在过去十年中,深度学习技术在计算机视觉 (CV) 任务中的应用大幅增加。卷积神经网络 (CNN) 一直是这场革命的基石,展示了卓越的性能,并在视觉感知方面实现了显著进步。
通过采用本地化滤镜和分层架构,CNN 已证明擅长捕捉空间层次结构、检测模式,以及从图像中提取信息丰富的特征。例如,在用于图像识别的深度残差学习中,卷积层表现出平移等方差,使其能够泛化为平移和空间转换。然而,尽管 CNN 取得了成功,但其在捕获远程依赖项和全局上下文理解方面仍存在局限性,这在需要精细理解的复杂场景或任务中变得越来越重要。
相比之下,Transformer 架构在计算机视觉领域中正变得越来越有吸引力,这得益于其在自然语言处理 (NLP) 领域的成功应用。正如论文Attention Is All You Need中所展示的,Transformer 通过避免局部卷积,提供了一种自注意力机制,能够支持视觉特征之间的全局关系。这种注意力机制使得 Transformer 能够捕获图像元素之间的远程交互,从而促进了对视觉场景的更全面理解,进而提高了模型的准确性。图 1 展示了一个视觉应用中的自注意力机制示例。对于更多详细信息,请参阅论文A Visual Representation of 16+16 Words: Transformers for Large-Scale Image Recognition 和 Swin Transformer: Hierarchical Vision Transformer using Shifted Windows。
然而,自注意力在有效捕获图像中的本地上下文信息方面遇到了挑战,这突出了更广泛的全局感知领域的重要性。此外,与自注意力相关的计算复杂性的特征是视觉特征元素之间的二次交互,这对在计算机视觉中处理大型图像构成了重大挑战。
处于创新前沿的汽车行业正日益认识到需要广泛采用 Transformer-like 网络。然而,集成这些网络带来了独特的挑战。具体来说,在NVIDIA TensorRT特定操作系统的框架NVIDIA DRIVE产品,与标准用例相比,支持有限的专用功能。
这些专用 API 仍然包括高度优化的卷积运算等,反映了该行业对优化卷积网络的长期承诺。我们的目标是战略性地利用这些优化的卷积运算来推动 Transformer 网络的更高效和更有效的实施。我们的目标是使汽车行业能够满足现代应用程序的动态需求,同时在现有软件框架和硬件平台的限制内协调工作。
在认识到 self-attention 的价值的同时,还必须更加重视卷积的影响,尤其是在 CV 任务中。这一点正确,原因如下:
- 如前所述,图像和文本之间的固有特性差异凸显了将自注意力直接应用于 CV 任务的挑战,需要混合方法或结合自注意力层和卷积层优势的替代架构。
- 在自动驾驶汽车 (AV) 应用中,高分辨率图像通常用于实时应用。硬件平台上的自注意力计算优化已落后于自动驾驶行业和芯片制造商新 Transformer 的迅速出现,无法满足用户需求。当前基于 Transformer 的模型的实现未充分利用 GPU 的计算能力。
- 在自动驾驶中的许多生产情况下,在深度学习运行时库的受限模式下执行的推理可能尚未完全支持先进的 Transformer 网络。例如,Transformer 中的当前操作在 TensorRT 受限模式下并未完全涵盖。
本文介绍了我们最近在使用全卷积网络在 Transformer 模型中仿真注意力机制方面的工作。我们的方法将针对当前 GPU 硬件平台优化的传统卷积核的优势与自注意力模块相结合,从而实现了优于当代 Transformer 类模型的性能。我们的工作解决了存在计算机视觉问题的各行各业中用户对 Transformer 可用性日益增长的需求。我们的方法不仅在 TensorRT 上运行时能够提供更快的延迟性能和可比较的准确性,而且还完全兼容 TensorRT 受限模式。
融合卷积和自注意力
最近的研究表明,人们对融合 CNN 和 Transformer 的优势的兴趣与日俱增。通过将局部特征信息的卷积运算与用于全局特征关系的自注意力模块相结合,研究人员旨在增强这两种架构的功能。
Swin Transformer 是一个值得注意的例子。最近的 Vision-transformer™ 引入了偏移窗口的概念,使 Transformer 能够有效地学习局部特征。通过在较小区域内整合局部自注意力,Swin 捕获局部关系和依赖关系,从而提高需要细粒度信息的任务的性能。然而,随着输入大小的增长,自注意力的计算复杂性二次增加,这可能会迅速造成延迟负担,从而带来挑战。
为解决这一问题,研究人员探索了卷积运算和自注意力的合并。基于卷积的方法可以模仿 Transformer 训练配置,或者在网络的各个部分有选择地使用卷积和自注意力。
例如,卷积视觉 Transformer (CvT)直观地将卷积特征整合到自注意力模块中。Conv-Next 另一方面,与传统 CNN 的视觉 Transformer 类似。尽管如此,这种方法无法明确解决传统卷积网络模型中常见的有限接受场问题。与自注意力不同,卷积运算拥有固定的接受场大小和一组共享的参数。这种特性使卷积能够以局部聚焦和参数高效的方式处理输入数据。
卷积自注意力
我们展示了 Convolutional Self-Attention (CSA),该模型以用于视觉任务的卷积运算完全取代了传统的注意力机制,从而能够对本地和全局特征关系进行建模。通过仅依赖卷积,我们的整体模型在高度优化的 GPU 和深度学习加速器上实现了显著的效率。与现代 Transformer 网络相比,实验结果令人信服地证明了其具有竞争力的准确性,同时显示出更高的硬件利用率和显著降低的部署延迟。
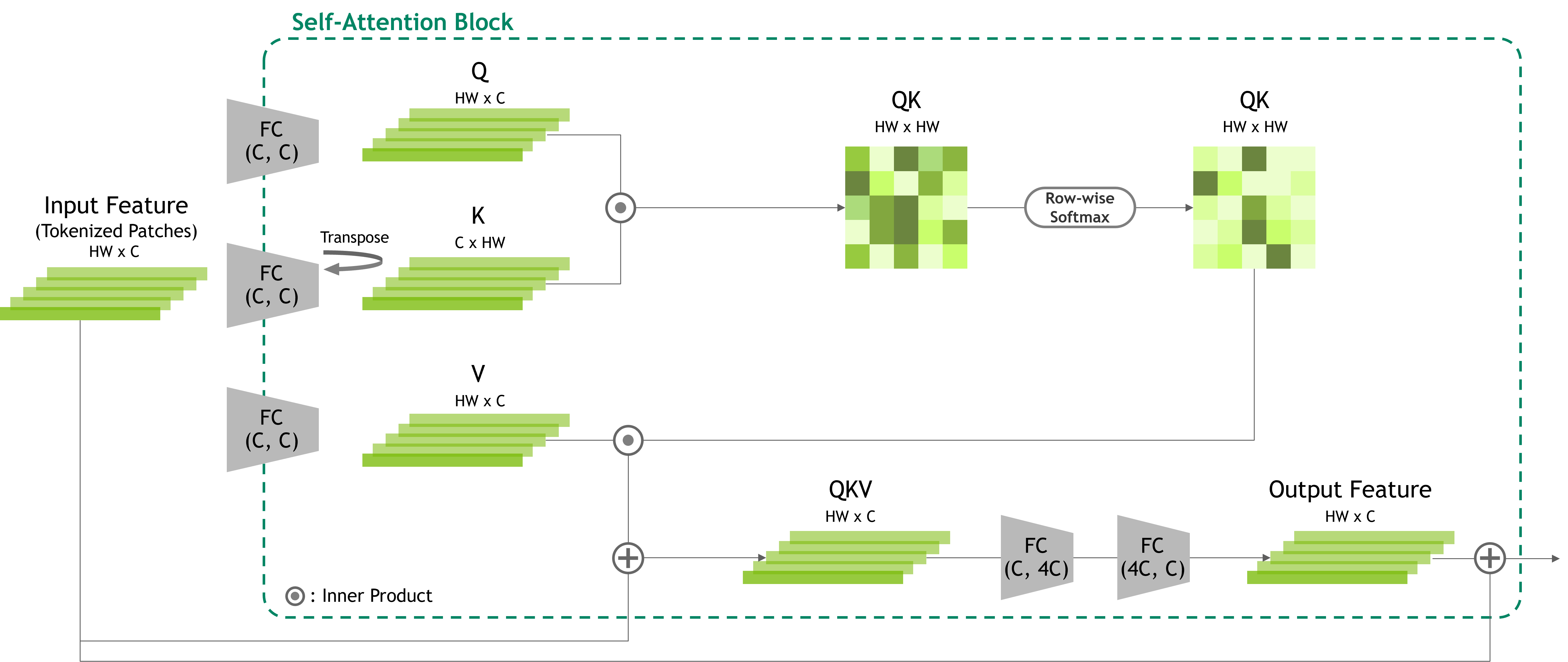
整个建议的模型包括重复使用向下采样卷积层和我们建议的 CSA 块,以及其馈向转发流,如图 2 所示。每个 CSA 块都使用卷积运算模拟 Transformer 块。

图 3 显示了 CSA 模块的结构和流程。CSA 模块的实现可能有所不同,但旨在模拟自注意力的关系编码过程。为了实现关系编码,我们沿通道轴旋转张量,将通道特征转换为空间格式(高度和宽度)。
此旋转特征张量在旋转前按元素顺序与原始张量相乘,然后是卷积。这复制了第一个自注意力内积,但概念有所不同,因为我们的方法允许通过元素顺序乘法和卷积进行一对多关系嵌入。然后,生成的关系特征张量被归一化、激活,并与输入张量的另一个视觉特征相乘,值(V)。
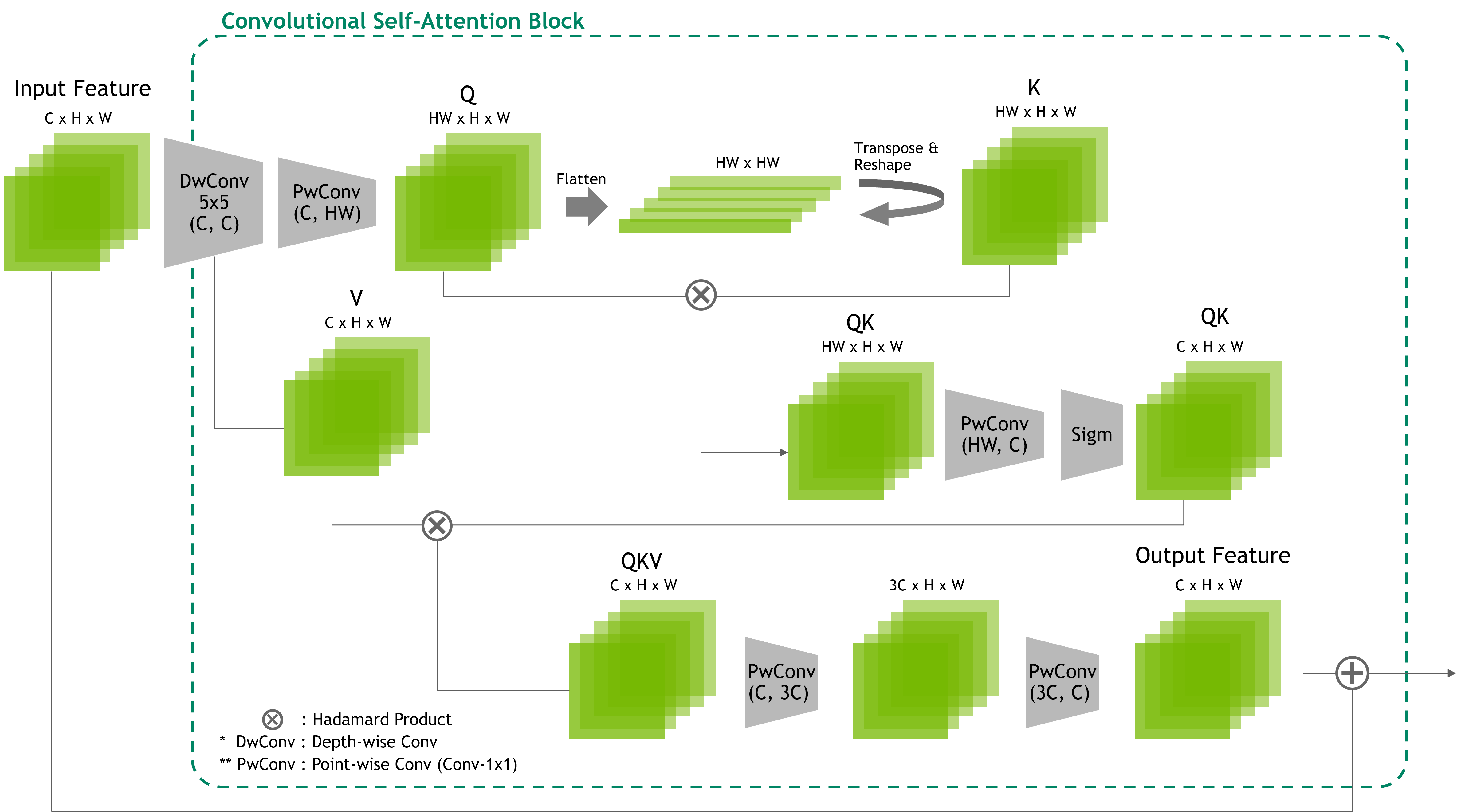
我们的方法通过策略性地重新排列特征张量并利用本地卷积核窗口来实现全局感知场。这种显式关系编码可将每个特征像素投影到所有其他特征像素,从而实现全面的像素间交互。这是因为我们方法中张量的结构重新排列使卷积窗口能够捕获视觉特征之间的全局关系,利用卷积运算的优势进行一对一多视觉特征关系推理。
相比之下,CSA 模块通过内部产品运算对所有特征像素之间的关系进行编码,这可能会给硬件带来巨大的计算负担。通过实现一对一关系编码,我们的方法可以减少计算负载,同时保留在整个特征图中捕获远程依赖项和结构信息的能力。
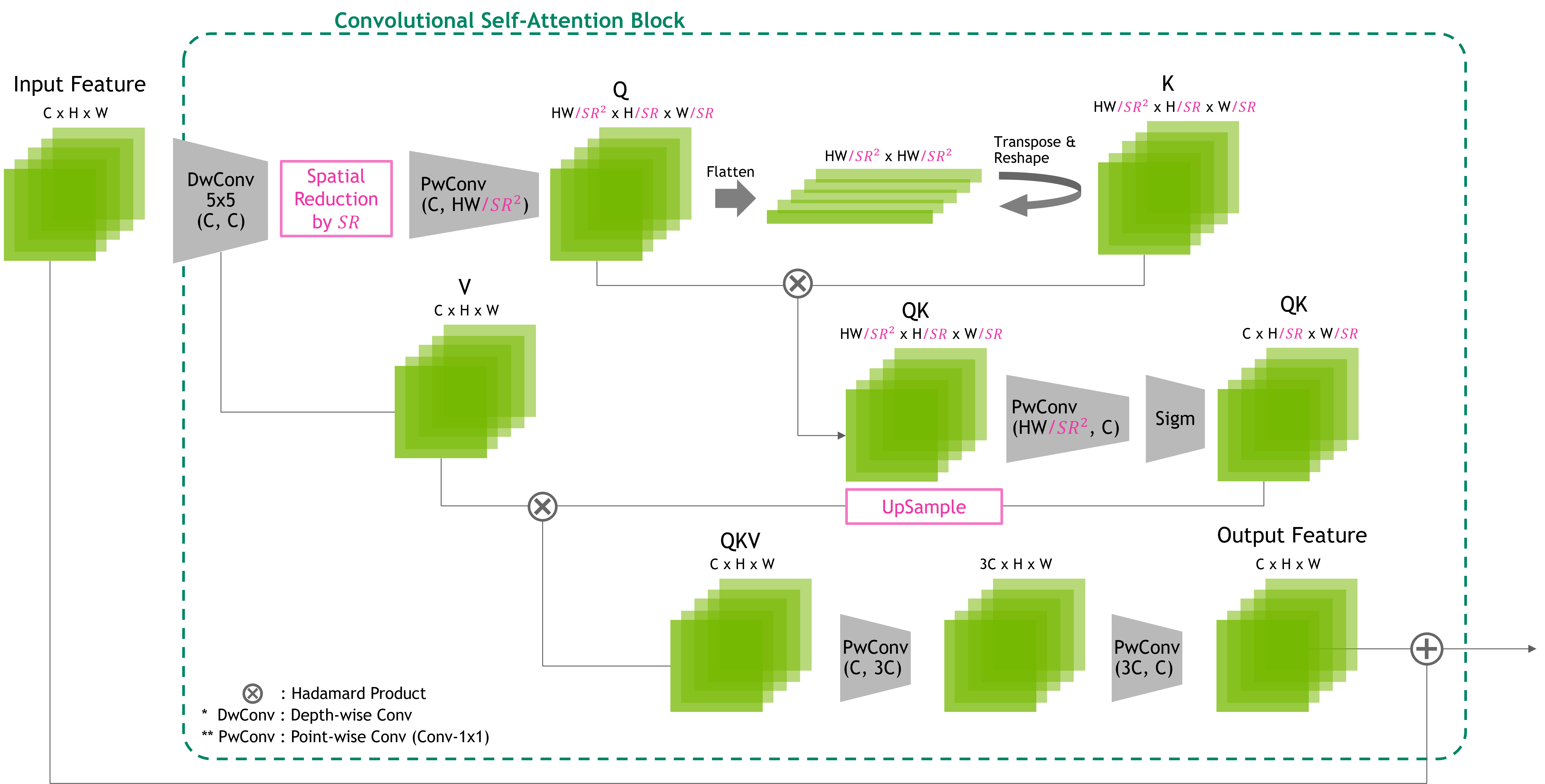
为了管理因输入大小增加而产生的二次计算增量,我们的设计可以加入空间归约层以减小张量大小,如图 4 所示。这不仅有助于减少计算开销,而且还使网络能够专注于视觉特征之间的区域关系,而视觉特征带有更多语义,而不是像素级关系。
准确性和延迟方面的性能
将 CSA 模块与使用 ImageNet-1K 数据集的相关当代 CV 分类模型进行比较,在准确性和使用 TensorRT-8.6.11。4 测量的验证数据和延迟方面进行比较。我们的目标是在受限模式下应用 CSA 的自动驾驶汽车,因此在 NVIDIA DRIVE Orin 平台上对这些模型进行比较。 NVIDIA DRIVE Orin 是一种高性能、高能效的片上系统 (SoC),是用于自动驾驶汽车的 NVIDIA DRIVE 平台的一部分。
基准测试条目
- Swin Transformer 网络是一种创新的深度学习架构,将最初由视觉 Transformer (ViT) 等模型推广的自注意力机制与分层和可并行设计相结合。
- ConvNext 模型通过逐步转换标准 ResNet 来开发,使其类似于视觉 Transformer,在特定任务中与 Swin Transformer 竞争有利,同时保持传统卷积网络的简单性和效率。
- 卷积视觉 Transformer(CvT)通过在ViT中引入卷积操作,实现了性能和效率的显著提升。在ImageNet-1k数据集上的表现非常具有竞争力,同时模型参数更少,计算量也更低。
基准测试条目的依据在于其与 CSA 的相关性和当代重要性。在我们的实验中,我们特别将 CSA 与模型大小相似的 Swin-tiny、ConvNext-tiny 和 CvT-13 基准进行了比较,如表 1 所示。
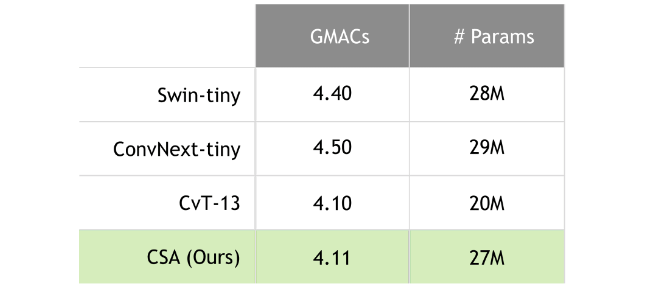
我们在 TensorRT 中使用两种精度模式(FP16 和混合精度模式,即启用 FP32、FP16 和 INT8)来展示结果。这种方法使我们能够平衡评估模型的性能。使用训练后量化 (PTQ) 实现了所有方法的模型量化,并在校准过程中使用了 500 张图像。
我们使用 ImageNet 数据集上的 Top-1 精度来测量准确性,并在毫秒内报告不同批量大小(1、4、8 和 16)的推理延迟。这可确保我们以公平无偏的方式进行比较。我们可以进一步优化 CSA 的 TensorRT 推理,在准确性和延迟之间取得平衡,从而在可接受的准确性限制范围内利用延迟。
在追求优化精度模式以提高延迟并可能牺牲准确性的过程中,量化策略成为了一个令人信服的解决方案。TensorRT 提供了各种量化方法,包括百分位数、平均平方误差 (MSE) 和量化,所有这些方法都证明了在减轻精度损失方面的有效性。我们的研究以跨一系列基准方法的混合精度推理为中心,在该研究中,我们选择了量化方法。这种方法以信息论为基础,通过分配代码来最大限度地减少平均代码词长,从而最大限度地降低准确性,但值得注意的是 CvT 基准测试除外。
尽管包括 CSA 在内的所有基准测试在降低精度后仍保持着难以区分的准确性水平,但尽管精度降低,ConvNext 在一定程度上优于其他基准测试。相反,CSA 的准确性下降幅度最小。
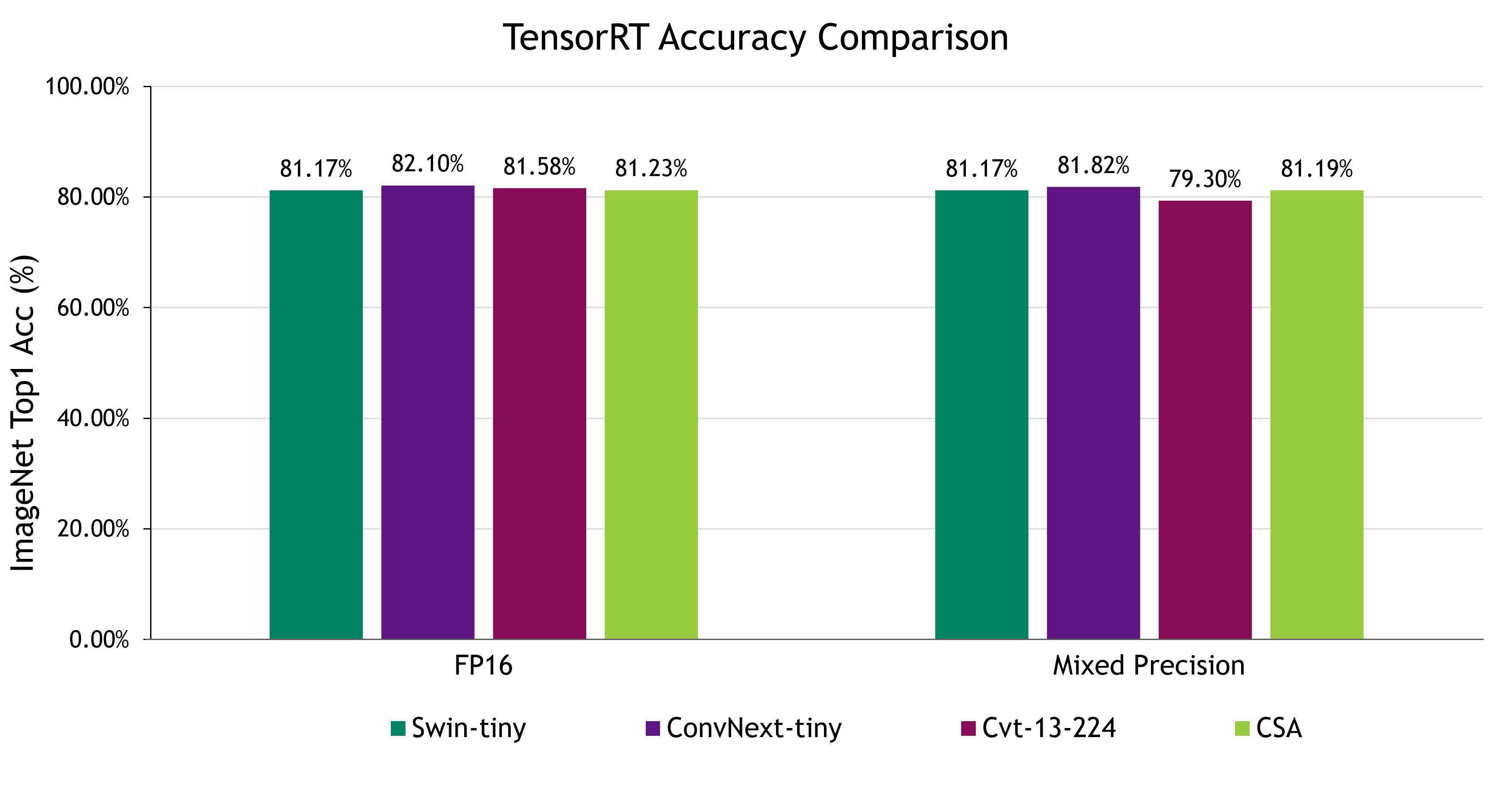
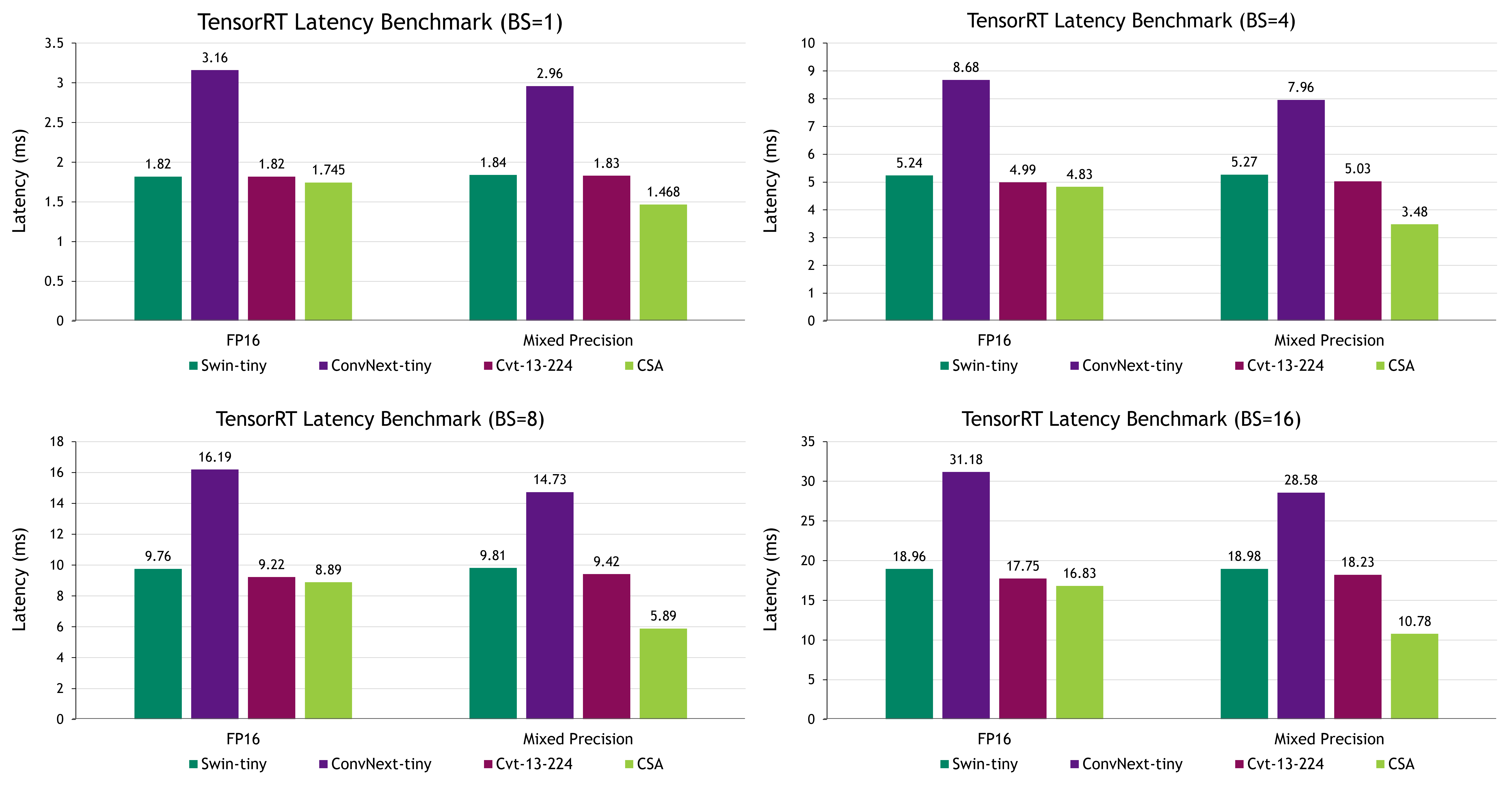
ConvNext 在 FP16 和混合精度模式下都以其准确性而出名,但同时兼具相对较慢的延迟。在这种情况下,CSA 成为一个极具竞争力的选择,提供了值得称道的准确性,同时实现了最快的延迟。
与 ConvNext-tiny 相比,在批量大小为 1 的情况下,CSA 的延迟显著降低了 49%,同时保持了较高的准确性性能。这突出了 CSA 的强大功能,并将其定位为在这种情况下的有力选择。
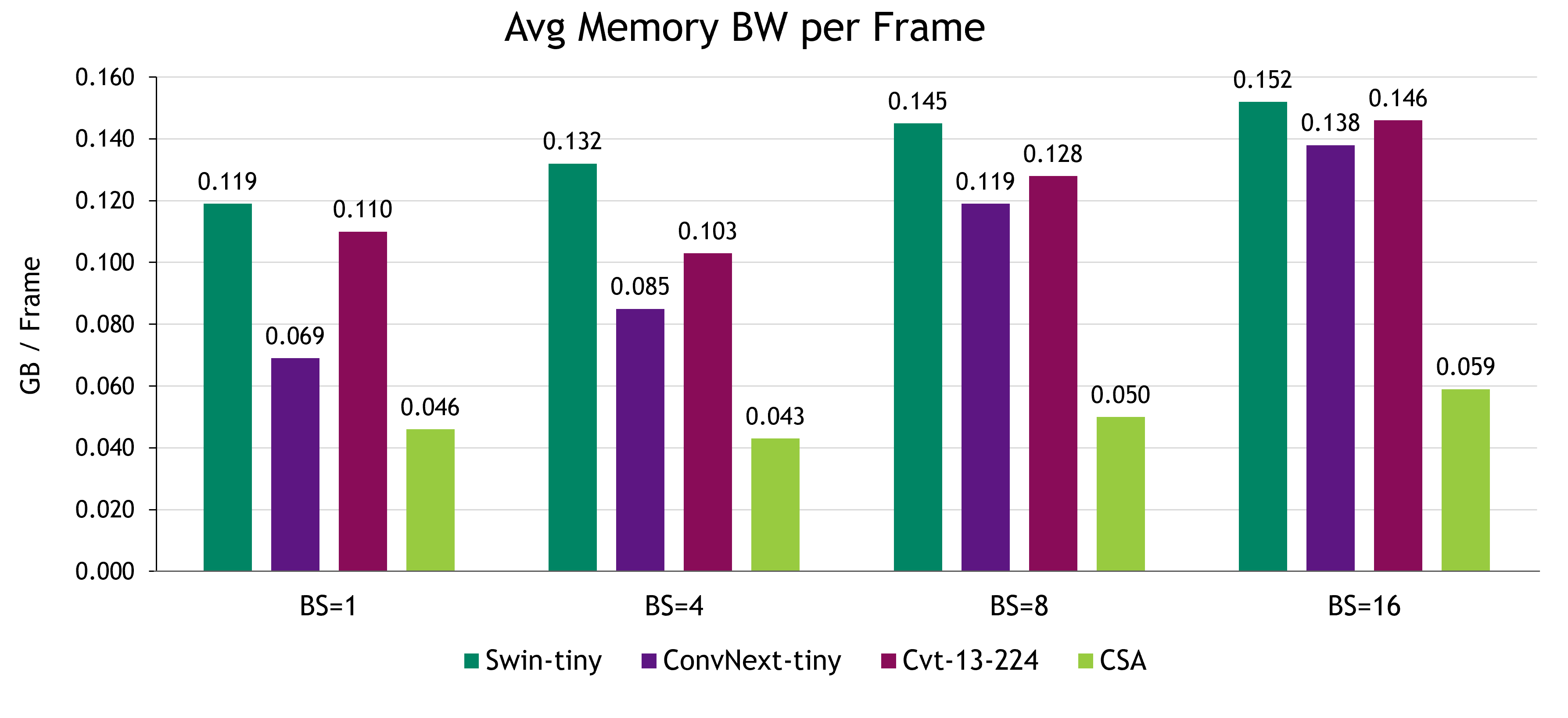
CSA 在推理期间的性能优于高效内存流量基准测试,因此每帧的平均显存带宽最少。应该注意的是,即使批量大小增加,CSA 的内存流量也是持久的,而基准测试中的其他方法也在逐渐增加。
得益于 CSA 的策略设计,我们的模型可以在 TensorRT 中利用高效的卷积核实现,从而实现高效计算,在准确度和延迟之间实现协调平衡,同时与 TensorRT 受限模式完全兼容。其他精度更高或延迟更低的方法都不兼容。在实践中,这使得目前难以在需要 TensorRT 受限模型的生产环境中部署这些模型。
结束语
与尝试从 Transformer 模型中提取注意力模块的其他卷积模型不同,卷积自注意力 (CSA) 仅结合简单的张量形状操作,仅使用卷积明确查找特征 1 对多之间的关系。我们的方法与相关方法之间的区别如下所示:
- 通过从战略角度重新排列特征张量,显式关系编码可确保每个特征像素都投影到所有其他特征像素,从而在利用本地卷积核窗口的同时实现全局接受场。
- 传统的自注意力模块对所有输入特征之间的关系进行编码,会增加相对于输入大小的计算成本,相比之下,我们的方法在每个阶段都以分层方式通过卷积运算简洁地实现了多对多关系编码,同时缩小了输入大小,从而降低了硬件的计算负载。
- 这些优势可为规模相当的模型提供更快的推理速度,并可美或超过其他方法的性能。
尤为重要的是,CSA 在 TensorRT 受限模型中运行时不会出现任何故障和麻烦,因此适合用于安全关键型应用的自动驾驶汽车生产。我们希望 CSA 能够为使用 NVIDIA DRIVE 平台及更高版本的客户提供参考模型设计。有关更多信息,请访问 NVIDIA 开发者 AV 论坛 和 TensorRT 论坛。