
异构计算架构——那些结合了各种协同工作的处理器类型的架构——在人工智能、机器学习( ML )、量子物理和通用数据科学中的计算工作负载的持续可扩展性方面被证明是非常有价值的。
这一开发的关键在于能够抽象出异构体系结构,并促进一个框架,使设计和实现这类应用程序更加高效。实现这一点的最著名的编程模型是 CUDA Toolkit,它能够按照单指令多数据模型将工作并行地分发到数千个 GPU 核心。
最近,一种新形式的节点级协处理器技术引起了计算科学界的注意:量子计算机,它依靠量子物理的非直观定律,利用叠加、纠缠和干涉等原理来处理信息。这种独特的加速器技术可能在非常具体的应用中被证明是有用的,并准备与 CPU 和 GPU 协同工作,开创了一个以前被认为不可行的计算进步时代。
问题变成了:如果你用量子协处理器增强现有的经典异构计算架构,你将如何以适合计算可扩展性的方式对其进行编程?
NVIDIA 使用 CUDA Quantum,一个开源编程模型,用量子内核扩展 C++ 和 Python,用于在量子硬件上编译和执行。
这篇文章介绍了 CUDA 量子,强调了它的独特功能,并展示了研究人员如何利用它在日常量子算法研发中积累动力。
CUDA 量子:你好,量子世界
首先来看一下 CUDA 量子编程模型,使用 Python 接口创建一个两量子位 GHZ 状态。这将使你习惯它的语法。
import cudaq
# Create the CUDA Quantum Kernel
kernel = cudaq.make_kernel()
# Allocate 2 qubits
qubits = kernel.qalloc(2)
# Prepare the bell state
kernel.h(qubits[0])
kernel.cx(qubits[0], qubits[1])
# Sample the final state generated by the kernel
result = cudaq.sample(kernel, shots_count = 1000)
print(result)
{11:487, 00:513}语言规范借用了 CUDA 已经证明是成功的概念;具体地说,主机和设备代码在功能边界级别上的分离。下面的代码片段在 C ++中的 GHZ 状态准备示例中演示了此功能。
#include <cudaq.h>
int main() {
// Define the CUDA Quantum kernel as a C++ lambda
auto ghz =[](int numQubits) __qpu__ {
// Allocate a vector of qubits
cudaq::qvector q(numQubits);
// Prepare the GHZ state, leverage standard
// control flow, specify the x operation
// is controlled.
h(q[0]);
for (int i = 0; i < numQubits - 1; ++i)
x<cudaq::ctrl>(q[i], q[i + 1]);
};
// Sample the final state generated by the kernel
auto results = cudaq::sample(ghz, 15);
results.dump();
return 0;
}
CUDA Quantum 允许将量子代码定义为独立的内核表达式。这些表达式可以是 C++ 中的任何可调用表达式(这里展示了 lambda,它是隐式类型的可调用表达式),但必须使用 __qpu__ 属性启用 nvq++ 编译器 单独编译。内核表达式可以接受经典输入(这里是量子位的数量),并利用标准 C++ 控制流,例如循环和 if 语句。
GPU 的效用
将实验性努力QPUs从研究实验室中扩大规模,并将其托管在云上以供普通访问,这是一个了不起的成就。然而,目前的 QPU 噪声大且规模小,阻碍了算法研究的发展。为了帮助解决这一问题,电路仿真技术正在满足推动研究前沿的迫切需求。
桌面 CPU 可以模拟小规模的量子位统计;然而,状态向量的存储器需求随着量子位的数量呈指数级增长。一台典型的台式计算机拥有 8GB 的 RAM ,使其能够缓慢地模拟大约 15 个量子位。最新消息NVIDIA DGX H100使您能够以前所未有的速度超越 35 量子位大关。
图 1 显示了典型变分算法工作流的 GPU 和 GPU 后端上的 CUDA Quantum 的比较。对 GPU 的需求在这里是显而易见的,因为在 14 个量子位处的加速是 425x ,并且随着量子位计数的增加而增加。外推到 30 个量子位, CPU – GPU 的运行时间为 13 年,而不是 2 天。这释放了研究人员超越小规模概念验证结果,实现更接近现实世界应用的算法的能力。
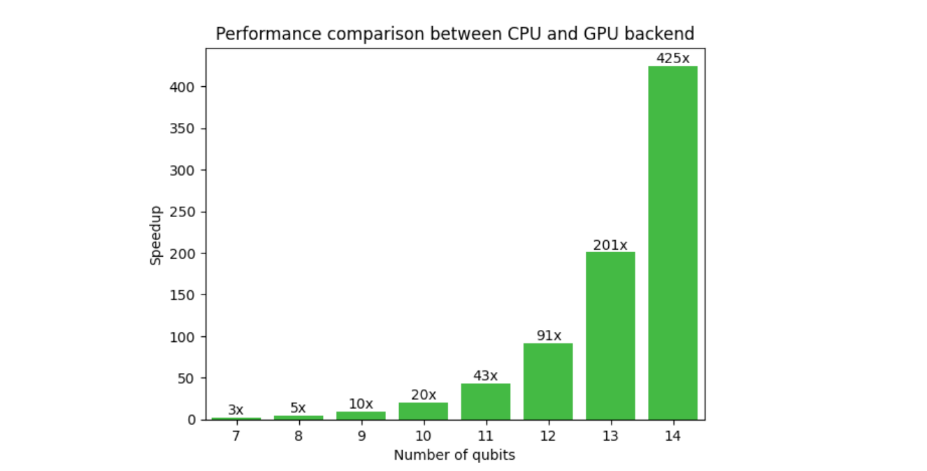
NVIDIA 与 CUDA Quantum 共同开发了 cuQuantum,一个库,通过手工优化的 CUDA 内核,使用状态向量和张量网络方法实现量子计算机的快速模拟。内存分配和处理完全在 GPU 上完成,从而显著提高了性能和规模。CUDA Quantum 与 cuQuantum 的结合,形成了一个强大的混合算法研究平台。
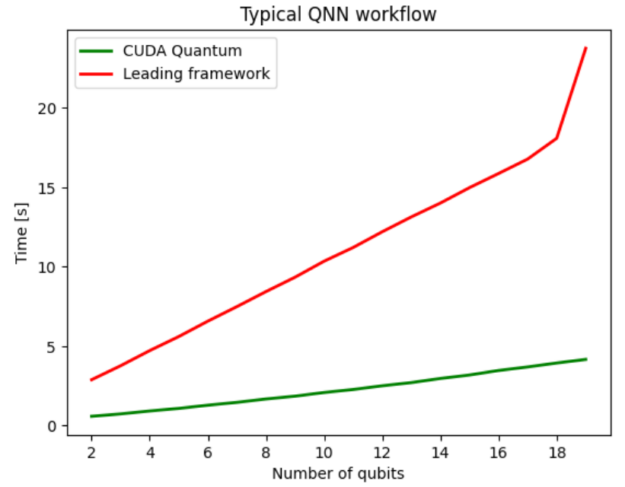
图 2 将 CUDA Quantum 与领先的量子计算 SDK 进行了比较,两者都利用 NVIDIA -cuQuantum 后端将电路模拟优化卸载到 NVIDIA GPU 上。在这种情况下,使用 CUDA Quantum 的好处是孤立的,与领先的框架相比,平均性能提高了 5 倍。
实现未来的多 QPU 工作流
CUDA 量子并不局限于考虑当前基于云的量子执行模型,而是充分预期了紧密耦合的系统级量子加速。此外, CUDA Quantum 使应用程序开发人员能够设想具有多 GPU 后端的多 QPU 架构的工作流。
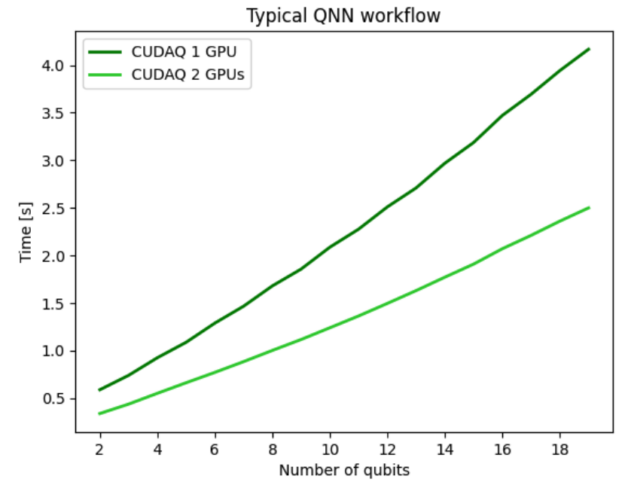
对于前面的量子神经网络( QNN )示例,您可以使用 multi- GPU 功能来运行数据集的前向传递,使我们能够执行未来的多 QPU 工作流。图 3 显示了将 QNN 工作流分布在两个 GPU 上的结果,并展示了强大的扩展性能,表明所有 GPU ‘计算资源都得到了有效利用。使用两个 GPU 使整个工作流程的速度是单个 GPU ‘的两倍,显示出强大的可扩展性。
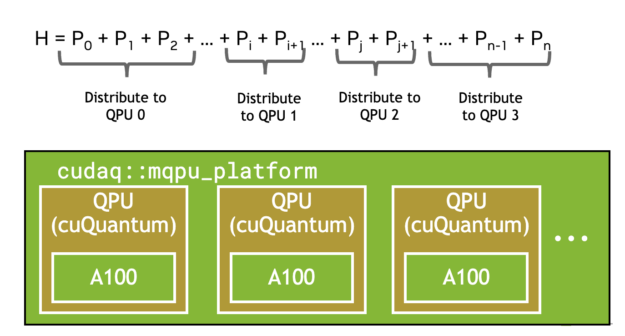
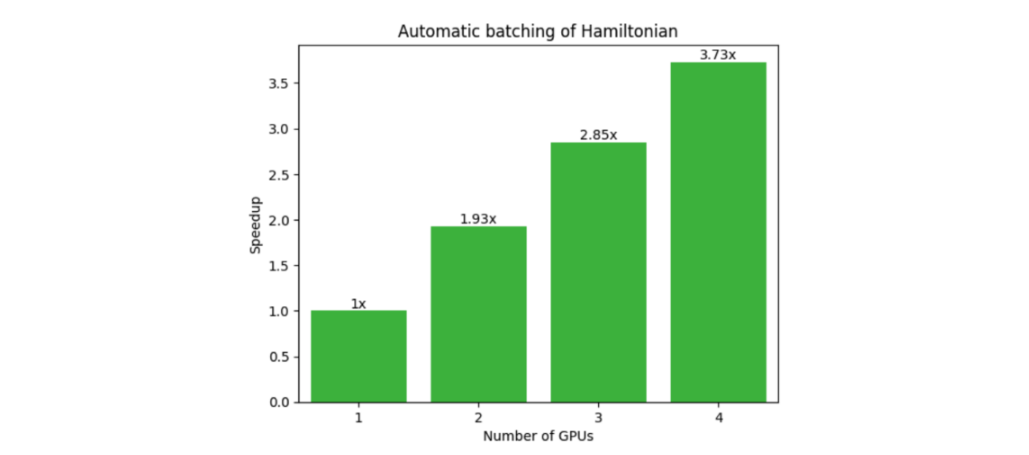
另一个受益于多 QPU 并行化的常见工作流程是变分量子特征解算器( VQE )。这需要由多个单泡利张量乘积项组成的复合哈密顿量的期望值。如下图所示, CUDA Quantum 观察调用会自动批量处理术语(图 4 ),并在可用的情况下卸载到多个 GPU 或 QPU ,显示出强大的可扩展性(图 5 )。
numQubits, numTerms = 30, 1e5
hamiltonian = cudaq.SpinOperator.random(numQubits, numTerms)
cudaq.observe(ansatz, hamiltonian, parameters)
GPU -QPU 工作流
到目前为止,这篇文章已经探索了使用 GPU 将量子电路模拟扩展到 CPU 上可能的范围之外,以及多 QPU 工作流程。以下部分将使用 PyTorch 和 CUDA quantum ,以混合量子神经网络为例,深入探讨真正的异构计算。
如图 6 所示,混合量子神经网络包含量子电路作为整个神经网络架构中的一层。这是一个活跃的研究领域,有望在某些领域发挥优势,改善泛化误差。
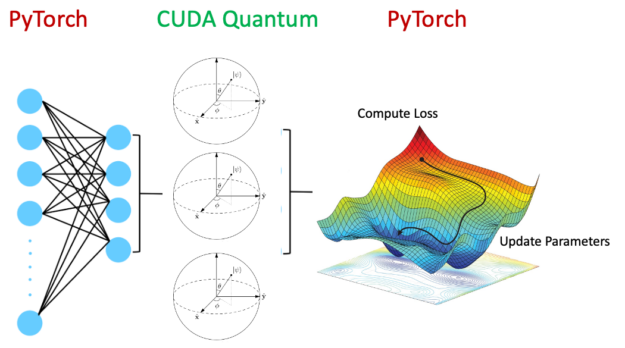
显然,在 GPU 上运行经典神经网络层和在 QPU 上运行量子电路是有利的。通过设置以下内容,可以使用 CUDA Quantum 加速整个工作流程:
quantum_device = cudaq.set_target('ion-trap')
classical_device = torch.cuda.set_device(gpu0)
这样做的效用是深远的。 CUDA Quantum 能够以紧密集成、无缝的方式卸载适用于 QPU 和 GPU 的相关内核。除了混合应用程序之外,涉及纠错、实时最优控制和通过 Clifford 数据回归减少错误的工作流程都将受益于紧密耦合的计算架构。
QPU 硬件提供商
嵌入 CUDA 量子编程范式中的基本信息单元是量子位,它表示能够访问 d 态的量子比特。 Qubit 是 d = 2 的一个特定实例。通过使用量子位, CUDA Quantum 可以有效地针对各种量子计算架构,包括超导电路、离子阱、中性原子、基于金刚石的光子系统等。
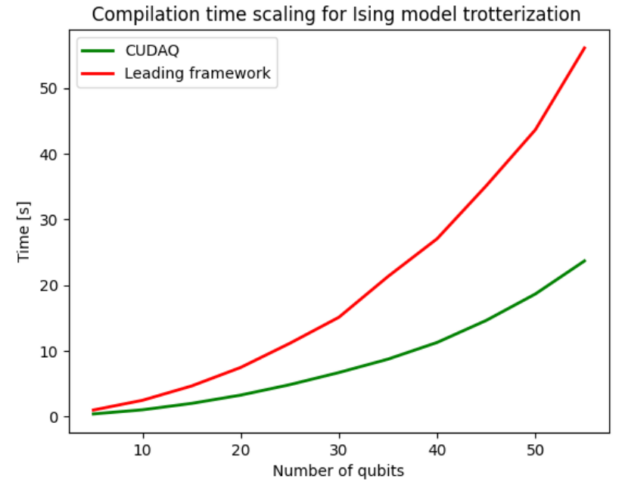
您可以轻松地开发工作流,使用 nvq++ 编译器 在指定的体系结构上自动编译和执行程序。图 7 展示了新型编译器产生的编译加速。编译过程包括电路优化,将其分解为硬件支持的原生门集和量子位路由。CUDA Quantum 使用的 nvq++ 编译器与竞争对手相比,平均快 2.4 倍。
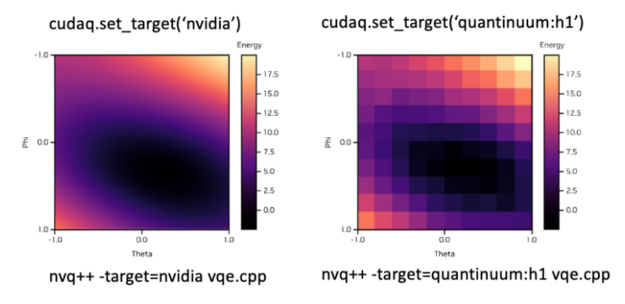
为了适应所需的后端,您可以简单地修改set_target()旗帜图 8 显示了如何在模拟后端和 QuantinuumH1 离子阱系统之间无缝切换的示例。顶部显示在 Python 中设置所需后端的语法,底部显示在 C ++中。
开始使用 CUDA Quantum
本文简单介绍了 CUDA 量子编程模型的一些特性。访问 CUDA Quantum 社区的 GitHub 开始尝试一些 示例代码片段。我们期待着看到 CUDA Quantum 为您带来的研究成果。




