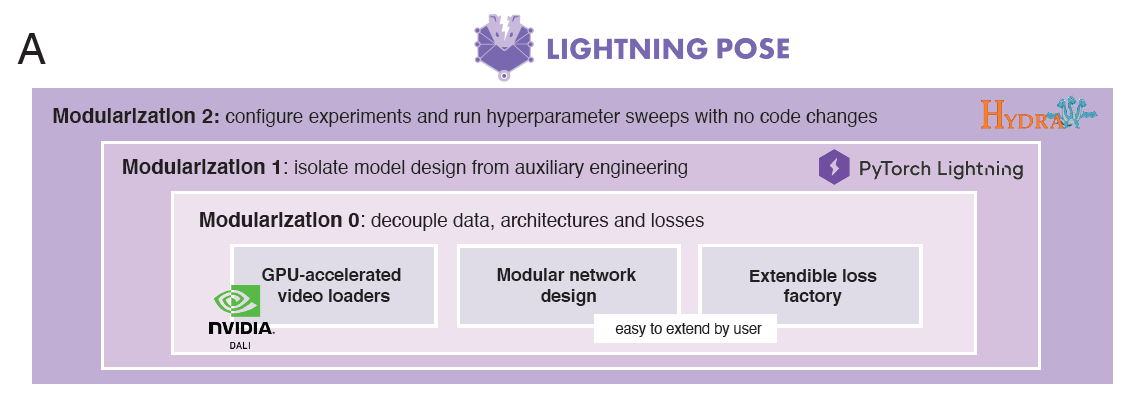
Lightning Pose 是一个工具,可以在 PyTorch Lightning 中用于训练深度学习模型,以标记图像和未标记视频,并使用 NVIDIA 的 DALI 在 GPU 上对其进行解码和处理。
在这篇博客文章中,您将看到当代计算机视觉架构如何从开源的 GPU 加速视频处理中受益。
用于视频中自动姿势跟踪的深度学习算法最近在神经科学中引起了广泛关注。标准方法包括在一组注释图像上以完全监督的方法训练卷积网络。
大多数卷积架构都是为处理单个图像而构建的,并且不使用隐藏在视频中的有用的时间信息。通过单独跟踪每个关键点,这些网络可能会生成无意义的姿势或多个相机之间不一致的姿势。 尽管它被广泛采用并取得了成功,但主流的方法往往过于适合训练,难以推广到看不见的动物或实验室。
一种有效的动物姿态跟踪方法
如图1所示,这个Lightning Pose 包是一组用于动物姿态跟踪的深度学习模型,在 PyTorch Lightning 中实现。它采用以视频为中心的半监督方法来训练姿态估计模型,除了在一组标记的帧上进行训练外,它还在许多未标记的视频片段上进行训练,并在其姿势预测序列不连贯(即违反基本时空约束)时惩罚自己。使用 DALI 直接在 GPU 上对未标记的视频进行解码和动态处理。
在训练过程中, DALI 会以各种方式随机修改或增强视频。这使网络暴露在更广泛的训练示例中,并使其更好地应对部署时可能遇到的数据中的意外系统变化。
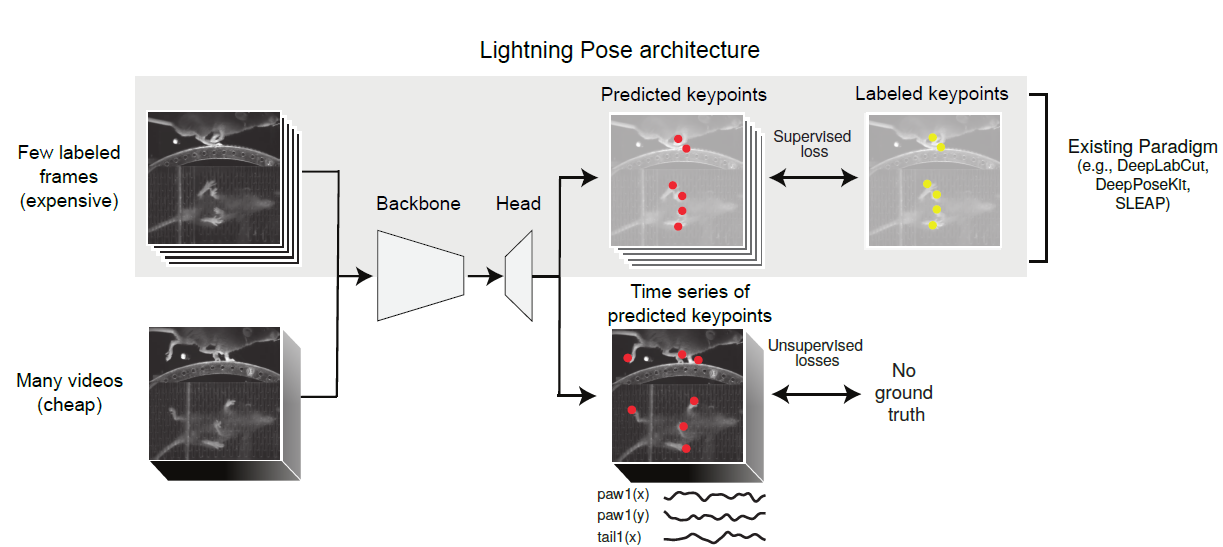
它的半监督架构,如图 2 所示,从标记和未标记的帧中学习。
与标准监督网络相比,闪电姿势可以在不同物种(老鼠、鱼等)和任务(全身运动、眼睛跟踪等)之间实现更准确、更精确的跟踪。传统的完全监督方法需要大量的图像标记,并且很难推广到新的视频中。它经常产生干扰下游分析的噪声输出。
它的新姿态估计网络更好地推广到看不见的视频,并提供更平滑、更可靠的姿态轨迹,同时增强了健壮性和可用性。通过半监督学习、贝叶斯集成和云原生开源工具,与 DeepLabCut(只有 75 个标记帧)相比,闪电姿态估计提高了 40%,降低了帧间的像素误差和平均关键点像素误差(DeepLabCut 14.60 ± 4)。
在国际大脑实验室的小鼠瞳孔跟踪数据集中可以看到最明显的收获,即使有 3000 多个标记帧,预测也更准确,并导致更可靠的科学分析。
图 3 显示了在神经科学实验中跟踪老鼠瞳孔的上、下、左和右角。在左边, DeepLabCut 模型在图像的不可信部分(红框)提供了大量预测。
中心显示闪电姿态预测,右侧将闪电姿态与作者的集合卡尔曼平滑方法相结合。两种闪电姿势的方法都很好地跟踪了这四个点,并在合理的区域预测它们。
改进的瞳孔跟踪反过来暴露出与神经活动更强的相关性。作者在 66 个神经科学实验中对神经活动和追踪的瞳孔直径进行了回归,发现模型输出可以更可靠地从大脑活动中解码。
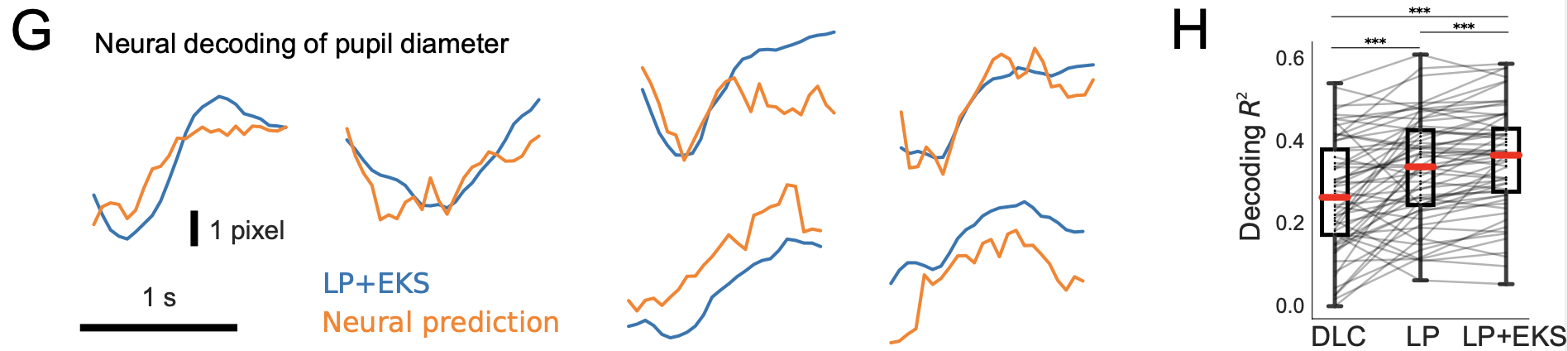
图 4 显示从大脑记录中解码瞳孔直径。图 4 的左侧显示了从闪电姿势模型( LP + EKS ;蓝色)得出的瞳孔直径时间序列,以及将线性回归应用于神经数据的预测(橙色)。
图 4 的右侧显示 R2拟合优度值量化了从神经活动中解码瞳孔直径的效果。如图所示,闪电姿态和合奏版本产生了明显更好的结果 DLC R2 = 0 . 27 ± 0 . 02 ; LP 0 . 33 ± 0 . 02 ; LP + EKS 为 0 . 35 ± 0 . 02 。
下面的视频展示了老鼠在跑步机上跑步的预测的稳健性。
利用 DALI 改进卷积体系结构的以图像为中心的方法
将卷积网络应用于视频是一个独特的挑战:这些网络通常只在单个图像上运行。尽管新一代 GPU 的深度学习加速器的计算能力不断增长,Tensor Cores 和 CUDA Graphs,这种以图像为中心的方法基本上没有改变。目前的体系结构要求在预处理期间将视频分割成单独的帧,通常将其保存在磁盘上以供以后加载。然后,这些帧在 CPU 上被扩充和变换,然后被传送到在 GPU 上等待的网络。
Lightning Pose 利用 DALI 进行 GPU-加速视频解码和处理。这与大多数计算机视觉深度学习架构形成了鲜明对比,如 ResNets 和 Transformers,它们通常只对单个图像进行操作。当依次应用于视频时,这些架构(以及流行的神经科学工具DeepLabCut和SLEAP基于它们的)往往会产生违反物理定律的不连续预测。例如,在两个连续的视频帧中,一个对象可能会从房间的一个角落跳到另一个角落。
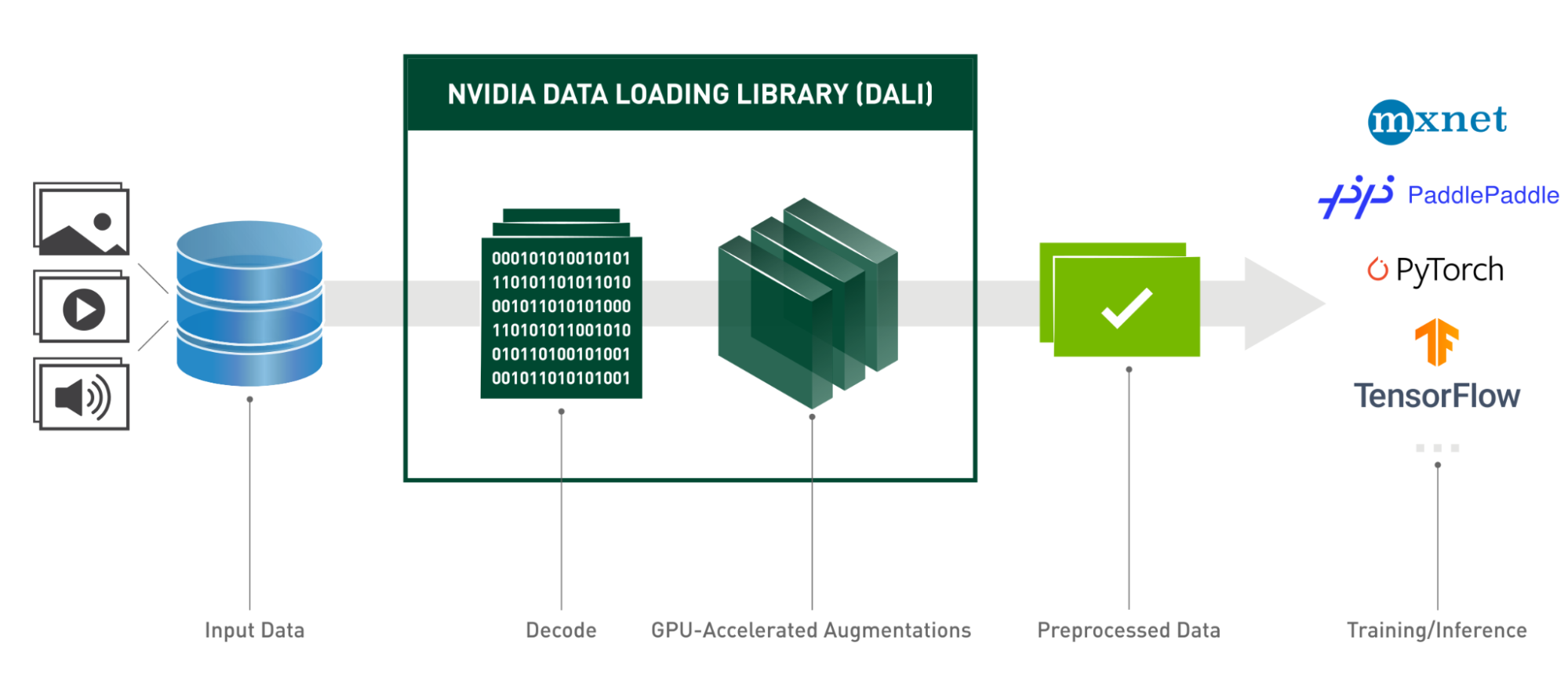
DALI 为闪电姿势提供了一个有效的解决方案,通过:
- 阅读视频。
- 处理解码过程(感谢 NVIDIA 视频编解码 SDK)。
- 应用各种增强(旋转、调整大小、亮度和对比度调整,甚至添加镜头噪声)。
使用 DALI , Lightning Pose 通过充分使用 GPU 提高了视频数据的训练吞吐量,并保持了整个解决方案的预期性能。
DALI 还可以与并行工作的附加数据加载程序结合使用。International Brain Laboratory,由 16 个不同的神经科学实验室组成的联盟,正在整合 DALI 加载程序,以预测 30000 个神经科学实验中的姿势。
开源合作的好处
这项研究是开源社区合作创造价值的一个很好的例子。 DALI 和 Lightning Pose 都是开源项目,对社区在 GitHub 上的反馈和询问反应强烈。这些项目之间的合作始于 2021 年年中,当时社区成员 Dan Biderman 开始评估 DALI 技术。 Dan 的积极参与和 DALI 团队的迅速反应促成了富有成效的对话,从而将其融入了 Lightning Pose 。
下载并尝试 DALI 和 Lightning Pose;您可以直接通过它们的 GitHub 页面与他们联系。
阅读研究,通过半监督学习、贝叶斯集成和云原生开源工具改善动物估计。