
CUDA Quantum 是一种用于构建量子经典应用的开源编程模型。有用的量子计算工作负载将在异构计算架构上运行,例如量子处理器(QPU)、GPU 和 CPU,它们协同工作以解决现实世界的问题。CUDA Quantum 通过提供对这些计算架构进行协调编程的工具来加速此类应用程序。
针对多个 QPU 和 GPU 的能力对于扩展量子应用至关重要。当这些工作负载可以并行化时,将工作负载分配到多个计算端点可以实现显著加速。新的 CUDA Quantum 功能支持多 QPU 平台以及多个 GPU 无缝编程。
CUDA Quantum 中的大部分加速都是通过消息传递接口 (MPI) 完成的,MPI 是一种用于并行编程的通信协议。它对于解决天气预报以及流体和分子动力学模拟等需要大量计算的问题特别有用。现在,CUDA Quantum 可以使用 MPI 插件与任何 MPI 实现集成,因此客户可以轻松地将 CUDA Quantum 与现有的 MPI 设置一起使用。
使用多 GPU 扩展电路模拟
电路仿真依赖于量子比特 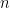
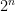
此外,nvidia-mgpu 目标可聚合节点中多个 GPU 的内存和集群中多个节点的内存,以实现扩展并消除单个 GPU 显存瓶颈。CUDA Quantum 中的这款开箱即用型软件工具适用于单个节点,与适用于数十甚至数千个节点一样。量子位数量仅受可用 GPU 资源的限制。
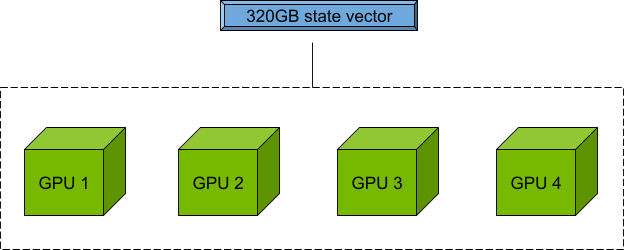
对于具有四个 GPU 且每个 GPU 均具有 80 GB 显存的节点,您可以使用 80 x 4=320 GB 显存来存储和操作量子态向量,以进行电路模拟。
使用多 QPU 实现并行化
借助多 QPU 模式,您可以对未来的工作流程进行编程,在这种工作流程中,并行化可将运行时间缩短至可用计算资源的 1 倍。
想象一下,在电路切割协议中,一次切割需要运行多个子电路,其结果在后处理中被重新拼接在一起。在传统软件中,这些子电路将按顺序执行。但是,使用 nvidia-mqpu CUDA Quantum 中的目标,这些子电路将并行执行,大幅减少运行时间。
目前,nvidia-mqpu目标是 GPU。随着量子硬件的发展速度,QPU 数据中心正在迅速逼近。
另一种常见的“令人难为情的并行”工作流程是计算具有许多项的哈密顿量的期望值。在多 QPU 模式下,您可以定义多个端点,其中每个端点都可以模拟问题的独立部分。使用 nvidia-mqpu 例如,您可以异步并行运行哈密顿量的多个项。有关详细信息,请参阅 对量子经典超级计算机进行编程。
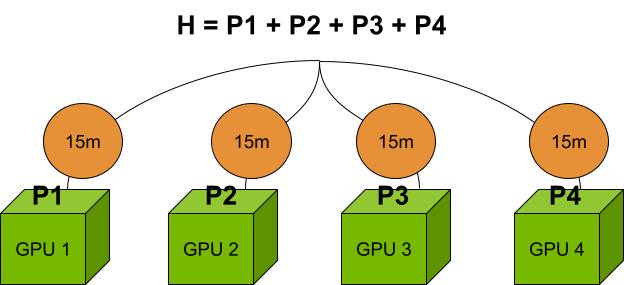
对于前面提到的由四个 GPU 组成的集群,与在单个 GPU 上计算哈密顿量项相比,并行计算速度提高了 4 倍。如果具有多个端点的顺序计算需要 1 小时,则只需 15 分钟。但是,每个 GPU 上的问题大小仍限制在 80 GB 以内。
结合使用多 QPU 和多 GPU 工作负载
如前所述,使用 NVIDIA DLSS 3 和 NVIDIA DLSS 技术nvidia-gpu目标和并行化nvidia-mqpu借助 CUDA Quantum 0。6,您现在可以将两者结合起来,从而实现大规模模拟的并行运行。
在上一个示例中,如果连续计算需要1小时,并且包含两个端点,那么每个端点只需要30分钟,因为两个端点可以由两个 NVIDIA A100 GPU支持,并且拥有160 GB的状态向量。
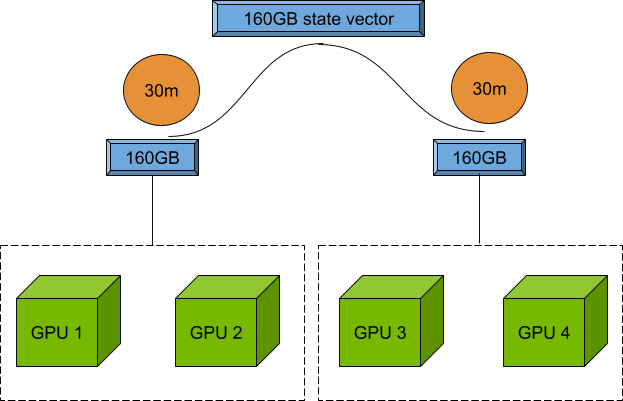
作为开发者,您现在可以尝试在问题规模和并行端点数量之间找到最佳平衡点,以最大限度地利用您的 GPU。请参阅 CUDA Quantum 文档,详细了解remote-mqpu目标。
MPI 插件
MPI 是一种用于对并行计算机进行编程的通信协议。
CUDA Quantum 利用 MPI 并使用开放 MPI 构建,开放 MPI 是 MPI 协议的开源实现。此外,还有其他流行的 MPI 实现,如 MPICH 和 MVAPICH2,以及许多高性能计算(HPC) 中心或数据中心已经建立了特定的实现。
现在,通过 MPI 插件接口将 CUDA Quantum 与任何 MPI 实现集成比以往更容易。需要一次性激活脚本来为实现创建动态库。CUDA Quantum 0。6 包含与 Open MPI 和 MPICH 兼容的插件实现。欢迎为其他 MPI 实现贡献内容,并且应易于添加。
如需详细了解如何使用 MPI 插件,请访问 使用 MPI 的分布式计算 CUDA Quantum 文档部分。
详细了解 CUDA Quantum
访问 NVIDIA/cuda-quantum 查看完整的 CUDA Quantum 0.6 版本日志。CUDA Quantum 入门指南将为您介绍 Python 和 C++ 示例。有关量子经典应用的高级用例,请参阅 CUDA 量子教程。最后,在 Omniverse 中探索代码、报告问题并提出功能建议,使用 CUDA Quantum 开源库。



