
量子电路模拟 是设计量子就绪算法的最佳方法,因此您可以在强大的量子计算机可用时立即利用它们。
NVIDIA cuQuantum 是一个 SDK ,它使您能够利用不同的方式来执行量子电路模拟。 cuStateVec ,一个为状态向量量子模拟器构建的高性能库,依赖于在 GPU 存储器中保存量子状态向量。它的内存需求按 O ( 2 ^ N )进行缩放, N 表示量子位的数量。当你开始扩展到超过 40 个量子位时,这可能会非常昂贵。
为了减轻使用状态向量方法的量子电路模拟的存储器需求的指数缩放,可以使用张量网络作为替代方案。你可以通过用增加的计算换取减少的空间来模拟更大的量子电路。
cuTensorNet 使您可以利用 NVIDIA GPU 上的张量网络方法,与其他替代方案相比,提供了更高的可扩展性和更好的性能。尽管最近在加速张量收缩路径发现方面取得了进展,但随着电路尺寸在深度或宽度上的增加,精确张量网络收缩的成本仍然会变得难以控制。
一种系统地保持张量网络模拟所需资源可控制的策略是使用近似算法。本文详细介绍了 cuTensorNet v2.0.0 中支持近似张量网络模拟的新功能。
cuTensorNet 的进一步尺度近似张量网络模拟
从 2.0.0 版开始, cuTensorNet 库提供单个 GPU 计算原语,以加速近似张量网络模拟。由于感兴趣的量子问题在大小和复杂度上都会有很大的差异,研究人员开发了高度定制的近似张量网络算法,以解决各种可能性。
为了实现与这些框架和库的轻松集成, cuTensorNet 提供了一组 API 来涵盖以下常见用例:
- 张量 QR
- 张量 SVD
- 闸门拆分
这些原语使您能够加速和缩放不同类型的量子电路模拟器。利用这些方法模拟量子计算机的一种常见方法是矩阵积态( MPS ),也称为 tensor train 。
分解
矩阵的 QR 分解可以通过将张量的多个维度合并为行维度,将其余维度合并为列维度,从而推广到高维张量。生成的 Q 和 R 矩阵可以进一步展开为张量,从而将输入张量有效地拆分为两个操作数。
张量 QR
我们介绍了 cutensornet TensorQR ,这是一个 API ,主要用于移动近似张量网络中的正交中心,包括 MPS 、投影纠缠对状态( PEPS )等。
对于基准测试,我们使用 NVIDIA A100 80GB GPU 上的 QR ,检查了分解第 3 级 MPS 张量的性能,形状(D, 2, D),其中 D 表示 MPS 的键尺寸。对于 cuTensorNet 和基于 D 的等效( CPU )实现,分解的执行时间作为 D 的函数进行测量,以进行比较。所有 CPU 性能结果均使用相同的 EPYC 7742 CPU 完成,使用所有芯。
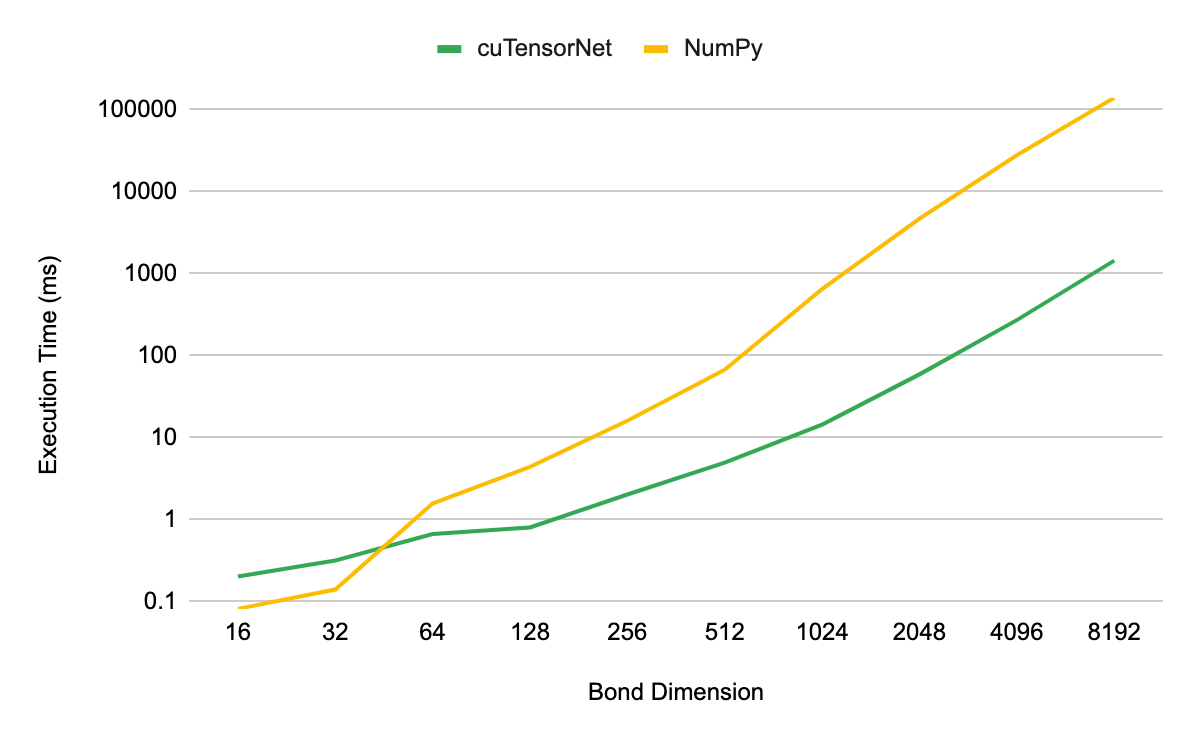
图 1 显示,当使用大于 32 的键维度时, cuTensorNet 比基于 CPU 的 NumPy 实现产生了数量级的加速。在 8192 的键维度上,您可以看到 CPU 实现的加速高达 96 倍。
张量 SVD
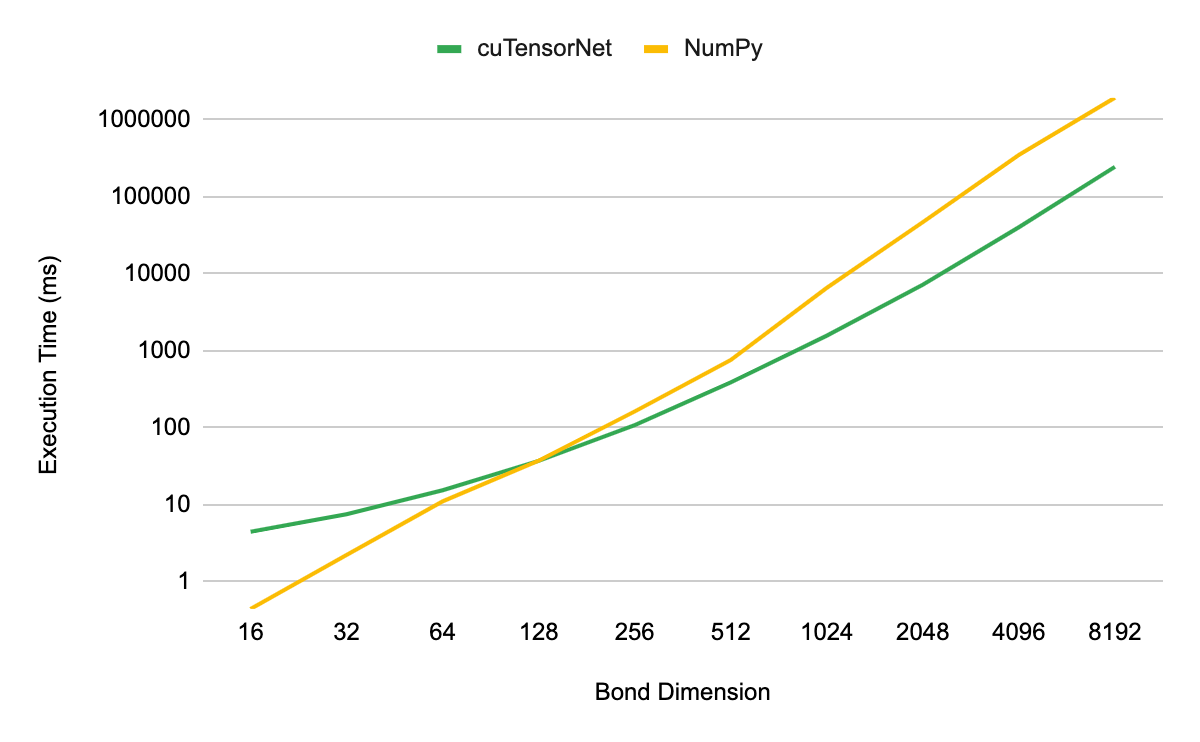
张量 SVD 的定义和用途与前面描述的张量 QR 相似。分解得到的奇异值包含有关量子系统的重要信息。例如,量子态的奇异值与基础量子电路的冯·诺依曼纠缠熵直接相关。对于弱到中等纠缠的量子系统,可以截断奇异值的尾部,以降低计算成本,同时保持模拟的高精度。
张量 SVD 性能的测量方法与张量 QR 相同。我们发现,当模拟维度大于 128 的键时, cuTensorNet 实现提供了性能优势。当放大到 8192 维时,我们看到了 7.5 倍的加速。
将量子电路转换为 MPS 表示
在量子电路模型中,当一个 2 量子比特的门操作数应用于一对连接的张量时,你可以执行一系列操作,将门吸收到两个连接的张量上,同时保持固定的拓扑结构。
这种类型的操作形成了构建量子电路的 MPS 或 PEPS 表示的基础。在执行张量 SVD 时,可以将截断作为过程的一部分,以保持计算成本可控制。例如,通过在所有 2 量子比特门上迭代使用该技术,可以实现量子电路的近似 MPS 模拟(图 3 )。
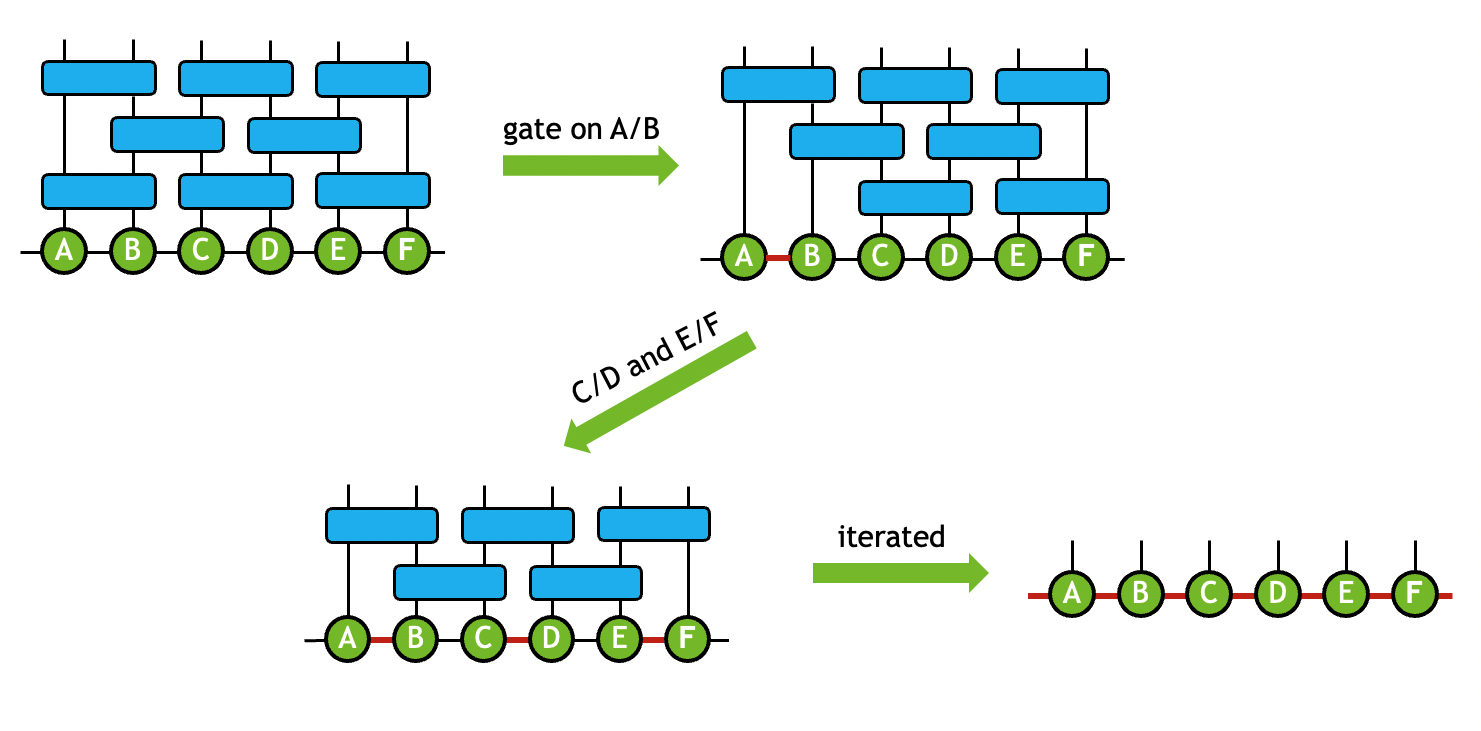
张量网络可以通过门分裂函数将 2 量子比特门吸收到连接的张量上来简化。通过迭代这个过程,生成 MPS ,然后可以收缩 MPS 以模拟量子电路。 这降低了网络连接的复杂性,是 MPS 量子电路仿真的价值基石。您可以利用截断张量 SVD 进一步降低网络大小和计算成本。在多次迭代这个过程之后,您将得到一个 MPS ,它可以收缩以模拟量子电路操作。
闸门分裂
使用 cuTensorNet 使用近似张量网络方法实现量子电路模拟所需的最后一个组件是 2.0.0 版中引入的 gate split 功能。该团队提供了一些示例,展示了如何在 cuQuantum GitHub repo 中最好地单独使用这些组件,此外还有一个 具体样本 ,它使用这些组件来实现 MPS 量子模拟。
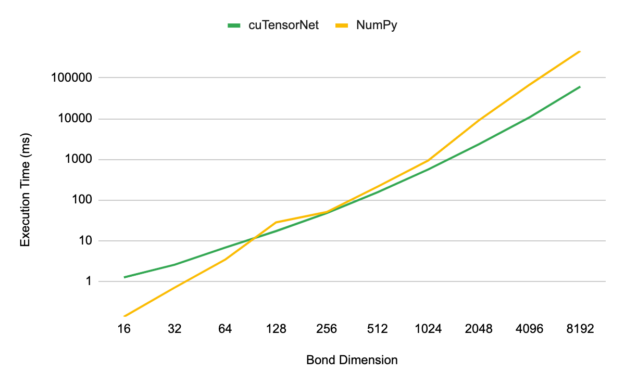
该函数的性能通过检查构建最终 MPS 的最后一个也是成本最高的步骤的执行时间作为结合维度的函数来测试。当超出 128 的键尺寸时,您可以开始看到利用 GPU 进行 MPS 模拟的优势。
在 8192 的键合维度下,与同一数据中心级别 CPU 上的标准 NumPy 实现相比, NVIDIA A100 80GB GPU 上的 cuTensorNet 的加速约为 7.8 倍。
开始使用 cuTensorNet 进行量子模拟
cuTensorNet v2.0.0 现已推出。您可以通过 conda-forge 、 pip 或 cuQuantum installers 访问它。要快速开始新功能,请参见 Approximation Setting: SVD Options 。有关详细指南,请参阅 code samples 。要请求功能或报告错误,请联系 GitHub 上的 NVIDIA/cuQuantum 。
有关详细信息,请参阅以下内容 量子计算资源:
- Introduction to Approximate Tensor Network Operations
- Best-in-class Quantum Circuit Simulation at Scale with NVIDIA cuQuantum
- NVIDIA cuQuantum and QODA Adoption Accelerates
- NVIDIA GTC ’23 Quantum Computing Sessions




