NVIDIA cuQuantum 是一个用于加速量子计算工作流程的优化库和工具集 SDK。借助 NVIDIA Tensor Core GPU,开发者可以利用它将基于状态向量和张量网络方法的量子电路模拟加速数个数量级。
cuQuantum 的目标是在 NVIDIA GPU 和 CPU 上以光速提供量子电路模拟。量子计算框架的用户可以利用 cuQuantum 支持的模拟器为其工作负载实现 GPU 加速。
cuQuantum 23.10 有哪些新功能?
cuQuantum 23.10 对 NVIDIA cuTensorNet 和 NVIDIA cuStateVec 进行了更新。新功能包括对 NVIDIA Grace Hopper 系统的支持。欲了解更多信息,请参阅 cuQuantum 23.10 版本说明。
Tensor 网络高级 API 和梯度
cuTensorNet 提供高级 API,便于量子模拟器开发者以直观的方式进行编程,以充分利用其功能。这项技术使开发者能够在创建模拟器时抽象出特定的张量网络知识。这使得构建基于张量网络的量子模拟器变得更加简单,因为它涵盖了期望、测量结果、样本和其他元素。
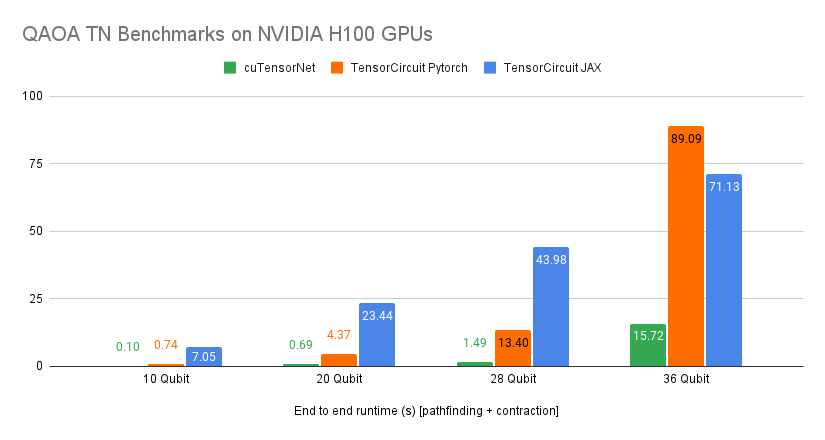
我们推出了为梯度计算提供实验性支持,针对给定的张量网络,旨在通过张量网络加速量子机器学习(QML)。这可以显著加速 QML,并将 cuTensorNet 与基于微分的工作流程相结合。
使用更少的设备扩展状态向量模拟
cuStateVec 为 主机到设备状态向量交换 提供支持,这使得结合使用 CPU 显存和 GPU 来进一步扩展模拟成为可能。现在,40 量子位状态向量的模拟只需要 16 个 NVIDIA Grace Hopper 系统,而不是 128 个 NVIDIA H100 80GB GPU。从这些系统提供的加速效果来看,NVIDIA Grace Hopper 在与其他 CPU 以及仅使用 CPU 的实现相结合时,性能大大优于 NVIDIA Hopper GPU 架构。这为每个工作负载节省了大量的成本和能源。
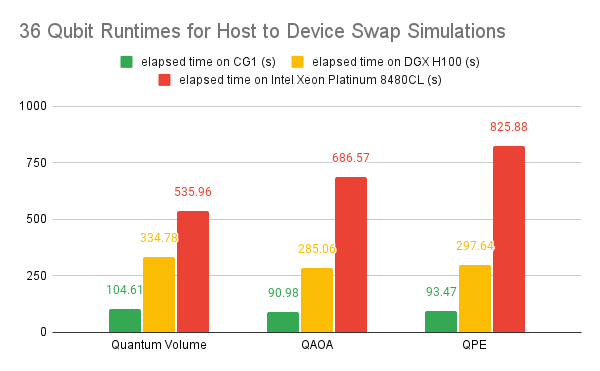
我们还进行了额外的 API 级和内核级优化,以进一步提高性能。Grace Hopper 系统提供比其他 CPU 和 Hopper 系统更好的运行时间。芯片到芯片的互连和更好的 CPU 可提供更快的运行时间。
cuQuantum 入门
cuQuantum 提供的文档有助于开始使用。如果您正在使用云服务提供商(CSP),我们建议用户查看每个主要 CSP 的市场列表。
在设置好环境之后,我们建议您查看我们在GitHub 上的基准测试套件,并验证您的 GPU 是否在基准测试中得到了使用。
如果您有任何问题、请求或疑问,请通过 GitHub 与我们联系。