近年来, transformers 已成为一种强大的深度神经网络体系结构,已被证明在许多应用领域,如 自然语言处理 ( NLP )和 computer vision ,都超过了最先进的水平。
这篇文章揭示了在微调变压器时,如何以最快的训练时间获得最大的精度。我们展示了 RAPIDS Machine Learning 库中的 cuML 支持向量机( SVM )算法如何显著加快这一过程。 GPU 上的 CuML SVM 比基于 CPU 的实现快 500 倍。 这种方法使用支持向量机磁头,而不是传统的 多层感知器( MLP )头 ,因此可以精确轻松地进行微调。
什么是微调?为什么需要微调?
transformer 是一个 deep learning 模型,由许多多头、自我关注和前馈完全连接的层组成。它主要用于序列到序列任务,包括 NLP 任务,如机器翻译和问答,以及计算机视觉任务,如目标检测等。
从头开始训练 transformer 是一个计算密集型过程,通常需要几天甚至几周的时间。在实践中,微调是将预训练的变压器应用于新任务的最有效方法,从而减少培训时间。
用于微调变压器的 MLP 磁头
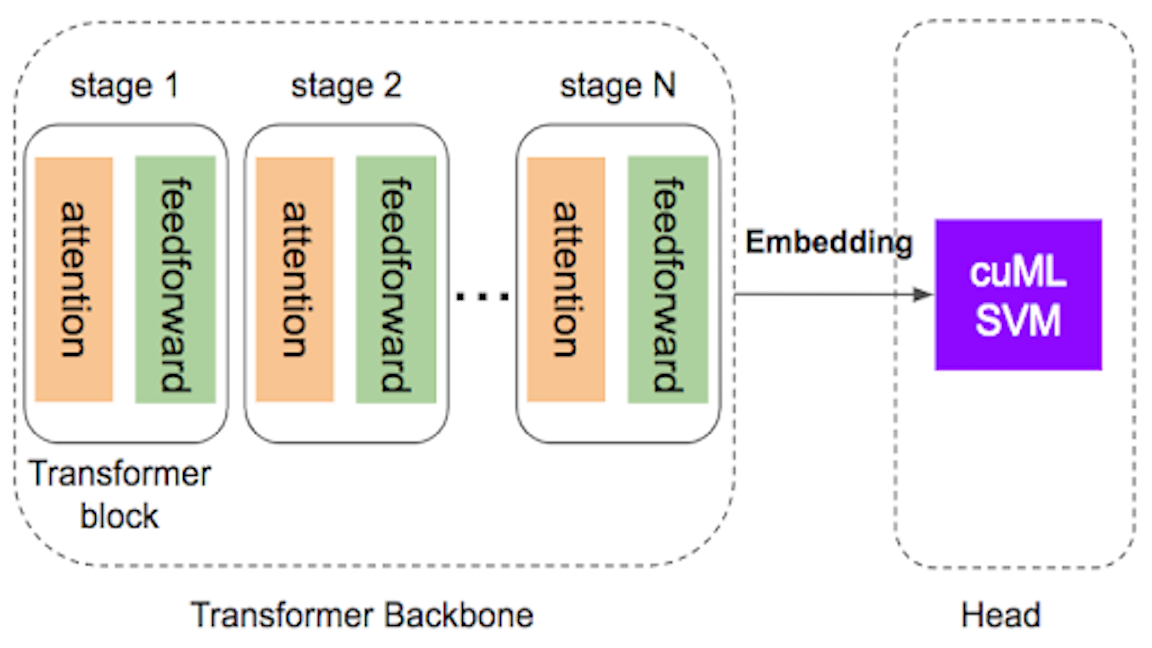
如图 1 所示,变压器有两个不同的组件:
- 主干,包含多个自我注意块和前馈层。
- 头部,对分类或回归任务进行最终预测。
在微调过程中, transformer 的主干网络被冻结,而只有轻型头部模块接受新任务的培训。 head 模块最常见的选择是 multi-layer perceptron ( MLP ),用于分类和回归任务。
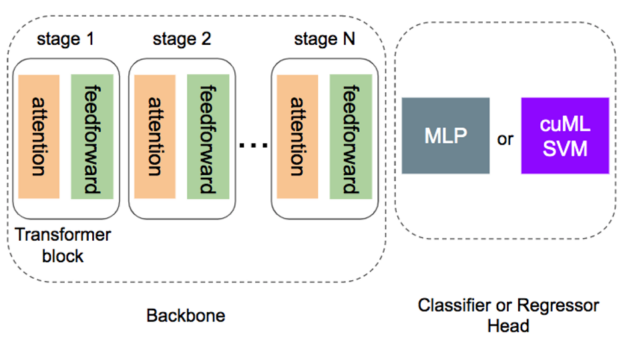
事实证明,实现和调整 MLP 可能比看起来要困难得多。为什么?
- 有多个超参数需要调整: 层数、辍率、学习率、正则化、优化器类型等。选择要调整的超参数取决于您试图解决的问题。例如,辍 和 batchnorm 等标准技术可能会导致 回归问题的性能退化 。
- 必须采取更多措施防止过度安装。 变压器的输出通常是一个长的嵌入向量,长度从数百到数千不等。当训练数据大小不够大时,过度拟合很常见。
- 执行时间方面的性能通常不会得到优化。 用户必须为数据处理和培训编写样板代码。批量生成和从 CPU 到 GPU 的数据移动也可能成为性能瓶颈。
SVM 磁头用于变压器微调的优势
支持向量机 (支持向量机)是最受欢迎的监督学习方法之一,当存在有意义的预测性特征时,支持向量机是最有效的。由于 SVM 对过度拟合的鲁棒性,对于高维数据尤其如此。
然而,出于以下几个原因,数据科学家有时不愿尝试支持向量机:
- 它需要手工特征工程,这可能很难实现。
- 传统上,支持向量机速度较慢。
RAPIDS cuML 通过提供 在 GPU 上的加速比高达 500 倍 重新唤起了人们对重温这一经典模型的兴趣。有了 RAPIDS cuML ,支持向量机在数据科学界再次流行起来。
例如, RAPIDS cuML SVM 笔记本电脑已在多个 Kaggle 比赛中频繁使用:
由于 transformers 已经学会了以长嵌入向量的形式提取有意义的表示, cuML SVM 是头部分类器或回归器的理想候选。
与 MLP 头相比, cuML SVM 具有以下优势:
- 容易调整。 在实践中,我们发现在大多数情况下,仅调整一个参数 C 就足以支持 SVM。
- 速度 。在 GPU 上处理之前, cuML 将所有数据一次性移动到 GPU 。
- 多样化 。支持向量机的预测与 MLP 预测在统计上不同,这使得它在集合中非常有用。
- Simple API. cuML SVM API 提供 scikit-learn 风格的拟合和预测功能。
案例研究: PetFinder 。我的掌门人竞赛
提出的带有 SVM 磁头的微调方法适用于 NLP 和 计算机视觉任务 。为了证明这一点,我们研究了 宠物搜寻者。我的掌门人竞赛 ,这是一个 Kaggle 数据科学竞赛,它根据宠物的照片预测了它们的受欢迎程度。
该项目使用的数据集由 10000 张手动标记的图像组成,每个图像都有一个我们想要预测的目标 pawpularity 。当 pawpularity 值在 0 到 100 之间时,我们使用回归来解决这个问题。
由于只有 10000 个标记图像,因此训练深层神经网络以从零开始获得高精度是不切实际的。相反,我们通过使用预训练的 swin transformer 主干,然后用标记的 pet 图像对其进行微调来实现这一点。
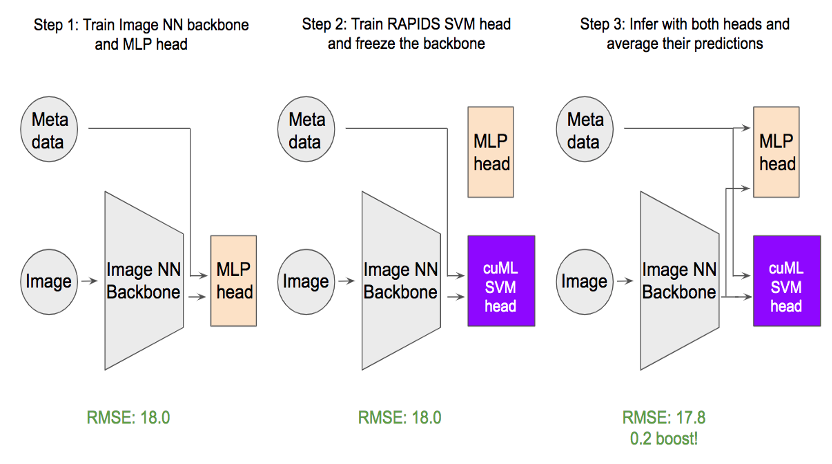
如图 2 所示,我们的方法需要三个步骤:
- 首先,将使用 MLP 的回归头添加到主干 swin 变压器,并对主干和回归头进行微调。一个有趣的发现是,二进制交叉熵损失优于常见的均方误差损失( MSE ) 由于目标的分布 。
- 接下来,主干被冻结, MLP 头被替换为 cuML SVM 头。然后用常规的 MSE 损失对 SVM 头进行训练。
- 为了获得最佳预测精度,我们对 MLP 头和 SVM 头进行了平均。求值度量根意味着平方误差从 18 优化到 17.8 ,这对该数据集非常重要。
值得注意的是,第 1 步和第 3 步是可选的,在这里实施的目的是优化模型在本次比赛中的得分。仅步骤 2 是微调最常见的场景。因此,我们在步骤 2 测量了运行时间,并比较了三个选项: cuML SVM ( GPU )、 sklearn SVM ( CPU )和 PyTorchMLP ( GPU )。结果如图 3 所示。
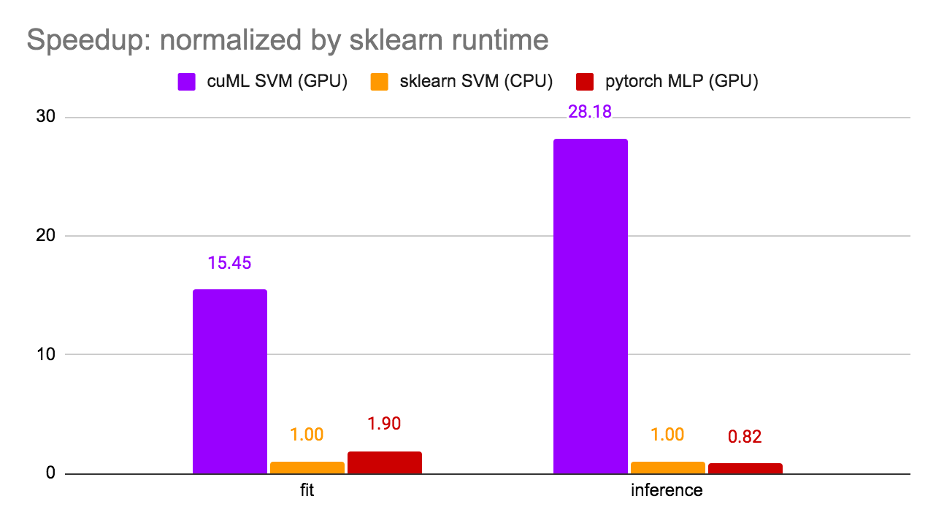
使用 sklearn SVM 对运行时间进行归一化, cuML SVM 实现了 15 倍的训练加速比和 28.18 倍的推理加速比。值得注意的是,由于 GPU 利用率高, cuML SVM 比 PyTorch MLP 更快。 笔记本可以在 Kaggle 上找到。
Transformer 微调的关键要点
Transformer 是革命性的深度学习模式,但培训它们很耗时。 GPU 上变压器的快速微调可以通过提供显著的加速而使许多应用受益。 RAPIDS cuML SVM 也可以作为经典 MLP 头的替代品,因为它速度更快、精度更高。
GPU 加速为 SVM 等经典 ML 模型注入了新的能量。使用 RAPIDS ,可以将两个世界中最好的结合起来:经典的机器学习( ML )模型和尖端的深度学习( DL )模型。在里面 RAPIDS cuML ,你会发现更多闪电般快速且易于使用的型号。
后记
在撰写和编辑本文时, PetFinder.my 掌门人竞赛 得出结论。 NVIDIA KGMON Gilberto Titericz 通过使用 RAPIDS 支持向量机获得第一名。他成功的解决方案是集中变压器和其他深层 CNN 的嵌入,并使用 RAPIDS SVM 作为回归头。有关更多信息,请参阅他的 获奖方案总结 。




