
NVIDIA 最近发布了 SIGGRAPH Asia 2023 的研究论文,SLANG.D:快速、模块化和可微分的着色器编程。这篇论文展示了一种语言如何作为一个统一的平台进行实时、反向和可微分的绘制。这项工作是麻省理工学院、加州大学圣地亚哥分校、华盛顿大学和 NVIDIA 研究人员的合作成果。
这是关于可微分俚语系列的一部分。有关 Slang 与各种机器学习( ML )渲染应用程序的实际示例的更多信息,请参阅 Differential Slang:应用实例。
Slang 是一种用于实时图形编程的开源语言,它为编写和维护大规模、高性能、跨平台的图形代码库带来了新的功能。Slang 使现代语言结构适应实时图形的高性能需求,并为 Direct 3D 12、Vulkan、OptiX、CUDA 和 CPU 生成代码。
虽然 Slang 最初是一个研究项目,但现在已经发展成为一个实用的解决方案,被用于 NVIDIA Omniverse 和 NVIDIA RTX Remix 渲染器,以及 NVIDIA Game Works Falcor 研究基础设施。
这项新研究开创了一种共同设计的方法。这种方法表明,如果将差异化作为一等公民纳入整个系统,那么可以很好地处理自动差异化的复杂性:
- 语言
- 类型系统
- 中间表示(IR)
- 优化过程
- 自动完成引擎
Slang 的自动差异化与 Slang 的模块化编程模型、GPU 图形管道、Python 和 PyTorch 无缝集成。Slang 支持区分任意控制流、用户定义类型、动态调度、泛型和全局内存访问。使用 Slang,可以使现有的实时渲染器变得可微分 并且可以在没有重大源代码更改的情况下学习。
连接计算机图形学和机器学习
数据驱动的渲染算法正在改变计算机图形,为shape,textures,volumetrics,materials和post-processing提高性能和图像质量的算法。与此同时,计算机视觉和 ML 研究人员越来越多地利用计算机图形学来改进三维重建通过反向渲染。
由于不同的工具、库、编程语言和编程模型,连接实时图形、ML 和计算机视觉开发环境具有挑战性。凭借最新研究,Slang 使您能够轻松完成以下任务:
- 将学习融入渲染。Slang 使图形开发人员能够使用基于梯度的优化,并以数据驱动的方式解决传统的图形问题,例如,使用基于外观的优化来学习 mipmap 层次结构。
- 从现有的图形代码中构建可微分的渲染器。 我们使用 Slang 将预先存在的实时路径跟踪器转换为可微分路径跟踪器,重用了 90% 的 Slang 代码。
- 将图形引入 ML 培训框架。Slang 从图形着色器代码生成自定义 PyTorch 插件。在这篇文章中,我们演示了如何在Nvdiffrec中生成自动区分的 CUDA 内核。
- 在渲染器中引入 ML 培训 Slang 可以帮助在实时渲染器中训练小型神经网络,例如神经辐射缓存。
可微分编程和机器学习需要梯度



图 1 显示了斯坦福兔子被放置在康奈尔大学的盒子里。左列显示渲染的场景。中间一列显示了关于兔子在 y 轴上的平移的参考导数。右栏显示了由 Slang 的 autodiff 功能计算的相同导数,它看起来与参考图像相同。
ML 方法的一个关键支柱是基于梯度的优化。具体来说,大多数 ML 算法由反向模式自动微分,是通过一系列计算传播导数的有效方法。这不仅适用于大型神经网络,也适用于许多需要使用梯度和梯度下降的更简单的数据驱动算法。
像 PyTorch 这样的框架公开了对张量(多维矩阵)的高级操作,这些张量带有手动编码的反向模式内核。当你组成张量运算来创建神经网络时,PyTorch 会通过链接这些内核来自动组成导数计算。其结果是一个易于使用的系统,您不必手动编写梯度流,这也是 ML 研究加快步伐的原因之一。
不幸的是,一些计算不容易被数组上的高级操作捕获,这给高效表达它们带来了困难。光栅化器或光线跟踪器等图形组件就是这种情况,其中发散的控制流和复杂的访问模式需要大量低效的主动掩模跟踪和其他解决方案。这些解决方案不仅难以写入和读取,而且还具有显著的性能和内存使用开销。
因此,大多数高性能可微分图形管道,例如 nvdiffrec,InstantNGP 和 Gaussian splatting,并非完全使用纯 Python 编写。相反,研究人员会选择更接近底层硬件的语言,如 CUDA、HLSL 或 GLSL,来编写高性能内核。
因为这些语言不提供自动区分,所以这些应用程序使用手工派生的渐变。手工微分是乏味的,容易出错,使其他人很难使用或修改这些算法。这就是 Slang 的用武之地,因为它可以自动为多个后端生成差异化着色器代码。
设计 Slang 的自动微分
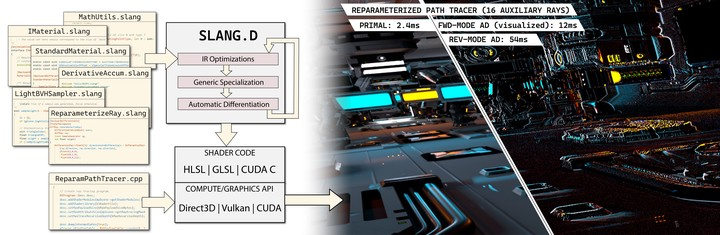
图 2 显示了 Zero Day 场景中的传播导数,该导数由 Falcor 框架 的可微分路径跟踪器构建,它是通过重用超过 5K 行的预先存在的着色器代码来实现的。
Slang 的起源可以追溯到 Spark 在 SIGGRAPH 2011 上展示的编程语言,以其当前的形式在 SIGGRAPH 2018 上展示。为 Slang 添加自动差异化需要多年的研究和多次语言设计迭代。语言和编译器的每一部分——包括解析器、类型系统、标准库、IR、优化过程和 Intellisense 引擎——都需要进行修改,以支持自动 diff 作为语言的一级成员。
Slang 的类型系统已经扩展,将可微性视为函数和类型的一种属性。这个类型系统允许在编译时进行检查,以防止在使用可微编程框架时出现常见错误,例如无意中通过调用不可微函数删除导数。我们在技术论文中描述了这些以及更多的挑战和解决方案,SLANG.D:快速、模块化和可微分着色器编程。
在 Slang 中,自动微分被表示为函数上的可组合算子。应用自动微分于一个函数会产生另一个函数,这个函数可以像任何其他函数一样被使用。这种功能设计实现了高阶差分,这在许多其他框架中是不存在的。能够在正向和反向模式的任何组合中多次区分函数的能力,大大简化了高级渲染算法的实现,例如翘曲区取样和Hessian 哈密顿 MLT。
Slang 的标准库也得到了扩展,以支持可微计算,并且大多数现有的 HLSL 内部函数都被视为可微函数,允许使用这些内部函数的现有代码在不进行修改的情况下自动进行区分。
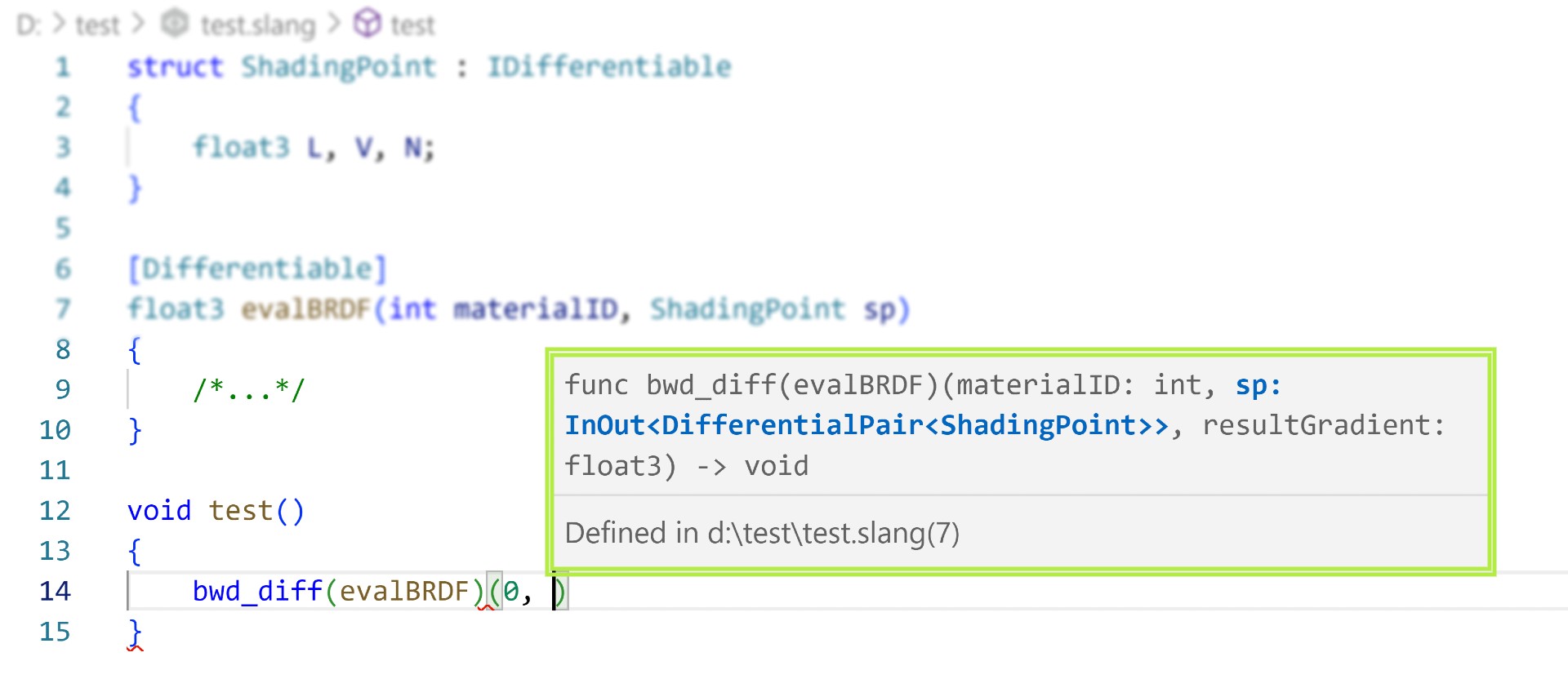
Slang 提供了一个完整的开发工具集,包括 Visual Studio 代码扩展,具有对可微分实体的全面提示和自动完成支持,这提高了我们内部项目的生产力。
可微编程生态系统中的实时图形
Slang 编译器可以发出以下语言的派生函数代码:
- HLSL:用于 Direct3D 管道。
- GLSL 或 SPIR-V:这两种都是用于 OpenGL 和 Vulkan 的。
- CUDA 或 OptiX:适用于独立应用程序、Python 或 PyTorch 等张量框架。
- 标量 C++:用于调试。
可以向多个目标发射相同的代码。例如,您可以使用 PyTorch 优化器训练高效的模型,然后将它们部署在 Vulkan 或 Direct3D 上运行的视频游戏或其他交互式体验中,而无需编写新的或不同的代码。用一种语言编写的单一表示对于长期代码维护和避免两个版本细微不同时出现的错误非常有益。
类似于 NVIDIA WARP 框架 对于可微分模拟,Slang 为不断增长的可微分编程生态系统做出了贡献。Slang 允许自动生成导数,并将其与较低级别和较高级别的编程环境一起使用。可以将 Slang 与手写的、经过大量优化的 CUDA 内核一起使用 库。
如果您更倾向于使用高级方法,并希望使用 Python 交互式笔记本进行研究和实验,您可以通过 slangpy 包(pip 安装 slangpy)在 Jupyter 笔记本等环境中使用。Slang 可以成为丰富的笔记本、Python、PyTorch 和 NumPy 生态系统的一部分,与各种格式的数据进行交互,使用小部件与数据交互,并通过绘图和数据分析库进行可视化,同时提供更适合某些应用程序的附加编程模型。
张量与着色语言
PyTorch 和其他基于张量的库,如 NumPy、TensorFlow 和 Jax,提供了与 Slang 以及通常的着色语言截然不同的编程模型。PyTorch 主要用于前馈神经网络,其中对每个元件的操作是相对一致的,而没有发散的控制流。NumPy 和 PyTorch n 维阵列(ndarray)模型对整个张量进行运算,使得指定水平约简(如轴上求和和和大矩阵乘法)变得微不足道。
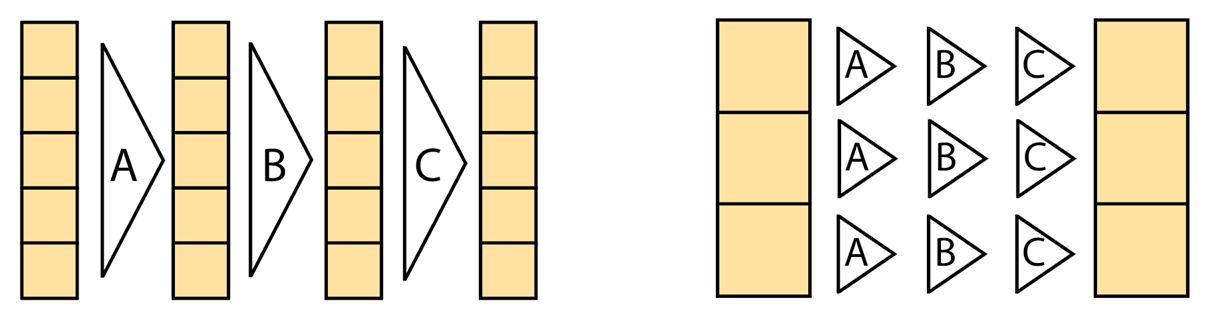
相比之下,着色语言占据了光谱的另一端,并暴露了单指令多线程(SIMT)模型,使您能够指定在单个元素或一小块元素上运行的程序。这使得表达复杂的控制流变得容易,其中每组元素执行一系列截然不同的操作,例如当路径跟踪器的光线撞击不同的表面并为其下一次反弹执行不同的逻辑时。
这两个模型共存,应该被视为互补的,因为它们实现了不同的目标:张量上的降和运算需要一行 ndarray 代码,但需要数百行代码和多个内核启动才能以 SIMT 风格高效表达。
相反,使用动态循环和停止条件,可以以 SIMT 风格优雅地编写可变步长的射线标记,但相同的射线标记将演变为复杂且不可维护的主动掩模跟踪 ndarray 代码。这样的代码不仅很难写和读,而且可能会执行得更糟,因为根据活动状态,每个分支都会针对每个元素执行,而不是只执行一个或另一个。
性能优势
PyTorch 和其他 ML 框架是为大型神经网络的训练和推理而构建的。他们使用经过大量优化的平台库来执行大型矩阵乘法和卷积运算。
虽然每个单独的操作都非常高效,但它们之间的中间数据被序列化到主内存并进行检查点操作。在训练过程中,前向和反向传播传球是连续和单独计算的。这使得 PyTorch 的开销对于实时图形中的微小神经网络和其他可微编程用途来说意义重大。
Slang 的自动微分功能使您能够控制梯度值的存储、累积和计算方式,从而实现显著的性能和内存优化。通过避免多次内核启动、过多的全局内存访问和不必要的同步,与使用标准 PyTorch 操作编写的相同小型网络和图形工作负载相比,它能够融合前向和后向传递以及高达 10 倍的训练加速。
这种加速不仅加快了 ML 模型的训练,而且使许多新的应用程序能够在图形工作负载中使用较小的内联神经网络。内联神经网络开辟了计算机图形学研究的一个全新领域,如神经辐射缓存、神经纹理压缩和神经外观模型。
放码过来!
有关 Slang 的开源存储库和 slangpy Python 包,请参阅 /shader-slang GitHub 仓库和 用俚语写 PyTorch 内核。自动区分语言功能记录在 俚语用户指南。我们还包括了几个 Slang 的可微教程,这些教程在介绍 Slang 面向对象的可微编程模型的同时,也介绍了 Slang 中常见图形组件的代码。
如果你想了解更多关于 Slang 和 PyTorch 的教程,可以使用 slangpy,请参阅以下资源:
想要查看更多示例,请访问 可微分俚语:应用实例。
结论
差分渲染是计算机图形学、计算机视觉和图像合成的强大工具。尽管研究人员多年来一直在提高其能力、构建系统并探索应用程序,但最终形成的系统很难与现有的大型代码库相结合。现在,对于 Slang,现有的实时渲染器可以变得可微分。
Slang 极大地简化了将着色器代码添加到 ML 管道,反之亦然,将学习组件添加到渲染管道。
实时渲染专家现在可以探索构建 ML 渲染组件,而无需重写 ML 框架中的渲染代码。Slang 促进了数据驱动的资产优化和改进,并有助于研究传统渲染中的新型神经组件。
另一方面,ML 研究人员现在可以利用现有的渲染器和具有复杂着色器的资源,并在新的架构中融入富有表现力的最先进的着色模型。
我们期待看到实时图形和机器学习如何为新的真实感神经和数据驱动技术做出贡献。有关 Slang 的自动区分功能的更多信息,请参阅 SLANG.D:快速、模块化和可微分着色器编程 的论文。



