虽然语音 AI 用于构建数字助理和语音智能体,但其影响远远超出这些应用。文本转语音 (TTS) 和自动语音识别 (ASR) 等核心技术正在推动各行各业的创新。他们正在实现实时翻译,为交互式数字人提供支持,甚至帮助那些失声的人恢复语音。随着这些功能的成熟,它们正在从根本上重塑人们的沟通、学习和联系方式。
NVIDIA Riva 是一套多语种微服务,用于构建实时语音 AI 工作流。Riva 可在 TTS、ASR 和神经网络机器翻译 (NMT) 中提供出色的准确性,并适用于本地、云、边缘和嵌入式设备。
TTS 也称为语音合成,可将文本转换为高质量、自然的语音。几十年来,它一直是语音 AI 领域一项具有挑战性的任务。本文将介绍三个最先进的 Riva TTS 模型 ( NVIDIA 的最新 TTS 模型) ,它们对此任务做出了重大贡献:
- Magpie TTS Multilingual 可以显著提高语音自然度和发音准确性。
- Magpie TTS Zeroshot 支持从短短几秒钟的语音样本中进行语音克隆。
- Magpie TTS Flow 非常适合工作室配音和播客解说。
| 模型 | 架构 | 用例 | 支持的语言 | 技术细节 |
| Magpie TTS 多语种 | 串流编码器 – 解码器 Transformer | – 语音 AI 智能体 – 数字人 – 多语种交互式语音应答 (IVR) – 有声读物 | 英语、西班牙语、法语、德语 | – 使用 NVIDIA Dynamo-Triton 降低延迟:约 200 毫秒 – 使用偏好对齐框架和无分类器引导 (CFG) 优化文本依从性 |
| Magpie TTS Zeroshot | 串流编码器 – 解码器 Transformer | – 实时电话 – 游戏中的非玩家角色 (NPC) | 英语 | – 使用 NVIDIA Dynamo-Triton 降低延迟:大约 200 毫秒 – 使用偏好对齐框架和无分类器引导 (CFG) 优化文本依从性 – 5 秒语音样本用于语音克隆 |
| Magpie TTS Flow | 离线流匹配解码器 | – 工作室配音 – 播客旁白 | 英语 | – 模型文本语音对齐和语音特征描述,用于语音克隆的 3 秒语音样本 |
流编码器 – 解码器转换器
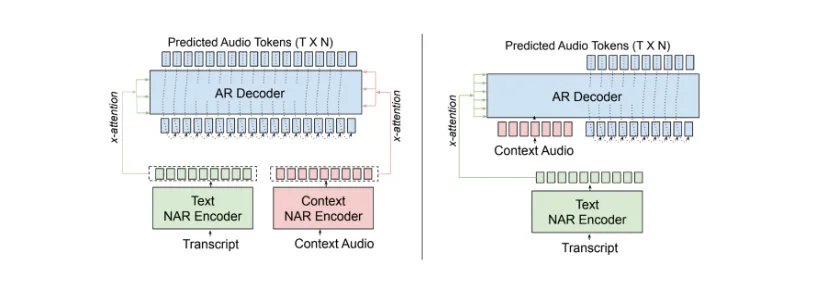
Magpie TTS Multilingual 和 Magpie TTS Zeroshot 模型基于编码器 – 解码器 Transformer 架构构建,面向串流应用。编码器是一个非自回归 (NAR) Transformer,解码器是一个交叉参与编码器的自回归 (AR) Transformer。模型输入包括标记化文本和上下文音频:来自目标说话者参考音频的声学代码。模型的输出是目标说话者生成的声学令牌。这两种模型基于编码器 – 解码器架构的不同变体而构建:
- Magpie TTS Multilingual:使用多编码器设置。专用的上下文编码器可处理上下文音频令牌。上下文和文本编码器输出被输入到 AR 解码器的不同层中。这允许明确分离模态。
- Magpie TTS Zeroshot:采用解码器上下文设置,利用解码器的自注意力机制进行扬声器调节。它会将上下文音频令牌输入到 AR 解码器中,然后由其处理上下文和目标音频令牌。此方法使用共享表征进行条件反射和预测。
这两种模型都使用新的偏好对齐框架和无分类器引导 (CFG) 来解决持续存在的问题。这些问题包括 AI 生成、解释或输出虚假或误导性音频,或产生不需要的发声,尤其是在输入文本包含重复标记时。
- 偏好对齐:该框架为具有挑战性的文本和上下文音频提示生成多个输出,然后在奖励系统中使用 ASR 和扬声器验证 (SV) 模型评估关键指标,以创建偏好数据集。它应用直接偏好优化 (DPO) 来指导 TTS 模型生成更理想的输出。
- CFG:在推理过程中,模型为每个合成生成两个语音输出:一个基于输入文本和上下文音频,另一个无这些条件。最终输出是一种远离无条件结果的组合,提高了对输入的依从性和整体音频质量。
与其他开源模型相比,这些 NVIDIA 模型提供了最低的字符错误率 (CER) 和字错误率 (WER) ,尽管训练时使用的数据要少得多。在人工评估中,它们在自然程度 (MOS) 和说话者相似性 (SMOS) 方面也获得了最高分。
您可以在预训练的 TTS 模型文档中找到模型当前支持的语音名称和情绪。由于严格的人体评估标准,目前支持女性声音的情绪范围比男性声音更广泛。这是因为只有当至少 50% 的评估者在音频样本中始终识别出情绪时,情绪才会被释放。因此,一些情绪更快地达到了女性声音的这一值,这反映了评估结果的差异,而不是技术限制。
您可以使用 Magpie TTS Zeroshot 中的 5 秒音频样本,合成同意使用此类功能的目标演讲者的声音。您还可以使用图 2 所示的组件创建自己的工作流。

此工作流的输入包含两个部分:用户提示和目标发言者的音频提示。由 NVIDIA LLM NIM 托管的 LLM 根据用户提示为 TTS 任务生成随机文本。Magpie TTS Zeroshot 模型将文本和音频提示作为输入,然后用目标说话者的声音生成输入文本的相应音频。
Magpie TTS Flow
Magpie TTS Flow 模型引入了一种对齐感知预训练框架,该框架将离散语音单元 (HuBERT) 集成到 NAR 训练框架 (E2 TTS) 中,以学习文本语音对齐。E2 TTS 采用流匹配解码器来联合建模文本语音对齐和声学特征,实现自然的音期输出。E2 TTS 的一个关键局限性是它依赖于大型转录数据集,而这些数据集对于低资源语言通常很少。
为了解决这一数据限制,Magpie TTS Flow 使用未转录的语音数据将对齐学习直接集成到预训练过程中,而无需单独的对齐机制。通过将对齐学习嵌入到预训练中,它促进了无对齐的语音转换,并允许在微调过程中实现更快的收,即使在有限的转录数据下也是如此。
如图 3 所示,在预训练之前,HubERT 会将音频波形转换为离散单元。在预训练期间,离散语音单元序列与掩码语音连接,从而使模型能够学习单元语音对齐。在微调阶段,转录数据和掩码目标参考语音的文本序列被连接,然后作为输入传递给模型,以生成目标说话者的音频。

HuBERT 模型将来自未转录数据的语音波形作为输入,然后生成 50 Hz 离散单元序列,这是一个从 0 到 K-1 的索引序列,其中 K 是 k-means 量化器中的集群数。然后,系统会删除连续语音片段的重复索引,以消除持续时间信息,从而使其能够灵活地为目标扬声器执行语音克隆,并进行各种对齐。
在预训练期间,删除重复数据的单元可用于指导隐藏语音的修补,并帮助模型学习提取说话人特定的声音特征。用填充标记 F 填充离散单元 u,以匹配梅尔频谱图 x 的长度。已填充的序列 uPAD 与掩码语音 xmask 连接,作为模型的输入,以预测掩码区域。经过训练的流匹配解码器可基于修改后的 CFM 损失,使用周围环境对掩码区域进行修补。解码器的隐藏大小为 1024,包含 16 个注意力头和总共 24 个 Transformer 层,产生了 4.5 亿个参数。
对于微调,单元序列将替换为来自转录数据的文本嵌入。将文本序列 (用填充令牌填充) 和掩码目标参考语音连接起来,输入到模型以生成目标说话者的音频。
与其他模型相比,Magpie TTS Flow 可以实现高发音准确性 (更低的 WER) 和更高的说话者相似性 ( SECS-O) ,并且预训练和微调迭代次数显著减少。此外,它还可以通过添加语言 ID 作为解码器的输入来有效学习多种语言的文本语音对齐,使其成为强大的多语种 TTS 系统。虽然以上链接的论文展示了使用不到 1000 小时配对数据的强劲性能,以凸显基于单元的预训练方法的效率,但已发布的 Riva 模型使用更大的配对数据集 (约 7 万个小时) 进行训练,以进一步提高零样本性能。
您可以使用 Magpie TTS Flow 中的 5 秒音频样本,合成同意使用此类功能的目标演讲者的声音 (图 4) 。此工作流的输入包含三个部分:用户提示、目标说话人的音频提示和音频提示转录。由 NVIDIA LLM NIM 托管的 LLM 根据用户提示为 TTS 任务生成随机文本。Magpie TTS Flow 接受输入,然后用目标说话者的声音生成输入文本的相应音频。

安全协作
作为 NVIDIA 可信 AI 计划的一部分,安全、负责任地推进语音 AI 成为优先事项。为了应对合成语音的风险,NVIDIA 与领先的深度伪造和语音检测公司 (如 Pindrop) 合作,提供对 Riva Magpie TTS Zeroshot 等模型的抢先体验。
从银行和金融服务到大型联络中心、零售、公用事业和保险,Pindrop 技术深受各行各业的信赖,可提供实时语音身份验证和深度伪造检测,以防止关键交互中的欺诈和模仿。我们在深度假检测方面的合作为安全的合成语音部署设定了重要标准,并解决了呼叫中心和媒体完整性等领域的关键风险,确保了负责任的 AI 发展。
开始使用 NVIDIA Riva Magpie TTS 模型
NVIDIA Riva Magpie TTS 模型为实时、自然和自适应语音合成设定了新标准。Riva Magpie TTS 模型具有多语种功能、零样本语音特征和高级偏好调整功能,可生成富有表现力、准确且高度自然的音频,以适应扬声器和内容。
凭借灵活的架构和强大的性能,Riva Magpie TTS 可为医疗健康、可访问性以及任何需要逼真实时语音交互的应用提供理想的模型。
要开始使用 Riva Magpie TTS 模型,请执行以下操作:
- 试用NVIDIA NIM微服务
- 按照 Riva 快速入门指南 – 语音合成从 NVIDIA NGC 下载 Docker 容器
- 请求访问 Magpie TTS Zeroshot 和 Magpie TTS Flow 这两种零样本模型
- 了解如何借助 NVIDIA AI Enterprise 在整个组织中安全、大规模地运行这些功能