“事实太复杂了,除了近似,什么都不允许。 ” — 约翰·冯·诺依曼
计算的历史已经证明,用计算机硬件实现的相对简单的算法所能实现的是无限的。但计算机用有限大小的数字表示的“真相”基本上是近似的。正如大卫·戈德伯格所写,“ 将无限多个实数压缩成有限位数需要一个近似表示 。”浮点是实数最广泛使用的表示形式,在许多处理器中都有实现,包括 GPU 。它之所以受欢迎,是因为它能够代表一个大的动态范围的价值观,并权衡范围和精度。
不幸的是,浮点的灵活性和范围可能会在某些应用程序中造成麻烦,因为在固定范围内的精度更为重要:想想美元和美分。二进制浮点数不能准确地代表每一个十进制值,它们的近似值和舍入可能会导致累积错误,例如,在会计计算中可能是不可接受的。此外,添加非常大和非常小的浮点数可能会导致截断错误。由于这些原因,许多货币和会计计算都是使用定点十进制算法实现的,该算法存储固定数量的小数位数。根据所需的范围,定点算法可能需要更多的位。
NVIDIA GPU 不在硬件中实现定点算法,但 GPU 加速的软件实现可能是高效的。事实上, RAPIDS cuDF 库已经提供了高效的 32 位和 64 位定点十进制数和计算。但是 RAPIDS cuDF 和 GPU 加速的 Apache Spark 的一些用户需要 128 位小数提供的更高范围和精度,现在 NVIDIA CUDA 11.5 提供了对 128 位整数类型(int128)的预览支持,这是实现 128 位十进制算法所需的。
在本文中,在介绍 CUDA 新的 int128 支持后,我们将详细介绍如何在其上实现十进制定点算法。然后,我们将演示 RAPIDS cuDF 中的 128 位定点支持如何使关键的 Apache Spark 工作负载完全在 GPU 上运行。
介绍 CUDA __int128
在 NVIDIA CUDA 11.5 中, NVCC 离线编译器在主机编译器支持的平台上为有符号和无符号__int128数据类型添加了预览支持。nvrtc JIT 编译器还增加了对 128 位整数的支持,但需要一个命令行选项--device-int128来启用这种支持。算术、逻辑和位运算都支持 128 位整数。请注意, DWARF 调试对 128 位整数的支持目前还不可用,并将在后续的 CUDA 版本中提供。在 11.6 版本中, cuda gdb 和 Nsight Visual Studio Code Edition 增加了对检查这种新变量类型的支持。
NVIDIA GPU 以 32 位的数量计算整数,因此 128 位整数用四个 32 位无符号整数表示。加法、减法和乘法算法非常简单,使用内置的 PTX addc / madc 指令处理多个精度值。除法和余数使用简单的 O ( n ^ 2 )除法算法实现,类似于 Brent 和 Zimmermann 的书 现代计算机算法 中的算法 1.6 ,并进行了一些优化,以改进商选择步骤并最小化校正步骤。 128 位整数的一个令人振奋的用例是使用它们实现十进制定点算法。的 21.12 版本中包含 128 位十进制定点支持 RAPIDS libcudf .继续阅读,了解更多关于定点算法的信息,以及__int128如何用于实现高精度计算。
不动点算法
定点数字通过存储小数部分的固定位数来表示实数。定点数字也可用于“省略”整数值的低阶数字(即,如果你想表示 1000 的倍数,你可以使用一个 10 进制的定点数字,其刻度等于 3 )。记住定点和浮点之间区别的一个简单方法是,对于定点数字,小数点是固定的,而在浮点数字中,小数点可以浮动(移动)。
定点数字背后的基本思想是,即使所表示的值可以有小数位数(也就是 1.23 中的 0.23 ),实际上也可以将值存储为整数。例如,为了表示 1.23 ,可以用scale = -2和值 123 构造一个fixed_point数字。通过将数值乘以小数位数,可以将这种表示转换为浮点数。在我们的例子中, 1.23 是通过 123 (值)乘以 0.001 ( 10 (基数)乘以 -2 (刻度)的幂)得到的。当构造一个定点数时,会出现相反的情况,您可以“移位”该值,以便将其存储为整数(如果使用的是小数点 -2 ( 0.001 ( 10 (基数)与 -2 (小数点)的幂之比),则浮点数为 1.23 时,您将除以 0.001 )。
请注意,定点表示不是唯一的,因为可以选择多个比例。对于 1.23 的示例,可以使用小于 -2 的任何比例,例如 -3 或 -4 。唯一的区别是存储在磁盘上的数字不同; 123 表示刻度 -2 , 1230 表示刻度 -3 , 12300 表示刻度 -4 。当您知道您的用例只需要一组小数位时,您应该使用 least precise (又名最大)刻度来最大化可表示值的范围。使用 -2 刻度时,范围约为 -2000 万至+ 2000 万(小数点后两位),而使用 -3 刻度时,范围约为 -2 万至+ 200 万(小数点后三位)。如果你知道你是在为钱建模,而且不需要小数点后三位,那么 scale-2 是一个更好的选择。
定点类型的另一个参数是 base 。在本文的例子中,以及在 RAPIDS cuDF 中,我们使用 10 进制,或十进制定点。十进制定点是最容易考虑的,因为我们对十进制(以 10 为基数)数字很熟悉。定点数的另一个常用基数是基数 2 ,也称为二进制定点。这仅仅意味着,不是将数值按 10 的幂移动,而是将数值按 2 的幂移动。您可以在后面的“示例”部分中看到一些二进制和十进制定点值的示例。
定点与浮点
| Fixed Point | Floating Point |
| Narrower, static range | Wider, dynamic range |
| Exact representation avoids certain truncation and rounding errors | Truncation errors can occur |
| Keeps relative error constant | Approximate representation leads to certain truncation and rounding errors |
| Keeps relative error constant |
绝对误差是实际值与其计算机表示(以定点或浮点表示)之间的差值。相对误差是绝对误差与代表值之比。
为了演示定点可以解决的浮点表示问题,让我们看看浮点是如何表示的。浮点数不能完全代表所有值。例如,与值 1.1 最接近的 32 位浮点数为 1.10000002384185791016 ( 看浮子。让我们想象一下 )。在执行算术运算时,尾随的“不精确”可能会导致错误。例如, 1.1 + 1.1 的收益率为 2.2000000476837158231 。

相比之下,使用定点表示时,使用整数存储 exact 值。为了使用比例等于 -1 的定点数字表示 1.1 ,存储值 11 。算术运算是在基础整数上执行的,因此将 1.1 + 1.1 作为定点数相加,只需将 11 + 11 相加,就可以得到 22 ,正好代表值 2.2
为什么定点运算很重要?
如前一个例子所示,定点算法避免了浮点数固有的精度和舍入误差,同时还提供了表示小数的能力。通过保持相对误差恒定,浮点提供了更大的值范围。然而,这意味着,当添加非常大和非常小的数字时,它可能会出现较大的绝对(截断)错误,并会遇到舍入错误。固定点表示法总是有相同的 absolute 错误,代价是能够表示缩小的值范围。如果您知道小数点/二进制点后需要特定精度,则定点允许您在不截断这些数字的情况下保持其精度,即使值增长到范围的极限。如果你需要更多的范围,你必须添加更多的位。因此,小数 128 对一些用户来说变得很重要。
| Lower Bound | Upper Bound | |
| decimal32 | -21474836.48 | 21474836.47 |
| decimal64 | -92233720368547758.08 | 92233720368547758.07 |
| decimal128 | -1701411834604692317 316873037158841057.28 |
1701411834604692317316 873037158841057.27 |
fixed_point编号有许多应用程序和用例。您可以找到使用fixed_point数字 on Wikipedia 的实际应用程序列表
fixed_point in RAPIDS libcudf
概述
RAPIDS lib cuDF ` fixed _ point `类型的核心是一个简单的类模板。
template <typename Rep, Radix Rad>
class fixed_point { Rep _value; scale_type _scale;
}
fixed_point类的模板是:
Rep:表示fixed_point数字(例如,使用的整数类型)Rad:数字的Radix(例如,基数 2 或基数 10 )
decimal32和decimal64类型分别使用int32_t和int64_t作为 Rep ,并且都有Radix::BASE_10.。scale是一个强类型的运行时变量(请参见下面的运行时刻度和强类型小节等)。
fixed_point类型有几个构造函数(请参见下面的“构造方法”小节)、可转换为整型和浮点型的显式转换运算符,以及完整的运算符(加法、减法等)。
规模的迹象
在大多数 C ++定点实现(包括 RAPIDS LIbcUDF )中, negative scale 指示小数位数。 positive scale 表示可表示的倍数(例如,如果scale = 2表示decimal32,则可以表示 100 的倍数)。
auto const number_with_pos_scale = decimal32{1.2345, scale_type{-2}}; // 1.23
auto const number_with_neg_scale = decimal32{12345, scale_type{2}}; // 12300
建设者
libcudf中提供了以下(简化的)构造函数:
fixed_point(T const& value, scale_type const& scale) fixed_point(scaled_integer<Rep> s) // already "shifted" value fixed_point(T const& value) // scale = 0 fixed_point() // scale = 0, value = 0
其中,Rep是有符号整数类型,T可以是整数类型或浮点数。
设计与动机
libcudf 的fixed_point类型有许多设计目标。这些措施包括:
- 需要运行时量表
- 与潜在标准 C ++固定点类型的一致性
- 强类型
下面详细介绍了这些设计动机。
运行时规模和第三方定点库
在设计阶段,我们研究了八个现有定点 C ++库。不使用第三方库的主要原因是,所有现有的定点类型/库都是以scale作为编译时参数设计的。这不适用于 RAPIDS libcudf,因为它需要 scale 作为运行时参数。
虽然 RAPIDS libcudf 是一个 C ++库,可以在 C ++应用程序中使用,它也是后端 RAPIDS cuDF ,这是一个 Python 库。 Python 是一种解释(而非编译,如 C ++)语言。此外, cuDF 必须能够从其他数据源读取或接收定点数据。这意味着我们不知道编译时定点值的scale。因此,我们需要在fixed_point RAPIDS 中输入fixed_point类型,该类型具有运行时刻度参数。
我们引用的主要库是 CNL ,John McFarlane的组成数字库,目前是[VZX97 ]向C++标准中添加定点类型的参考。我们的目标是使 RAPIDS libcudf fixed_point类型尽可能与潜在的标准化类型相似。下面是 RAPIDS libcudf和CNL之间的一个简单比较。
CNL ( Godbolt Link )
using namespace cnl;
auto x = fixed_point<int32_t, -2, 10>{1.23};
RAPIDS libcudf
using namespace numeric;
auto x = fixed_point<int32_t, Radix::BASE_10>{1.23, scale_type{-2}};
或者:
using namespace numeric;
auto x = decimal32{1.23, scale_type{-2}};
这里需要注意的最重要的区别是,在 CNL 示例中,-2作为模板(又称编译时参数),而在 cuDF lib cuDF 示例中,scale_type{-2}作为运行时参数。
强类型
fixed_point类型的设计中融入了强类型。这方面的两个例子是:
- 将 scoped enumeration 与
direct-list-initialization对于刻度盘类型 - 对
Radix使用作用域枚举而不是整数类型
RAPIDS lib cuDF 坚持强类型最佳实践和强类型API,因为强类型提供了保护和表达能力。与强大的打字相比,我不会进入较弱的兔子洞,但是如果你想了解更多关于它的信息,那么有很多很棒的资源,包括Jonathon Bocarra的VC++上的流畅的C++帖子。
添加对decimal128的支持
RAPIDS libcudf 21.12 将 CUDA 添加为受支持的fixed_point类型。这需要进行一些更改,第一个是添加依赖于decimal128 11.5 提供的__int128类型的decimal128类型别名。
using decimal32 = fixed_point<int32_t, Radix::BASE_10>; using decimal64 = fixed_point<int64_t, Radix::BASE_10>; using decimal128 = fixed_point<__int128_t, Radix::BASE_10>;
这需要进行一些内部更改,包括更新类型特征函数__int128_t对某些函数的专门化,以及添加支持,以便cudf::column_view和朋友使用decimal128。以下简单示例演示了 lib cuDF API 与decimal128的配合使用(注意,所有这些示例对decimal32和decimal64的作用相同)。
例子
简单货币
一个简单的货币示例使用libcudf提供的decimal32类型,其刻度为 -2 ,正好代表 17.29 美元:
auto const money = decimal32{17.29, scale_type{-2}};
大数和小数之和
当求大值和小值之和时,定点非常有用。作为一个简单的玩具示例,下面的代码将指数 -2 到 9 的 10 的幂相加。
template <typename T>
auto sum_powers_of_10() { auto iota = std::views::iota(-2, 10); return std::transform_reduce( iota.begin(), iota.end(), T{}, std::plus{}, [](auto e) -> T { return std::pow(10, e); });
}
比较 32 位浮点和十进制定点可以得出以下结果:
sum_powers_of_10<float>(); // 1111111168.000000 sum_powers_of_10<decimal_type>(); // 1111111111.11
其中decimal_type是 32 位的 10 进制定点类型。使用 Godbolt here 上的 CNL 库可以看到一个例子。
避免浮点舍入问题
下面是一段代码(见 Godbolt 中),举例说明浮点值遇到问题(在 C ++中):
std::cout << std::roundf(256.49999) << ' '; // prints 257
RAPIDS lib cuDF 中的等效代码不会有相同的问题(请参见 Github 上的内容):
auto col = // decimal32 column with scale -5 and value 256.49999 auto result = cudf::round(input); // result is 256
256.4999 的值不能用 32 位二进制浮点表示,因此在调用 std :: roundf 函数之前,将其舍入到 256.5 。使用定点表示法可以避免这个问题,因为 256.4999 可以用任何具有五个或五个以上精度分数值的 10 进制(十进制)类型来表示。
二进制与十进制定点
// Decimal Fixed Point
using decimal32 = fixed_point<int32_t, Radix::BASE_10>;
auto const a = decimal32{17.29, scale_type{-2}}; // 17.29
auto const b = decimal32{4.2, scale_type{ 0}}; // 4
auto const c = decimal32{1729, scale_type{ 2}}; // 1700 // Binary Fixed Point
using binary32 = fixed_point<int32_t, Radix::BASE_2>;
auto const x = binary{17.29, scale_type{-2}}; // 17.25
auto const y = binary{4.2, scale_type{ 0}}; // 4
auto const z = binary{1729, scale_type{ 2}}; // 1728
小数 128
// Multiplying two decimal128 numbers
auto const x = decimal128{1.1, scale_type{-1});
auto const y = decimal128{2.2, scale_type{-1}};
auto const z = x * y; // 2.42 with scale equal to -2 // Adding two decimal128 numbers
auto const x = decimal128{1.1, scale_type{-1});
auto const y = decimal128{2.2, scale_type{-1}};
auto const z = x * y; // 3.3 with scale equal to -1
DecimalType和 RAPIDS Spark
Apache Spark SQL 中的 DecimalType 是一种可以表示 Java BigDecimal 值的数据类型。对财务数据进行操作的 SQL 查询大量使用十进制类型。与定点十进制数的 RAPIDS lib cuDF 实现不同, Spark 中的 DecimalType 可能的最大精度限制为 38 位。小数点后的位数也被限制在 38 。这个定义是 C ++刻度的否定。例如,像 0.12345 这样的十进制值在 Spark 中的刻度为 5 ,但在 libcudf 中的刻度为 -5 。
Spark 严格遵循 Apache Hive 操作精度计算规范,并为用户提供配置十进制操作精度损失的选项。 Spark SQL 在执行聚合、窗口、强制转换等操作时积极提高结果列的精度。这种行为本身就是使小数 128 与现实世界的查询极其相关的原因,它回答了一个问题:“为什么我们需要支持高精度的小数列?”。考虑下面的例子,特别是哈希骨灰,它有一个乘法表达式,涉及一个十进制 64 列,价格,和一个非十进制列,数量。 Spark 首先将非十进制列强制转换为适当的十进制列。然后确定结果精度,该精度大于输入精度。因此,即使涉及小数 64 个输入,结果精度也是小数 128 的情况也很常见。
scala> val queryDfGpu = readPar.agg(sum('price*'quantity))
queryDfGpu1: org.apache.spark.sql.DataFrame = [sum((price * quantity)): decimal(32,2)] scala> queryDfGpu.explain
== Physical Plan ==
*(2) HashAggregate(keys=[], functions=[sum(CheckOverflow((promote_precision(cast(price#19 as decimal(12,2))) * promote_precision(cast(cast(quantity#20 as decimal(10,0)) as decimal(12,2)))), DecimalType(22,2), true))])
+- Exchange SinglePartition, true, [id=#429] +- *(1) HashAggregate(keys=[], functions=[partial_sum(CheckOverflow((promote_precision(cast(price#19 as decimal(12,2))) * promote_precision(cast(cast(quantity#20 as decimal(10,0)) as decimal(12,2)))), DecimalType(22,2), true))]) +- *(1) ColumnarToRow +- FileScan parquet [price#19,quantity#20] Batched: true,DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/dec_walmart.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<price:decimal(11,2),quantity:int>
随着在 lib cuDF 中引入了新的小数 128 数据类型, Spark 的 RAPIDS 插件能够利用更高的精度,并将计算保持在 GPU 上,而之前需要返回到 CPU 上。
作为一个例子,让我们来看一个在以下模式下运行的简单查询。
{ id : IntegerType // Unique ID prodName : StringType // Product name will be used to aggregate / partition price : DecimalType(11,2) // Decimal64 quantity : IntegerType // Quantity of product }
此查询计算 totalCost 上的无界窗口,即总和(价格*数量)。然后,它会在排序后由 prodName 对结果进行分组,并返回最小总成本。
// Run window operation
val byProdName = Window.partitionBy('prodName)
val queryDfGpu = readPar.withColumn( "totalCost", sum('price*'quantity) over byProdName).sort( "prodName").groupBy( "prodName").min( "totalCost")
RAPIDS Spark 插件设置为仅当所有表达式都可以在 GPU 上计算时,才在 GPU 上运行运算符。让我们先看看下面这个查询的物理计划,不支持小数 128 。)
如果不支持十进制 128 ,每个运算符都会返回 CPU ,因为无法支持包含十进制 128 类型的子表达式。因此,包含 exec 或父表达式的表达式也不会在 GPU 上执行,以避免低效的行到列和列到行转换。
== Physical Plan == *(3) HashAggregate(keys=[prodName#18], functions=[min(totalCost#66)]) +- *(3) HashAggregate(keys=[prodName#18], functions=[partial_min(totalCost#66)]) +- *(3) Project [prodName#18, totalCost#66] +- Window [sum(_w0#67) windowspecdefinition(prodName#18, specifiedwindowframe(RowFrame, unboundedpreceding$(), unboundedfollowing$())) AS totalCost#66], [prodName#18] +- *(2) Sort [prodName#18 ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(prodName#18, 1), true, [id=#169] +- *(1) Project [prodName#18, CheckOverflow((promote_precision(cast(price#19 as decimal(12,2))) * promote_precision(cast(cast(quantity#20 as decimal(10,0)) as decimal(12,2)))), DecimalType(22,2), true) AS _w0#67] +- *(1) ColumnarToRow +- FileScan parquet [prodName#18,price#19,quantity#20] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/dec_walmart.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<prodName:string,price:decimal(11,2),quantity:int>
启用小数 128 支持后的查询计划显示,所有操作现在都可以在 GPU 上运行。由于没有 ColumnarToRow 和 RowToColumnar 转换(在查询中显示为 collect 操作),因此通过在 GPU 上运行整个查询,可以获得更好的性能。
== Physical Plan == GpuColumnarToRow false +- GpuHashAggregate(keys=[prodName#18], functions=[gpumin(totalCost#31)]), filters=ArrayBuffer(None)) +- GpuHashAggregate(keys=[prodName#18], functions=[partial_gpumin(totalCost#31)]), filters=ArrayBuffer(None)) +- GpuProject [prodName#18, totalCost#31] +- GpuWindow [prodName#18, _w0#32, gpusum(_w0#32, DecimalType(32,2)) gpuwindowspecdefinition(prodName#18, gpuspecifiedwindowframe(RowFrame, gpuspecialframeboundary(unboundedpreceding$()), gpuspecialframeboundary(unboundedfollowing$()))) AS totalCost#31], [prodName#18] +- GpuCoalesceBatches batchedbykey(prodName#18 ASC NULLS FIRST) +- GpuSort [prodName#18 ASC NULLS FIRST], false, com.nvidia.spark.rapids.OutOfCoreSort$@3204b591 +- GpuShuffleCoalesce 2147483647 +- GpuColumnarExchange gpuhashpartitioning(prodName#18, 1), true, [id=#57] +- GpuProject [prodName#18, gpucheckoverflow((gpupromoteprecision(cast(price#19 as decimal(12,2))) * gpupromoteprecision(cast(cast(quantity#20 as decimal(10,0)) as decimal(12,2)))), DecimalType(22,2), true) AS _w0#32] +- GpuFileGpuScan parquet [prodName#18,price#19,quantity#20] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/dec_walmart.parquet], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<prodName:string,price:decimal(11,2),quantity:int>
对于乘法运算,数量列转换为小数 64 (精度= 10 ),价格列(已为小数 64 类型)转换为精度 12 ,使两列的类型相同。结果列的大小调整为精度 22 ,这是小数 128 类型,因为精度大于 18 。这显示在上面计划的 GpuProject 节点中。
对 sum ()的窗口操作也将精度进一步提升到 32 。
我们使用 NVIDIA 决策支持( NDS )来衡量加速比, NDS 是 Spark 客户和提供商经常使用的 TPC-DS 数据科学基准的一种改编。 NDS 包含与行业标准基准相同的 100 多个 SQL 查询,但修改了数据集生成和执行脚本的部分。 NDS 的结果与 TPC-DS 不可比。
NDS 查询子集的初步运行表明,由于支持小数 128 ,性能显著提高,如下图所示。它们在八个节点组成的集群上运行,每个节点有一个 A100 GPU 和 1024 CPU 内核,在 Spark 3.1.1 上运行 16 个内核的执行器。每个执行器在内存中使用 240GiB 。这些查询显示了接近 8 倍的出色加速,这可以归因于以前的操作回到了现在在 GPU 上运行的 CPU ,从而避免了行到列和列到行的转换以及其他相关的开销。所有 NDS 查询的端到端运行时间平均提高了 2 倍。这(希望)只是一个开始!
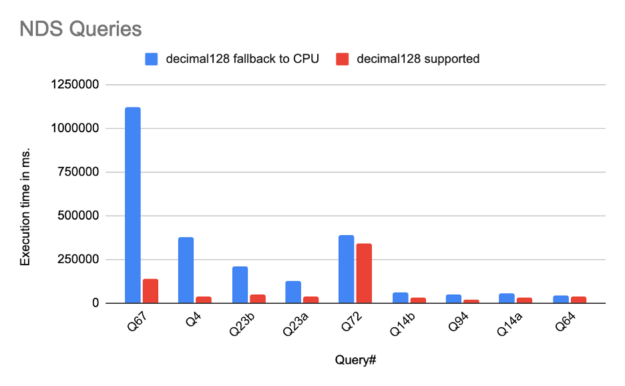
随着 Spark Spark 插件的 21.12 版本发布,大多数操作员都可以使用十进制 128 支持。需要对溢出条件进行一些特殊处理,以保持 CPU 和 GPU 之间的结果兼容性。这项工作的最终目标是通过 RAPIDS for Spark 插件,让零售和金融查询充分受益于 GPU 的加速。
总结
RAPIDS libcudf 中的固定点类型、 DecimalType 的添加以及 Spark 的 RAPIDS 插件的 decimal128 支持,使得以前只有在 CPU 上才可能在 GPU 上运行的激动人心的用例成为可能。如果您想开始使用 RAPIDS lib cuDF 或 Spark 的 RAPIDS 插件,可以点击以下链接: