
NVIDIA Blackwell 平台的推出开启了生成式 AI 技术进步的新时代。其最前沿是新推出的 GeForce RTX 50 系列 GPU,适用于 PC 和工作站,配备具有 4 位浮点计算 (FP4) 的第五代 Tensor Cores,是加速 Black Forest Labs 的 FLUX 等高级生成式 AI 模型的必备。
随着新的图像生成模型力求达到速度、准确性、更高分辨率和复杂的提示依从性,它们变得越来越大、越来越复杂。要在 PC 和工作站的本地推理中部署这些大型复杂模型,超越 16 位和 8 位计算的优势在于。
Blackwell 与 NVIDIA TensorRT 推理工具软件生态系统相结合,可提供易于使用的库,这些库支持用于推理的 FP4 量化和部署,具有出色的性能和质量。
实现这一目标并非易事。为了利用 Blackwell 中的 4 位硬件创新,本文将深入探讨我们如何使用 NVIDIA TensorRT Model Optimizer 中复杂的 PTQ 和 QAT 技术,将 FLUX 模型成功量化为 FP4 权重。我们还将介绍如何将量化模型导出到 ONNX,以及 TensorRT 推理库如何处理量化运算符,以便将端到端推理旅程示例化为 TensorRT DemoDiffusion。最后,我们将讨论如何使用热门的 GenAI 发行版 ComfyUI 在 RTX 50 系列 GPU 上本地试用此功能。
量化模型
在 FLUX-1.Dev 中,Transformer 主干是我们的主要优化目标,因为在运行 28 个推理步骤时,它在 NVIDIA GeForce RTX 5090 上占总推理延迟的 98%。因此,降低 Transformer 的计算成本有望大幅提升性能。
我们使用 TensorRT-ModelOPT 量化了所有 Transformer 层,但最终输出层和嵌入层除外。虽然 FP4 训练后量化最初会导致图像质量轻微下降 (尤其是在小文本和数字中) 和指标轻微下降 (例如 Image Reward 和 CLIP-IQA) ,但我们通过使用基于蒸馏的 QAT 方法和来自 FLUX-1.Dev 的合成数据微调 FP4 量化模型来解决这些问题。此微调步骤成功恢复了图像清晰度,并改进了评估指标。
我们的蒸馏流程使用 BF16-precision 模型作为教师,使用 FP4-quantized 模型作为学生。此设置使低精度学生模型能够有效地从高精度教师那里学习,从而提高准确性和视觉质量。
此外,我们在 FP4 量化基础上应用了先进的 PTQ 方法 SVDQuant,从而实现了与 QAT 相媲美的质量提升,进一步缩小了量化模型和全精度模型之间的差距。
QAT 和 SVDQuant 均可提供与 BF16 基本匹配的准确度的量化模型,并且 ModelOPT v0.27 支持这两种方法。两者之间的选择取决于用户要求:
- QAT:提供简单的部署路径,没有额外的运行时开销,但在训练期间需要额外的计算资源。
- SVDQuant:消除了额外微调 (training-free) 的需求,但它增加了部署复杂性并引入了一些运行时开销,对推理性能略有影响。
用户可以选择 QAT (以牺牲额外的前期训练工作为代价) ,以最大限度提高运行时效率;也可以选择 SVDQuant (以牺牲额外的运行时处理为代价) ,以实现更快、无训练的部署。它们之间的质量比较如图 2 所示。

| Model | Image Reward | CLIP-IQA | CLIP |
|---|---|---|---|
| BF16 | 1.118 | 0.926 | 30.150 |
| FP4 PTQ | 1.096 | 0.923 | 29.860 |
| FP4 QAT | 1.119 | 0.928 | 29.920 |
| FP4 SVDQ | 1.108 | 0.927 | 30.068 |
导出成 ONNX
导出 FP4 模型需要 ONNX 1.18.0 (opset 23) 。这样可以精确定义量化节点的输入/输出张量和离线量化权重张量,确保顺利部署。ModelOpt 的导出过程依赖于标准 ONNX DQ 节点和 TensorRT 自定义运算符的组合,以实现 FP4 量化,同时通过双量化保持数值稳定性。
对于静态权重量化,BF16 模型最初使用自定义 ONNX 运算符 (TRT_FP4QDQ) 导出,该运算符封装了 BF16 权重和块大小属性。后处理步骤将这些自定义节点替换为结构化的两步去量化 (DQ) 模式。
第一个 DQ 节点通过去量化预先计算的 FP8 块级扩展张量来提取 BF16 块级扩展因子。第二个 DQ 节点从压缩的 FP4 量化权重和来自第一个 DQ 节点的 BF16 块级扩展因子中重建 BF16 去量化权重。即使在 FP8 (E4M3) 的有限动态范围内,这种双量化方案也能确保数值稳定性。
对于动态输入量化,TensorRT 自定义运算符 (TRT_FP4DynamicQuantize) 在运行时捕获 BF16 输入,并计算 FP4 量化输入及其 FP8 块级扩展系数。这些张量与 FP8 块级缩放的 FP32 缩放系数一起,通过类似的两步 DQ 模式。第一个 DQ 节点重建 BF16 块级扩展因子,第二个 DQ 节点将输入去量化回 BF16。此方法可在量化 ONNX 模型的 TensorRT 部署中实现高效融合,同时保持精度,特别是对于块级量化模型而言。
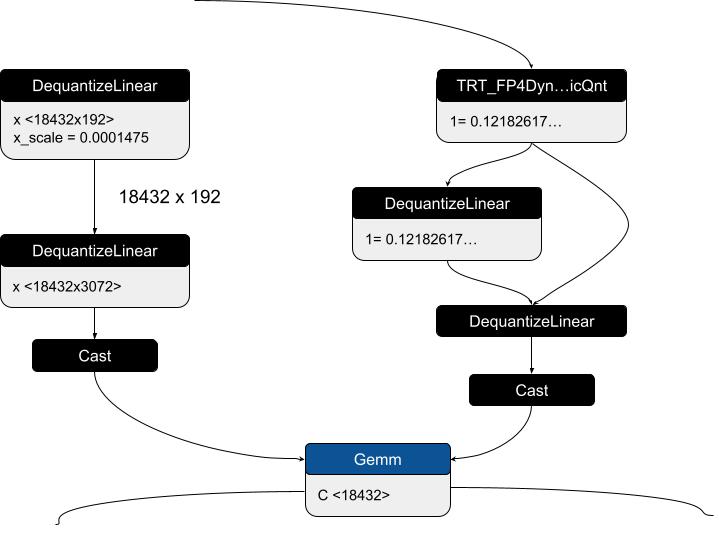
为了验证 ONNX 导出并确保数值准确性,我们实现了 ONNX 本地函数,该函数可模拟 TRT_FP4DynamicQuantize 的行为,从而启用 ONNXRuntime 验证。为简单起见,初始测试使用了 BF16 全局规模系数 (GSF),但后来扩展了本地功能,以支持 FP32 GSF,从而提高稳定性和准确性。
此外,由于量化的 ONNX 模型包含真实的量化权重而非 BF16 权重,因此有助于更轻松地在不同平台上进行分配和部署。量化的 Torch Checkpoint 也可以重新加载,以便重新导出到 ONNX。然后,将最终的 ONNX 模型转换为 TensorRT 引擎,以便在目标 GPU 类型上进行推理。
这种方法可确保高效的 FP4 量化,同时保持准确性、优化内存使用量并简化大规模部署的模型分发。查看 Black Forest Labs 的 FP4 ONNX Transformer 模型示例。
使用来自 TRT 10.8 的 FP4 加速性能
NVIDIA Blackwell GPU 引入了对新数据类型 FP4 的硬件支持。借助 FP4,Blackwell 可以更大限度地提高性能,同时保持可用的任务精度。FP4 还提供优于 INT4 的推理准确性。
FP4 的一些优势包括:
- 计算吞吐量是 FP32 的 16 倍;在 RTX5090 的理论 TOPS 下,是 FP8 的 4 倍。
- 降低 DRAM 和 L2 占用空间。
- 降低 DRAM 到 L2 到 SM 的带宽消耗。
- 降低存储和运输要求。
以 GEMM 运算为例,FP4 量化由一组基元运算表示,如下所示。X/Y/W 是 GEMM 的输入张量/输出张量/权重张量,S 是量化运算使用的缩放系数。

在 FLUX 工作流中,Transformer 通过 FP4 推理加速。除 Transformer 开头和结尾的层外,所有全连接 (FC) 层都在 FP4 中运行。与 FP8 相比,FC 层的性能最高可达到 FP8 的 3.1 倍。Transformer 中的多头注意力 (MHA) 部分在 FP8 中运行。
在 FLUX Transformer 中,还有一些层 (例如 normalization 层) 未被量化为较低精度以实现更好的图像质量。借助 Transformer 主干中的细粒度混合精度解决方案,Geforce GPU 上的最终交付性能如下所示:
| Model | 5090 fp16* | 5090 fp8 | 5090 fp4 | 4090 fp8* |
| FLUX.1-dev(包含 30 个 diffusion 步骤) | 10930.96ms | 6680.93ms | 3852.75ms | 10620.37ms |
| FLUX.1-schnell (w/ 4 diffusion steps) | 4427.43ms | 912.53ms | 590.56ms | 3385.43ms |
演示适用于 FLUX.1-Dev 和 Schnell 的 demoDiffusion 示例
Black Forest Labs FLUX 是一套图像生成模型。TensorRT 演示 Diffusion 展示了如何加速模型套件。工作流使用为每个模型构建的 TensorRT 引擎按顺序运行其组件。
输入文本提示首先由 CLIP 和 T5 文本编码器处理。然后,降噪器会将文本编码器生成的文本嵌入与隐空间中的纯噪声向量一起使用。降噪器是一种扩散转换器,它根据文本嵌入的信息对噪声向量进行迭代降噪。然后,VAE 解码器会将隐空间中的降噪向量处理为像素空间中的图像。
考虑 FLUX pipeline 使用的四个模型的大小。Clip 文本编码器、T5 文本编码器、diffusion transformer 和 VAE 模型的大小分别为 246 MB、9.52 GB、23.8 GB 和 168 MB,总大小为 33.734 GB,适用于 FP16 模型。
由于模型较大,我们无法直接在显存低于 24 GB 的 RTX GPU 上运行工作流。此问题可通过 low-vram 模式解决,该模式可按需加载模型,并在执行推理后卸载模型。由于模型按顺序运行,我们可以显著降低 GPU 显存使用量。下表显示了针对不同精度使用 low-vram 模式节省的 GPU 显存。
| Precision | Default mode | With low-vram |
|---|---|---|
| FP16 | 39.3 GB | 23.9 GB |
| BF16 | 35.7 GB | 23.9 GB |
| FP8 | 24.6 GB | 14.9 GB |
| FP4 | 21.67 GB | 11.1 GB |
除了使用 FP4 加速标准开发工作流之外,demoDiffusion 还提供了控制图像生成过程的方法,方法是使用 FLUX ControlNet 工作流以边缘或深度图的形式提供结构线索,即 depth 和 canny。用户可以通过提供边缘 (canny) 或深度图以及指导图像生成过程的文本提示来保留图像构图。ControlNet 工作流不同于标准开发工作流,其在 Diffusion Transformer 架构中,以 Control 图像的形式接收额外的输入,以使用文本和图像信息执行降噪。depth 和 canny 控制网络的 FP8 校正数据集位于 GitHub 上。


试用 TensorRT 10.8 demoDiffusion,以运行具有峰值 FP4 性能的 FLUX.1-Dev 和 FLUX.1-Schnell 模型。
集成 ComfyUI
热门的图像生成工具 ComfyUI 现已支持在 Blackwell GPU 上运行。此外,为简化低精度推理的采用,专用的 NVIDIA NIM 推理微服务提供了易于使用的解决方案,可通过自定义节点与 ComfyUI 集成。
通过使用自定义 NVIDIA NIM 节点,用户可以使用高质量的 FLUX 流程生成图像,同时受益于专为在消费者桌面上高效运行而设计的优化 TensorRT 引擎。

专门的蓝图展示了如何使用 FLUX NIM 设置 ComfyUI 工作流,以生成文本到图像。为简化流程,我们提供了 NIM 安装程序,便于设置 WSL2 环境和 NIM 部署。最终产品使用户能够在 FP4 中使用 FLUX 引擎生成高质量图像。此外,用户可以通过深度和 Canny 地图引导更好地控制最终输出,从而提高图像精度。
开始使用
在本文中,我们了解了先进的模型如何通过量化器、编译器和运行时的软件工具链经历多个优化步骤,以利用我们最新的 4 位硬件创新。这将生成式 AI 的强大功能带到了云端以外的桌面或工作站。如果您拥有全新的 50 系列 RTX GPU,请使用 TensorRT demoDiffusion 尝试整个制作流程。






