自动语音识别( ASR )研究通常侧重于高资源语言,如英语,它由数十万小时的语音支持。最近的文献重新关注更复杂的语言,如日语。与其他亚洲语言一样,日语有大量的基本字符集(普通白话中使用了 3000 多个独特的字符),并提出了独特的挑战,例如多个词序。
这篇文章讨论了最近提高日语 ASR 准确性和速度的工作。首先,我们改进了 Conformer ,这是一种最先进的 ASR 神经网络架构,在训练和推理速度方面取得了显著的改进,并且没有精度损失。其次,我们增强了一个具有多头部自我注意机制的纯深度卷积网络,以丰富输入语音波形的全局上下文表示的学习。
语音识别中的深度稀疏整合器
Conformer 是一种神经网络体系结构,广泛应用于多种语言的 ASR 系统中,并取得了较高的精度。然而, Conformer 在训练和推断方面都相对较慢,因为它使用了多头自我注意,对于输入音频波的长度,其时间/内存复杂度为 quadratic 。
这妨碍了它对长音频序列的高效处理,因为在训练和推断过程中需要相对较高的内存占用。这些激励了稀疏 关注高效 Conformer 构建。此外,由于注意力较少,内存成本相对较低,我们能够构建一个更深的网络,可以处理由大规模语音数据集提供的长序列。
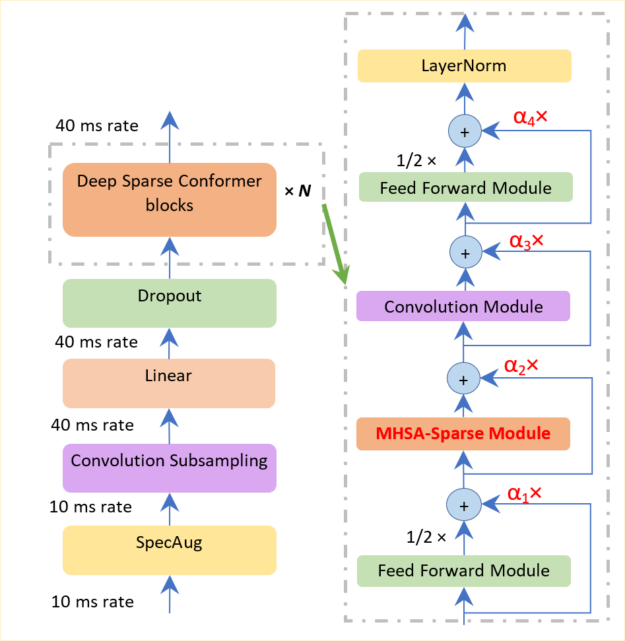
如图 1 所示,我们在两个方向上改进了 Conformer 长序列表示能力:稀疏和深入。我们使用一个排名标准,只选择一小部分占主导地位的查询,而不是整个查询集,以节省计算注意力得分的时间。
在执行剩余连接时,使用深度规范化策略,以确保百级 Conformer 块的训练。该策略包括使用一个函数来贴现编码器和解码器部分的参数,该函数分别与编码器层和解码器层的数量相关。
此外,这种深度规范化策略可确保成功构建 10 到 100 层,从而使模型更具表现力。相比之下,与普通 Conformer 相比,深度稀疏 Conformer 的时间和内存成本降低了 10% 到 20% 。
用于语音识别的注意力增强型 Citrinet
NVIDIA 研究人员提出的 Citrinet 是一种基于端到端卷积连接时态分类( CTC )的 ASR 模型。为了捕获本地和全局上下文信息, Citrinet 使用 1D 时间通道可分离卷积与子字编码、压缩和激励( SE )相结合,使整个体系结构与基于变压器的同类产品相比达到最先进的精度。
将 Citrinet 应用于日本 ASR 涉及几个挑战。具体来说,与类似的深度神经网络模型相比,它的收敛速度相对较慢,并且更难训练出具有类似精度的模型。考虑到影响 Citrinet 收敛速度的卷积层多达 235 个,我们旨在通过在 Citrinet 块的卷积模块中引入多头部注意来减少 CNN 层,同时保持 SE 和剩余模块不变。
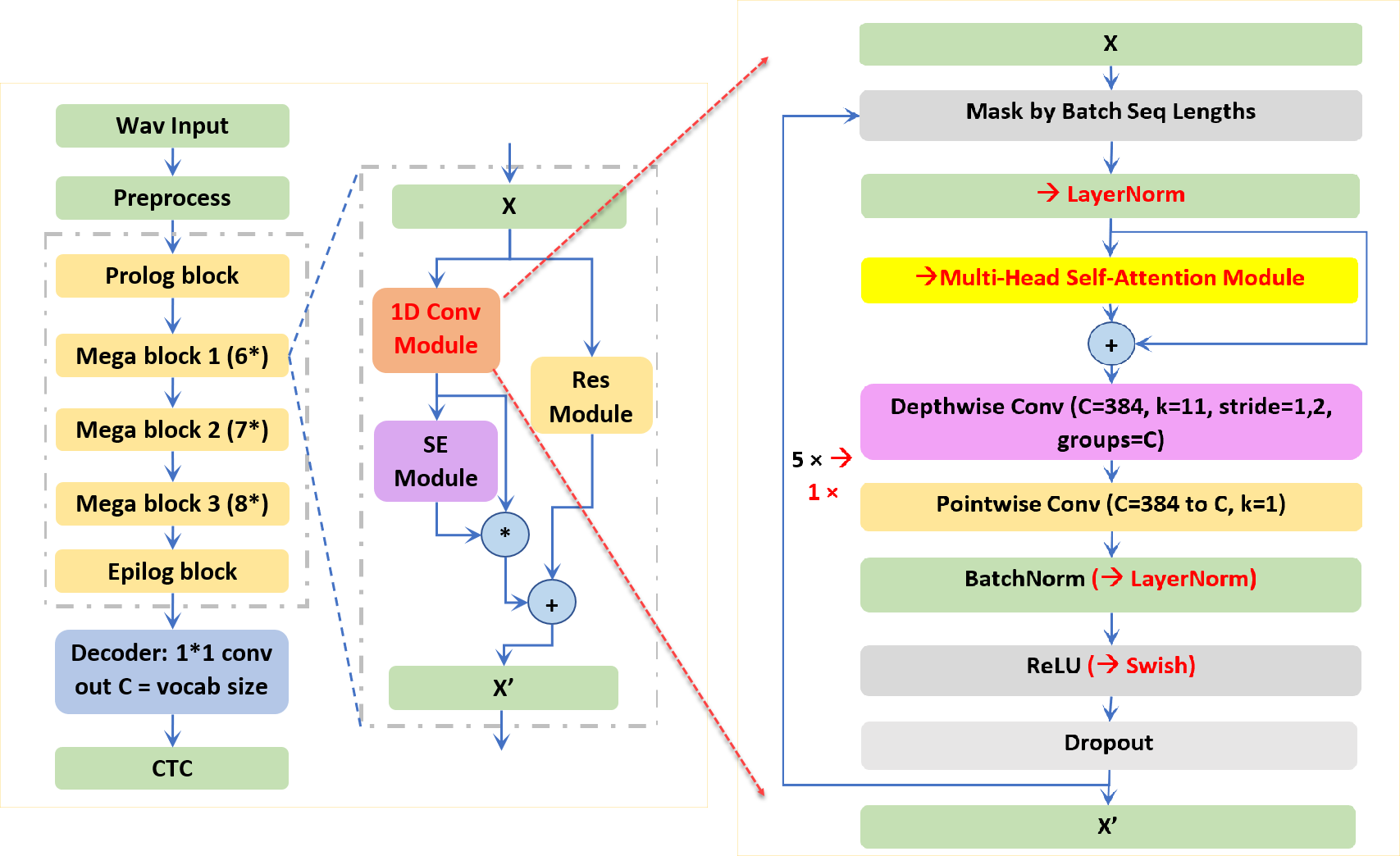
如图 2 所示,加快训练时间需要在每个注意力增强的 Citrinet 块中减少八个卷积层。此外,考虑到自我注意对输入音频波的长度具有二次 的时间/记忆复杂性,我们将原来的 23 个 Jasper 块缩减为 8 个块,模型尺寸显著减小。这种设计确保了注意力增强的 Citrinet 对于从 20 秒到 100 秒的长语音序列达到了可比的推理时间。
初步实验表明,基于注意力的模型收敛于 100 到 200 个时间点,而 Citrinet 收敛到最佳错误率需要 500 到 1000 个时间点。在日本 CSJ-500-hour 数据集上的实验表明,与 Citrinet ( 80% 的训练时间)和 Conformer ( 40% 的训练时间和 18.5% 的模型大小)相比, Citrinet 的注意力需要更少的块层,收敛速度更快,字符错误率更低。
总结
通常,我们提出两种新的架构来构建端到端的日本 ASR 模型。在一个方向上,我们改进了基于变压器的 Conformer 训练和推断速度,并保持了其准确性。我们成功地构建了更稀疏和更深入的 Conformer 模型。我们还通过引入多头部自我注意机制和修剪 80% 的 CNN 层,提高了基于 CNN 的 Citrinet 收敛速度和准确性。这些建议是通用的,适用于其他亚洲语言。
要了解有关日语 ASR 模型的更多信息,请参阅 Deep Sparse Conformer for Speech Recognition and Attention Enhanced Citrinet for Speech Recognition ,或观看相关 INTERSPEECH 2022 会议、神经传感器、流式 ASR 和新型 ASR 模型。