多摄像头应用越来越流行;它们对于实现自主机器人、智能视频分析( IVA )和 AR / VR 应用至关重要。无论具体的用例如何,都必须始终执行一些常见任务:
- 俘虏
- 预处理
- 编码
- 陈列
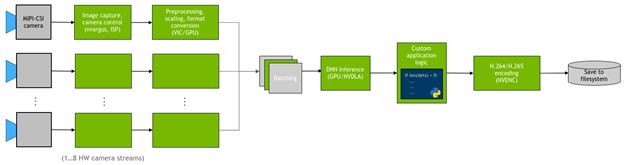
在许多情况下,您还希望在摄像头流上部署 DNN ,并在检测上运行自定义逻辑。图 1 显示了应用程序的一般流程。
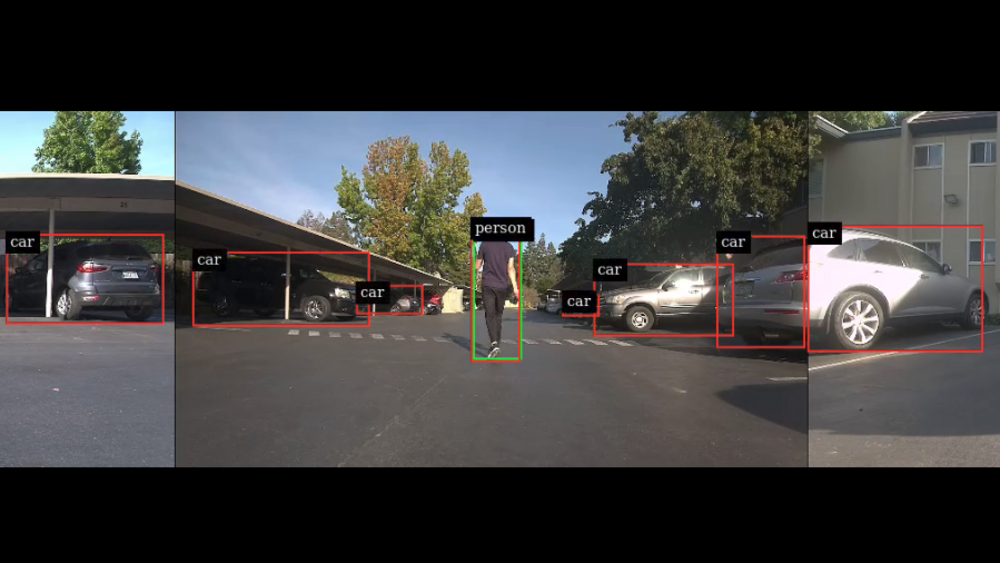
在本文中,我将展示如何在 NVIDIA Jetson 平台上高效地实现这些常见任务。具体来说,我介绍了 jetmulticam ,一个易于使用的 Python 软件包,用于创建多摄像头管道。我在一个带有环绕摄像头系统的机器人上演示了一个特定的用例。最后,我添加了基于 DNN 对象检测的自定义逻辑(人员跟踪),以获得以下视频中显示的结果:
多摄像头硬件
选择相机时要考虑的参数有很多:分辨率、帧速率、光学、全局/滚动快门、界面、像素大小等。有关 NVIDIA 合作伙伴提供的兼容摄像头的更多信息,请参阅 comprehensive list 。
在这个特定的多摄像头设置中,可以使用以下硬件:
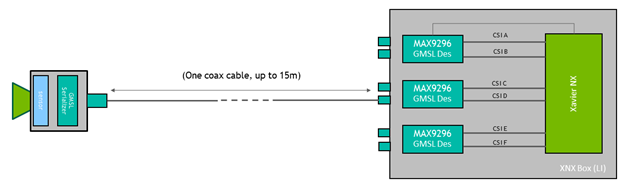
- NVIDIA Jetson Xavier NX 单元
- Leopard Imaging 提供的支持 GMSL2 的 carrier board
- Leopard Imaging 的 3 × IMX185 GMSL2 cameras
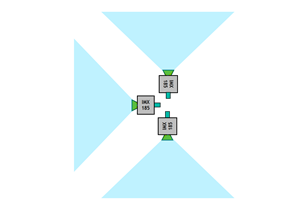
IMX185 摄像头的视野约为 90 °。如图 2 所示,以 270 °的总视场相互垂直安装。
摄像头使用 GMSL 接口,该接口在距离 Jetson 模块几米远的位置提供了很大的灵活性。在这种情况下,可以将摄像头升高约 0.5 米,以获得更大的垂直视野。
开始使用 Jetmulticam
首先,在 Jetson 板上下载并安装 NVIDIA Jetpack SDK 。然后,安装jetmulticam软件包:
$ git clone https://github.com/NVIDIA-AI-IOT/jetson-multicamera-pipelines.git $ cd jetson-multicamera-pipelines $ bash scripts/install_dependencies.sh $ pip3 install Cython $ pip3 install .
基本多摄像机流水线
安装完成后,可以使用CameraPipeline类创建基本管道。通过 initializer 参数传递要包含在管道中的摄影机列表。在下面的示例中,元素[0, 1, 2]对应于设备节点/dev/video0、/dev/video1和/dev/video2。
from jetmulticam import CameraPipeline p = CameraPipeline([0, 1, 2])
就这样,管道已经初始化并启动。现在,您可以从管道中的每个摄像头读取图像,并以numpy阵列的形式访问它们。
img0 = p.read(0) # img0 is a np.array
img1 = p.read(1)
img2 = p.read(2)
通常,在一个循环中读取相机是很方便的,如下面的代码示例所示。管道从主线程异步运行,read始终获取最新的缓冲区。
while True:
img0 = p.read(0)
print(img0.shape) # >> (1920, 1080, 3)
time.sleep(1/10)
更复杂的人工智能管道
现在,您可以构建更复杂的管道。这一次,使用CameraPipelineDNN类组成更复杂的管道,以及 NGC 目录 PeopleNet 和 DashCamNet 中的两个预训练模型。
import time
from jetmulticam import CameraPipelineDNN
from jetmulticam.models import PeopleNet, DashCamNet
if __name__ == "__main__":
pipeline = CameraPipelineDNN(
cameras=[2, 5, 8],
models=[
PeopleNet.DLA1,
DashCamNet.DLA0,
# PeopleNet.GPU
],
save_video=True,
save_video_folder="/home/nx/logs/videos",
display=True,
)
while pipeline.running():
arr = pipeline.images[0] # np.array with shape (1080, 1920, 3)
dets = pipeline.detections[0] # Detections from the DNNs
time.sleep(1/30)
下面是管道初始化的分解:
- 摄像机
- 模型
- 硬件加速
- 保存视频
- 显示视频
- 主回路
摄像机
首先,与前面的示例类似,cameras参数是传感器列表。在这种情况下,使用与设备节点关联的摄像头:
/dev/video2/dev/video5/dev/video8
cameras=[2, 5, 8]
模型
第二个参数 models 使您能够定义要在管道中运行的预训练模型。
models=[
PeopleNet.DLA1,
DashCamNet.DLA0,
# PeopleNet.GPU
],
在这里,您将从 NGC 部署两个经过预训练的模型:
- PeopleNet :一种能够识别人、脸和包的物体检测模型。
- DashCamNet :能够识别四类对象的模型:汽车、人、路标和自行车。
有关更多信息,请参阅 NGC 中的 model cards 。
硬件加速
模型使用 NVIDIA 深度学习加速器 ( DLA )实时运行。具体来说,可以在 DLA0 ( DLA Core 0 )上部署 PeopleNet ,在 DLA1 上部署 DashCamNet 。
在两个加速器之间分配模型有助于提高管道的总吞吐量。此外, DLA 甚至比 GPU 更节能。因此,在最高时钟设置的满载情况下,系统消耗的电量仅为~ 10W 。最后,在这种配置中, Jetson GPU 仍然可以使用 Jetson NX 上的 384 CUDA 内核自由加速更多任务。
下面的代码示例显示了当前支持的模型/加速器组合的列表。
pipeline = CameraPipelineDNN(
# ...
models=[
models.PeopleNet.DLA0,
models.PeopleNet.DLA1,
models.PeopleNet.GPU,
models.DashCamNet.DLA0,
models.DashCamNet.DLA1,
models.DashCamNet.GPU
]
# ...
)
保存视频
接下来的两个参数指定是否存储编码的视频,并定义用于存储的文件夹。
save_video=True,
save_video_folder="/home/nx/logs/videos",
显示视频
作为最后的初始化步骤,将管道配置为在屏幕上显示视频输出,以便进行调试。
display=True
主回路
最后,定义主循环。在运行期间,图像在pipeline.images下可用,检测结果在pipeline.detections下可用。
while pipeline.running():
arr = pipeline.images[0] # np.array with shape (1080, 1920, 3)
dets = pipeline.detections[0] # Detections from the DNNs
time.sleep(1/30)
下面的代码示例显示了结果检测。对于每次检测,您都会得到一个包含以下内容的字典:
- 对象类
- 以像素坐标定义为[左、宽、顶、高]的对象位置
- 检测置信度
>>> pipeline.detections[0]
[
# ...
{
"class": "person",
"position": [1092.72 93.68 248.01 106.38], # L-W-T-H
"confidence": 0.91
},
#...
]
用自定义逻辑扩展人工智能管道
作为最后一步,您可以使用 DNN 输出扩展主循环以构建自定义逻辑。具体来说,您可以使用摄像头的检测输出在机器人中实现基本的人员跟随逻辑。源代码可在 NVIDIA-AI-IOT/jetson-multicamera-pipelines GitHub repo 中找到。
- 要找到要跟踪的人,请解析管道。检测输出。此逻辑在 find_closest_human 函数中实现。
- 根据 dets2steer 中边界框的位置计算机器人的转向角。
- 如果人在左图中,最大限度地左转。
- 如果人在正确的形象中,尽量向右转。
- 如果人在中心图像中,则按边界框中心的 X 坐标成比例旋转。
生成的视频将保存到/home/nx/logs/videos,正如您在初始化过程中定义的那样。
解决方案概述
下面简要介绍一下在下面的示例中配置jetmulticam works. The package dynamically creates and launches a GStreamer pipeline with the number of cameras that your application requires. Figure 4 shows how the underlying GStreamer管道时的外观。如您所见,系统中所有关键操作(由绿色方框表示)都受益于硬件加速。
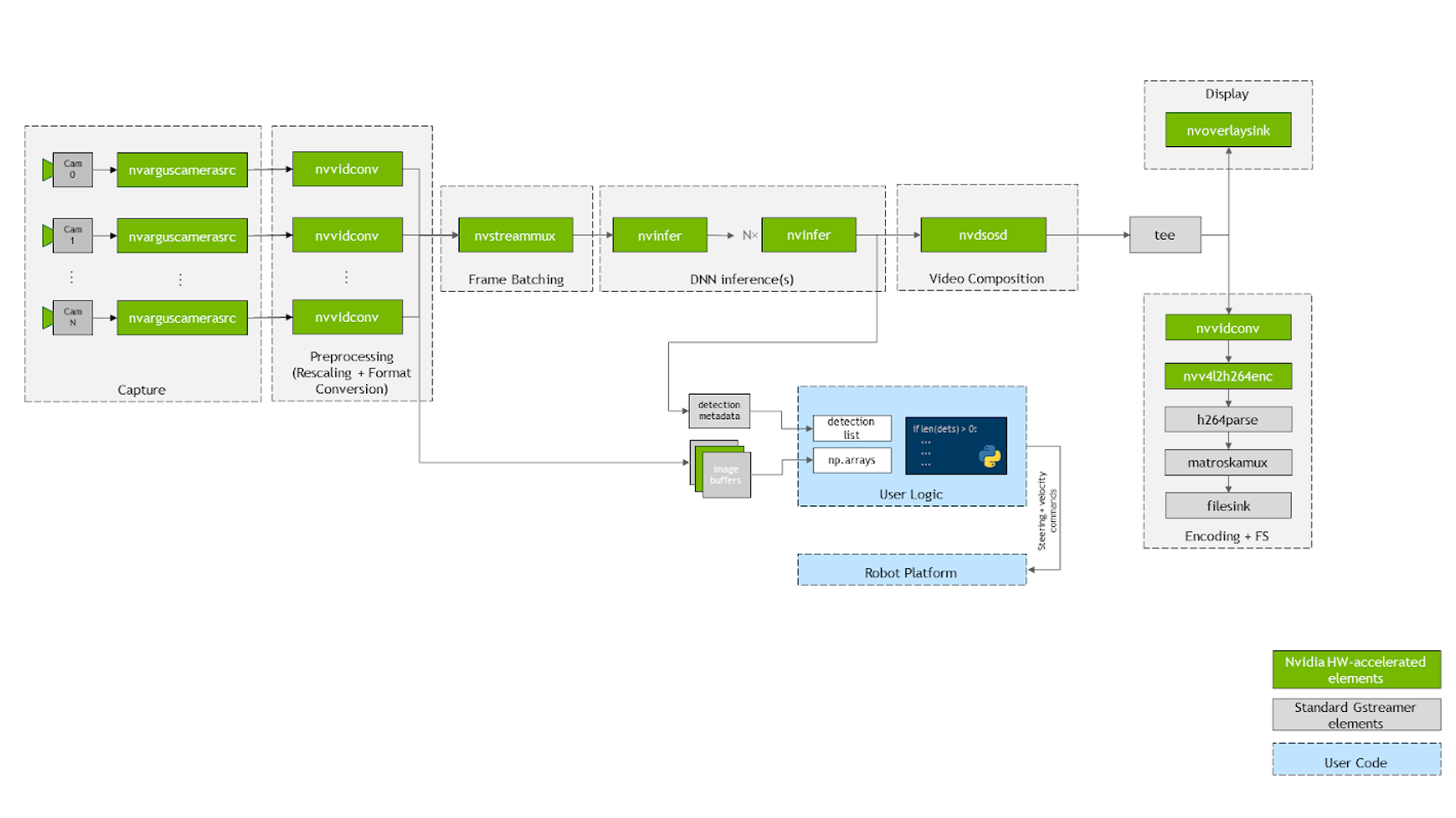
首先,使用多个摄像头nvarguscamerasrc在视频图上捕获。使用nvvidconv或nvvideoconvert重新缩放每个缓冲区并将其转换为 RGBA 格式。接下来,使用服务器提供的component对帧进行批处理 DeepStream SDK .默认情况下,批次大小等于系统中的摄像头数量。
要部署 DNN 模型,请利用 nvinfer 元素。在演示中,我在 Jetson Xavier NX 上提供的两种不同加速器 DLA core 1 和 DLA core 2 上部署了两种型号, PeopleNet 和 DashCamNet 。然而,如果需要的话,可以将更多的模型堆叠在彼此之上。
生成的边界框被nvosd元素覆盖后,使用nvoverlaysink将其显示在 HDMI 显示屏上,并使用硬件加速的 H264 编码器对视频流进行编码。保存到。 mkv 文件。
Python 代码中可用的图像(例如pipeline.images[0])通过回调函数或 probe 解析为numpy数组,并在每个视频转换器元素上注册。类似地,在最后一个nvinfer元素的 sinkpad 上注册了另一个回调函数,该元素将元数据解析为用户友好的检测列表。有关源代码或单个组件配置的更多信息,请参阅 create_pipeline 函数。
结论
NVIDIA Jetson 平台上的硬件加速与 NVIDIA SDKS 结合,可以实现卓越的实时性能。例如,下面的示例在三个摄像头流上实时运行两个对象检测神经网络,同时保持 CPU 利用率 低于 20% 。
本文展示的Jetmulticam包使您能够用 Python 构建自己的硬件加速管道,并在检测之上包含自定义逻辑。




