在每一次会议、电话交流、 多人场合或支持语音的应用中,技术始终面临一个核心难题:谁在何时发言?几十年来,若不依赖专用设备或离线批量处理,几乎无法实现在实时转录中准确回答这一问题。
NVIDIA Streaming Sortformer 是一种开放的生产级转录模型,突破了语音转录的技术边界。该模型专为逼真的多说话人场景设计,具备低延迟特性,并与 NVIDIA NeMo 和 NVIDIA Riva 无缝集成。您可将其应用于语音转录流程、实时语音机器人编排,或企业级会议内容分析。
主要功能
NVIDIA Streaming Sortformer 具备以下关键功能,使其成为各类实时应用中强大且灵活的解决方案。
- 带有标签的帧级语音分离(例如 spk_0、spk_1)。
- 每个话语标记的精确时间戳。
- 支持2–4个以上音箱追踪,性能强大且延迟最低。
- 高效 GPU 推理,全面支持 NeMo 与 Riva 工作流。
- 该模型虽针对英语进行了优化,但已在普通话会议数据以及包含4个说话人的非英语CALLHOME数据集上成功测试,表现出较低的DER,表明其在多种语言环境下均具有出色性能。
基准测试结果
以下是 Streaming Sortformer 在说话人日志错误率(Diarization Error Rate, DER)上的表现,数值越低表示效果越好。

示例用例
Streaming Sortformer 为各种实时多说话人场景提供了实用的解决方案,包括:
- 会议与生产力:实时带发言人标记的会议记录及次日摘要。
- 联络中心:为质量保证或合规性需求提供独立的客服或客户流程。
- 语音机器人与AI助手:实现更自然的对话、准确的发言轮转与身份追踪。
- 媒体与广播:用于编辑和审核的自动化标签。
- 企业与合规:通过可审计且经过说话人识别的日志,满足监管要求。
请观看以下演示。
架构和内部结构
Streaming Sortformer 是一种说话者识别模型,能够根据说话者在录音中首次出现的时间对其进行排序。该模型在后台充当编码器:首先通过卷积预编码模块对原始音频进行处理和压缩,随后将压缩后的特征输入一系列 Conformer 和 Transformer 模块。这些模块协同工作,分析对话上下文,最终实现对说话者的排序。
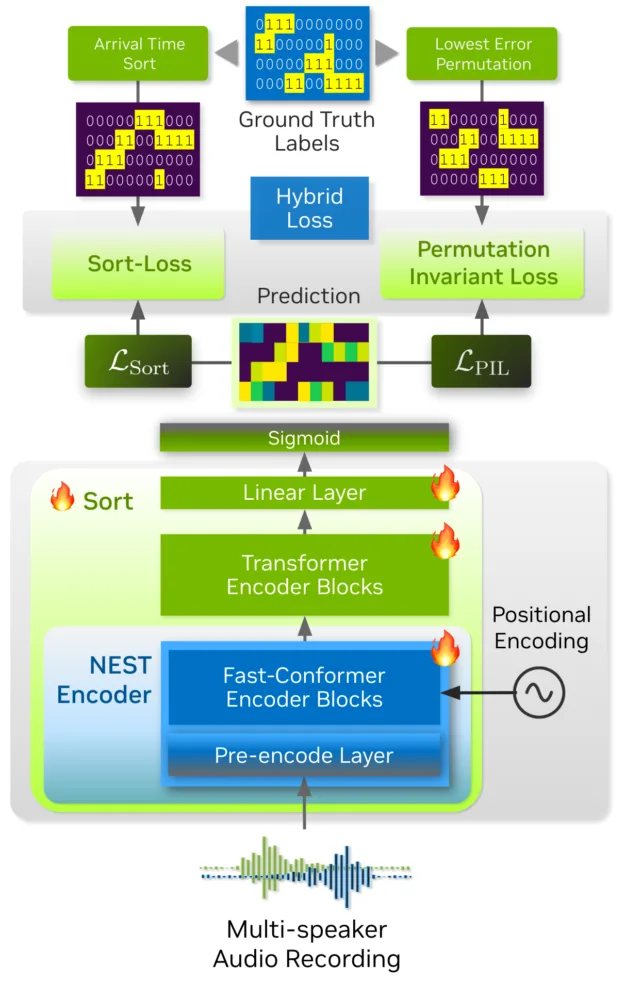
为处理实时音频,Streaming Sortformer 会将音频流分割成小片段,并采用重叠处理的方式。模型引入了一种名为“到达顺序说话者缓存”(Arrival-Order Speaker Cache, AOSC)的智能内存缓冲机制,用于持续跟踪音频流中已检测到的所有说话者。借助 AOSC,模型能够将当前音频片段中的说话者与之前已识别的说话者进行比对,从而确保在整个音频流中对同一说话者始终保持一致的标签。最终,AOSC 缓冲机制使得实时多说话者追踪变得既实用又准确。



图5。Streaming Sortformer 的三扬声器示例,展示按到达时间顺序排列的扬声器缓存。

图6。Streaming Sortformer 的四扬声器示例,展示按到达时间顺序排列的扬声器缓存。
负责任的人工智能、局限性及后续步骤
以下是需要牢记的边界与最佳实践:
- 专为最多四位对话者设计。若扬声器数量超过四个,性能将下降,因为该模型目前无法生成四个以上的输出。
- 针对英语进行了优化,也可适用于其他语言,例如普通话。
- 为获得特定领域或语言的最佳性能,建议进行微调。
- 实际测试验证了系统对重叠信号的抵抗能力,但在极快速的切换或严重串扰的情况下,仍可能影响准确性。
- 路线图包括: – 扩展至更多类型的扬声器; – 提升在多种语言以及复杂声学环境下的性能; – 与 Riva 及 NeMo 代理/语音机器人工作流实现全面集成。
结论
借助 Streaming Sortformer,开发者和组织机构不仅能够在研究中,还能在各类生产环境中,为支持语音的多扬声器应用提供开放、实时的对话转录解决方案。
准备好构建了吗?
- 在 Hugging Face 上下载、部署或测试 Streaming Sortformer,查看其支持矩阵。
- 试用由 NVIDIA AI Enterprise 提供支持的 NVIDIA Riva NIM,体验语音识别(ASR)、文本转语音(TTS)和翻译功能。
- 如需咨询或进行故障排除,请访问 NeMo GitHub、Riva 教程或 Riva 开发者论坛。
如需深入了解 Streaming Sortformer 的技术细节与背景,欢迎查阅我们发表在 arXiv 上的最新研究成果Offline Sortformer。