将 ML 模型部署到生产环境的方法有很多。有时,模型每天运行一次,以更新数据库中的预测。有时,它为移动设备上的小型但关键的决策控制面板或语音转文本提供支持。如今,该模型也可以是自定义的大型语言模型 (LLM),支持新的 AI 驱动的产品体验。
通常情况下,模型通过带有微服务的 API 端点暴露在其环境中,从而能够实时查询模型。虽然这听起来很简单,但由于通常有大量用于构建和部署微服务的框架,因此在严格的生产环境中服务模型并非易事。
请考虑以下典型挑战(表 1)。
| 模型训练 | 您能否在没有人工干预的情况下持续训练和部署模型? | 您能否轻松开发新模型、在本地测试部署并自信地进行实验? | 您能否在开发和部署期间持续管理功能? |
| 模型部署 | 部署能否处理您想使用的各种类型的模型? | 模型能否快速生成响应,以支持所需的产品体验? | 如果响应不佳,会出现什么情况?您能否追踪血脉和生成血脉的模型? |
| 基础架构 | 部署是否高度可用,足以支持 SLA 目标? | 部署是否高效使用硬件资源? | 能否轻松监控请求和响应? |
| 部署是否与您现有的基础架构和策略集成? | 您能否以经济高效的方式部署模型? | 部署能否扩展到每秒足够的请求? | |
| 基础架构是否提供对敏感数据集和模型的安全访问? | 基础架构是否可以扩展以满足计算需求?不使用时,成本是否为零? | 用户能否调整性能旋钮(例如 GPU 卡的类型和数量)以降低 TCO? |
从原型设计到生产
为全面应对这些挑战,请考虑 ML 系统从开发的早期阶段到部署(及后续)的整个生命周期。
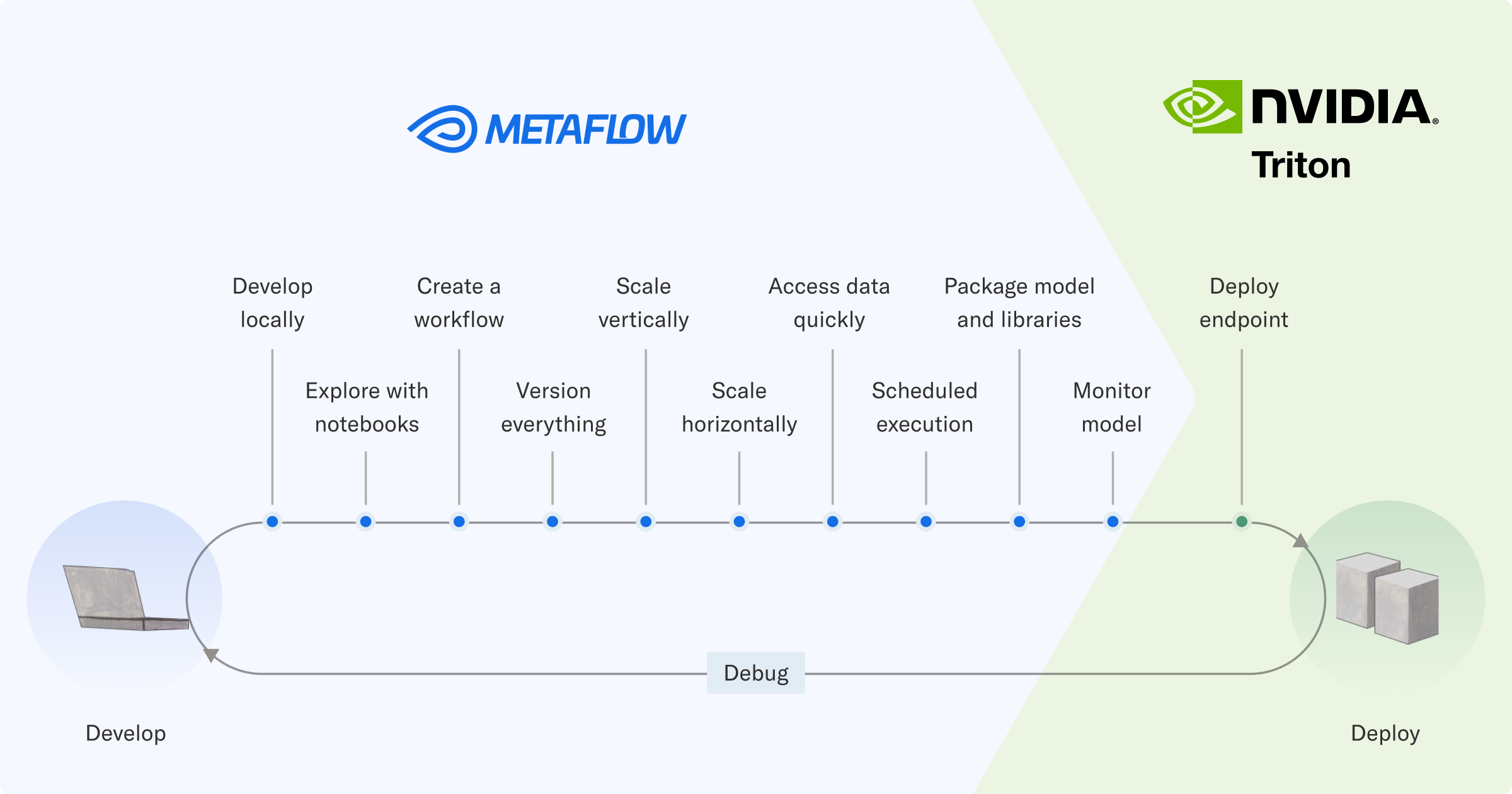
虽然您可以通过为每个步骤采用单独的工具来完成整个过程,但通过提供连接各个点的一致 API,可以实现更流畅的开发者体验和更快的部署速度。
出于这一愿景,Netflix 于 2017 年开始开发名为 Metaflow 的 Python 库,该库于 2019 年开源。自那时起,该库已被房地产、无人机、游戏和医疗健康等各行各业的数千家领先的 ML 和 AI 组织采用。
Metaflow 涵盖了第一个阶段的所有问题:如何开发生产级反应性 ML 工作流程、轻松访问数据和大规模训练模型,以及全面跟踪所有工作。
现在,您可以将 Metaflow 作为开源软件采用,也可以在您的云账户中部署 Metaflow。此外,Outerbounds 提供了一个完全托管的 ML 和 AI 平台,在开源软件包的基础上增加了额外的安全性、可扩展性和开发者生产力功能。
通过 Metaflow,您可以应对开发和生成模型相关的前三大挑战。而要部署用于实时推理的模型,则需要一个模型服务堆栈。这正是 NVIDIA Triton 推理服务器 发挥作用的地方。
NVIDIA Triton 推理服务器是 NVIDIA 开发的开源模型服务框架。它支持各种模型,可以在 CPU 和 GPU 上高效处理。
Outerbounds 和 NVIDIA 正在合作,使各种 ML 和 AI 用例更容易访问 NVIDIA 推理堆栈。这两个开源框架的结合使您能够快速开发机器学习和 AI 驱动的模型和系统,并将其部署为高性能、生产级服务。
在 NVIDIA Triton 推理服务器上部署
为支持企业级生产级 AI, NVIDIA Triton 推理服务器包含在 NVIDIA AI Enterprise 软件平台中,可提供企业级安全性、支持和稳定性。
虽然有许多模型服务框架可作为开源和托管服务使用,但 NVIDIA Triton 推理服务器因以下原因而脱颖而出:
- 它采用 C++实现,性能出色,并且能够高效使用 GPU.这使其成为对延迟和吞吐量敏感的应用程序的绝佳选择。
- 由于具有可插拔的后端,它用途广泛,能够处理许多不同的模型系列。
- 得益于 NVIDIA 的多年开发和大规模使用,它已经过测试和调优。
这些功能使 NVIDIA Triton 推理服务器成为功能非常强大的模型,可服务于工作流程向其推送经过训练的模型的堆栈。
Metaflow 可帮助您对模型及其周围的工作流进行原型设计,并对其进行大规模测试,同时跟踪所执行的所有工作。当工作流显示出足够的前景时,可以直接将其集成到周围的软件系统,并在生产中进行可靠的编排。
虽然 Metaflow 通过以开发者为中心的简单 Python API 提供了所有必要的功能,但它由大量基础设施提供支持。该堆栈与 Amazon S3 等数据存储集成,促进了 Kubernetes 上的大规模计算,并使用 Argo Workflows 等生产级工作流编排器。
成功训练模型后,责任转移到 NVIDIA Triton 推理服务器。与训练基础设施类似,推理方面需要一个惊人的非简单的基础设施堆栈。
模型服务基础设施
通过 HTTPS 实现一个简单的服务来公开简单的模型(例如逻辑回归模型)并不难。使用 FastAPI 等框架,可以在数百行 Python 中实现类似的基本版本。
然而,像这样的简易模型服务解决方案的性能并不特别出色。Python 是一种富有表现力的语言,但它在快速处理请求方面并不擅长。如果没有额外的基础设施,它就无法扩展:单个 FastAPI 进程每秒只能处理这么多请求。此外,如果您想将逻辑回归模型替换为更复杂的深度回归模型,该解决方案也不是通用型的。
您可以尝试逐步解决这些不足之处。但随着解决方案变得越来越复杂,错误、安全问题和其他故障的表面积也变得越来越复杂,这也是我们寻求更稳健解决方案的动力。
NVIDIA Triton 推理服务器通过将堆栈解构为以下关键组件来应对这些挑战。
- 前端 负责通过 HTTP 或 gRPC 接收请求并将其路由到后端。
- 一个或多个后端负责与特定模型系列交互的层。
NVIDIA Triton 推理服务器支持可插拔后端,这些后端适用于 ONNX、Python 原生模型、基于树的模型、LLM 和许多其他模型类型。这使得使用一个堆栈处理通用模型成为可能。
高性能前端(每秒可处理数万次请求)与针对特定模型类型优化的后端相结合,可提供从请求到响应的低延迟路径。借助 NVIDIA Triton 推理服务器,整个请求处理路径可以保留在原生代码中,从而相对于基于 Python 的模型服务解决方案降低请求延迟并提高吞吐量。
低级服务器优化对于利用自定义 LLM(大型语言模型)的应用非常重要,因为这些应用需要为具有低延迟推理的大型深度学习模型提供服务。为了进一步优化 LLM 推理,NVIDIA 推出了 TensorRT-LLM。TensorRT-LLM 是一个 SDK,它让 Python 开发者能够更轻松地构建生产级的 LLM 服务器。TensorRT-LLM 开箱即用,可作为 NVIDIA Triton 推理服务器的后端。
无论规模大小或服务器后端如何,单个 NVIDIA Triton Inference Server 实例通常都与 Kubernetes 等容器编排器一起部署。需要一个单独的层(部署编排器)来管理实例、按需自动扩展集群、管理模型生命周期、请求路由和其他基础架构问题,如表 1 的最后两行所示。
集成训练和服务堆栈
虽然训练和服务都需要各自的基础架构堆栈,但出于以下原因,您希望将其紧密对齐。
首先,部署模型应该是常规操作,不需要多行代码,更糟糕的是,不需要手动操作。
其次,您希望保持已部署模型的完整沿袭,以便您可以了解从原始数据和预处理到经过训练的模型的整个链,并最终部署生成实时推理的模型。在处理 A/B 实验、部署数百个并行模型或从端点调试响应时,此功能会派上用场。
在本文的指导工作流中,您将模型部署到 NVIDIA Triton Inference Server,以便在堆栈中传输版本信息。这样,您可以回溯推理,一直到原始数据。
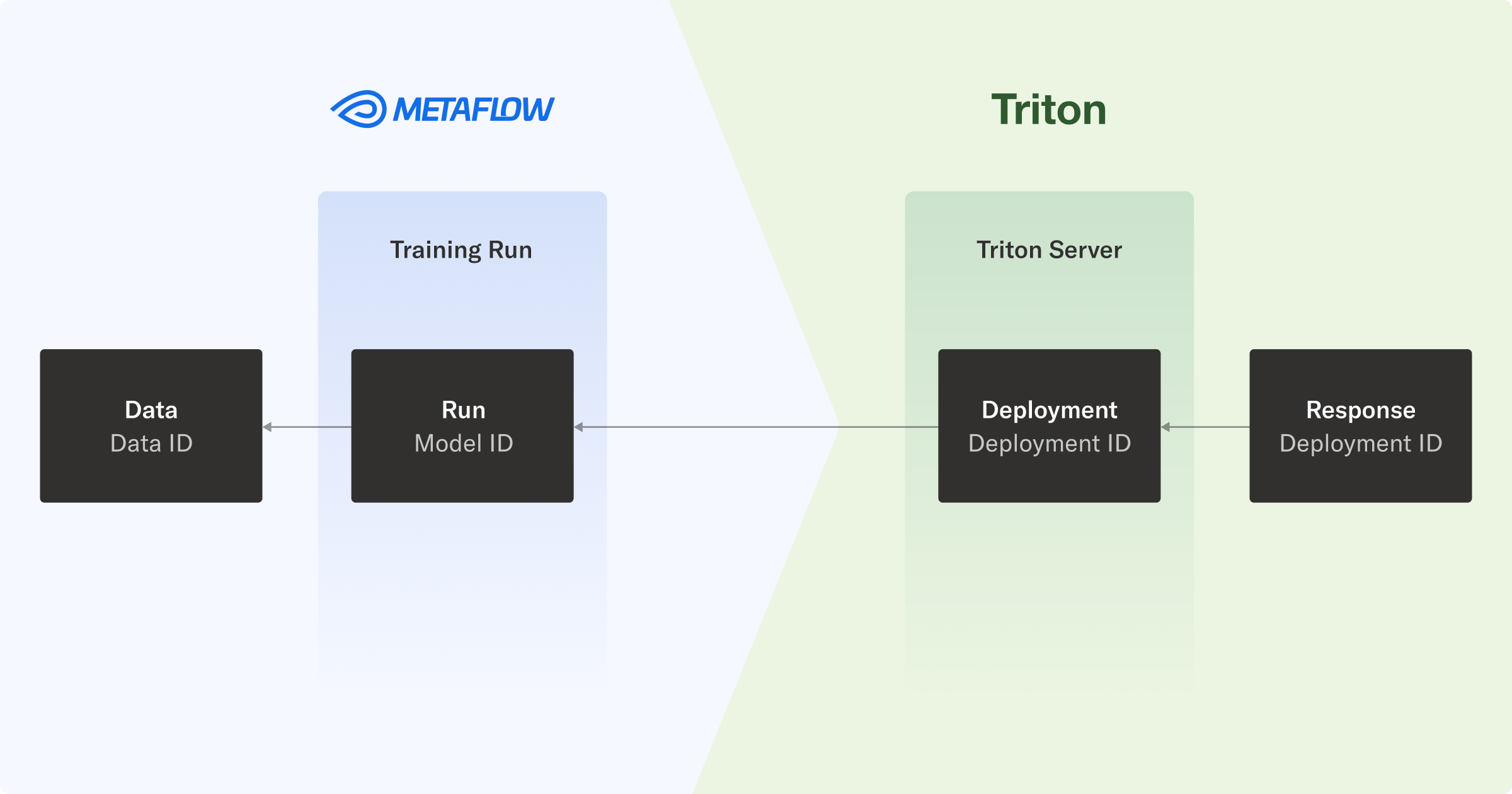
端到端沿袭和可调试性意味着,当托管模型的端点响应请求时,您可以将预测追踪到生成模型及其训练数据的工作流。
在实践中,每个响应都包含 NVIDIA Triton 推理服务器部署 ID,该 ID 映射到 Metaflow 运行 ID,进而使您能够检查用于生成模型的数据。
示例:训练并提供基于树的模型
为了展示端到端工作流程的实际应用,我们提供了一个实际示例。您可以使用 triton-metaflow-starter-pack GitHub 库。
我们的工作流程示例解决了欺诈检测问题,这是一项用于预测贷款违约情况的分类任务。它并行训练多个 Scikit-learn 模型,选择性能最佳的模型,并将该模型推送到 NVIDIA Triton 推理服务器所使用的基于云的模型注册表中。
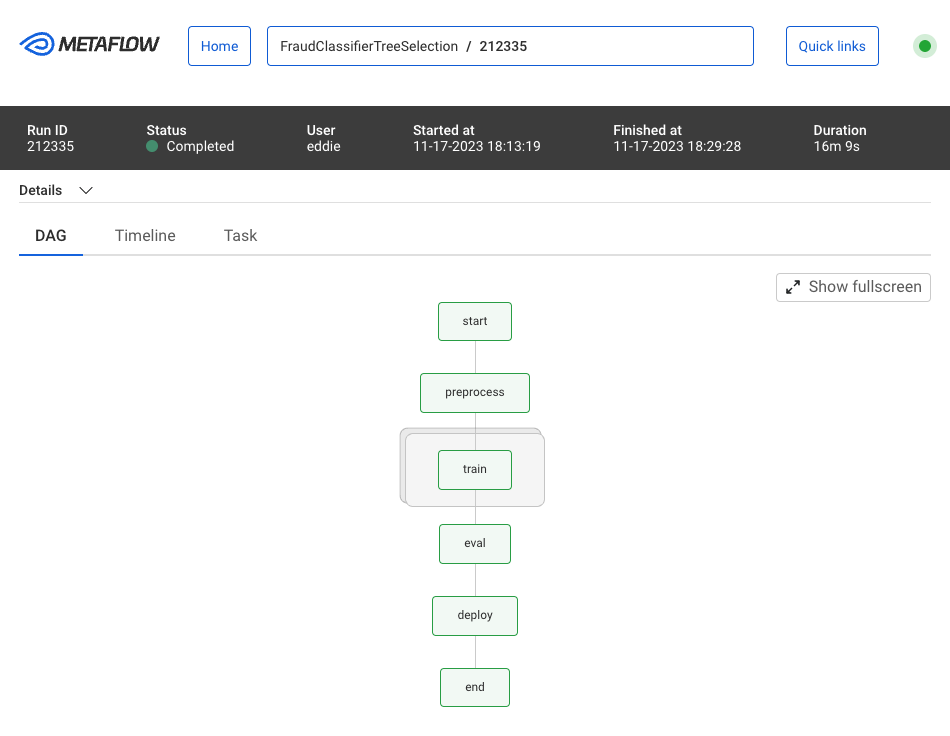
Metaflow UI 支持监控和可视化您的工作流程运行,通过运行 ID 组织工作流程,并无缝跟踪工作流程运行产生的所有构件。
为了让您了解工作流代码的内容,以下代码示例定义了前三个步骤:start、preprocess 和 train.
class FraudClassifierTreeSelection(FlowSpec):
@step
def start(self):
self.next(self.preprocess)
@batch(cpu=1, memory=8000)
@card
@step
def preprocess(self):
self.compute_features()
self.setup_model_grid(model_list=["Random Forest"])
self.next(self.train, foreach="model_grid")
@batch(cpu=4, memory=16000)
@card
@step
def train(self):
self.model_name, self.model_grid = self.input
self.best_model = self.smote_pipe(
self.model_grid, self.X_train_full, self.y_train_full
)
self.next(self.eval)
...
训练步骤采用了Metaflow 的 foreach 结构。在这种情况下,您可以通过指定 @batch 装饰器,使用 AWS Batch 来执行。以下命令可用于手动运行工作流程:
python train/flow.py run \
--model-repo s3://outerbounds-datasets/triton/tree-models/
在您的环境中部署 Metaflow 后,除了编写和执行工作流程之外,您无需编写任何其他配置或 Dockerfile。您可以使用单个命令部署工作流程,以便在更广泛的系统中定时或者由事件触发。
为 NVIDIA Triton 推理服务器准备模型
工作流的部署步骤负责准备使用 NVIDIA Triton 推理服务器部署的模型。这通过以下步骤完成:
- 在 NVIDIA Triton 推理服务器的模型配置中,您可以设置后端属性和其他属性。其中一些属性取决于训练过程中的变量,因此您可以动态创建配置文件,并将其作为构件包的一部分,在模型训练期间上传到云存储。
- NVIDIA Triton 推理服务器还需要模型的具体表示形式。考虑到您对服务效率的关注,可以使用 Treelite,这个工具支持 Scikit-learn 树模型、XGBoost 和 LightGBM。将生成的 checkpoint.tl 文件放置在模型库中后,NVIDIA Triton 推理服务器便能知晓如何处理。
- 序列化模型文件是使用Metaflow 内置优化的 Amazon S3 客户端命名的,该命名基于独特的工作流运行 ID,该 ID 可用于访问用于训练模型的所有信息。这样做可以保持从推理响应到数据处理和训练工作流的完整溯源。
NVIDIA Triton 推理服务器性能
在提供树模型方面,NVIDIA Triton 推理服务器搭配了 FIL 后端。我们进行了一个简单的基准测试,以了解推理延迟与使用 FastAPI 作为前端和 Uvicorn 作为后端的基于 Python 的基准 API 服务器相比如何。您可以通过 triton-metaflow-starter-pack GitHub 库来使用这些资源。
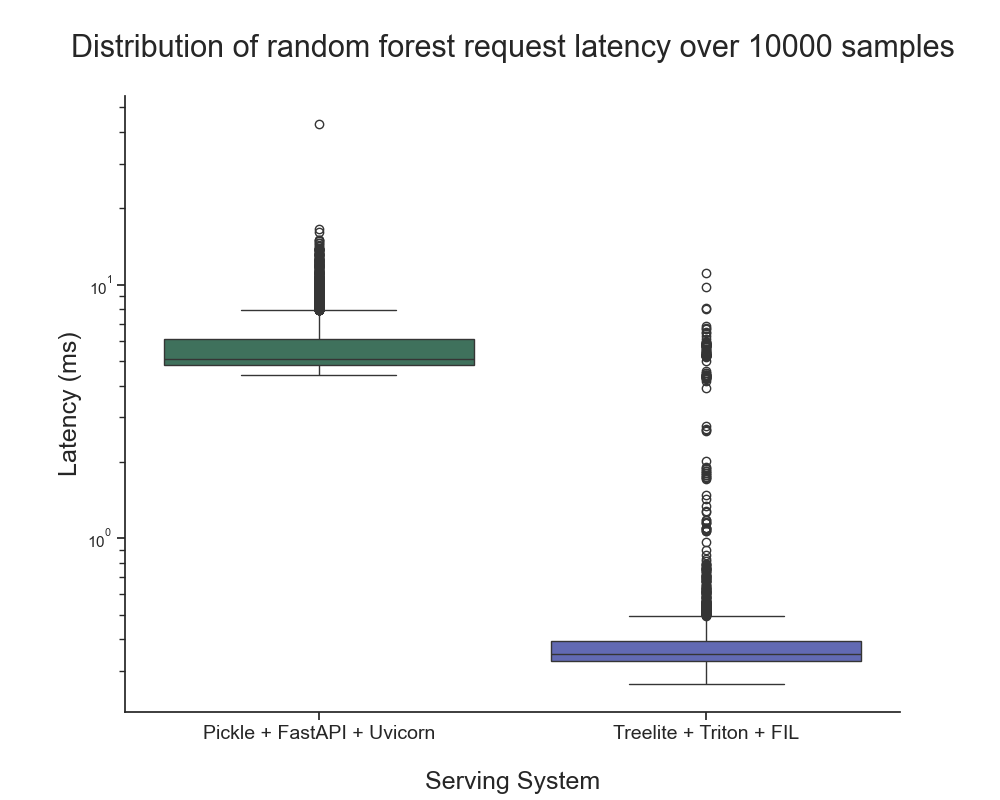
我们观察到, NVIDIA Triton 推理服务器的响应时间(不包括网络开销)为 0.44 毫秒 × 0.64 毫秒,而 FastAPI 为 5.15 毫秒 × 0.9 毫秒。这一差异超过一个数量级。
基准测试是在配备了 8 个至强处理器核心的CoreWeave服务器上进行的,结果表明 NVIDIA Triton 推理服务器能够在各种环境中提供显著的加速效果,而不仅限于 NVIDIA GPU。
我们计划比较更有趣的服务器组合,探索 NVIDIA Triton 推理服务器优化(例如动态请求批处理),并扩展到网络开销的实际复杂性。
用于生产推理的 NVIDIA Triton 推理服务器
安全性、可靠性和企业级支持对于生产级 AI 至关重要。
NVIDIA AI Enterprise 是一个包含 NVIDIA Triton 推理服务器的生产就绪型推理平台。它旨在通过企业级安全性、支持和 API 稳定性来加速价值实现,以确保性能和高可用性。
您可以使用此推理平台减轻维护和保护复杂的 AI 软件平台的负担。
微调并服务于 LLM
2023 年,在讨论模型服务时,我没有提及 LLM。NVIDIA Triton 推理服务器为深度学习模型提供支持,并且针对服务 LLM 提供了日益复杂的支持。然而,高效地服务 LLM 是一个深入且快速发展的领域。
为了向您展示如何使用 NVIDIA Triton 推理服务器为 LLM 提供服务的示例,我采用了这个工作流程,从 HuggingFace 微调 Lama2 模型以生成 QLoRA,并利用 NVIDIA Triton 推理服务器为生成的模型提供服务。欲了解更多信息,请参阅使用 Metaflow 微调大型语言模型,结合 LLaMA 和 LoRA以及更好、更快、更强的 LLM 微调。
与之前一样,我构建了 NVIDIA Triton 推理服务器 的 配置,以便在工作流程完成模型训练后动态运行。此示例旨在作为概念验证。
后续步骤
在您自己的环境中开始尝试使用本文重点介绍的端到端 AI 堆栈。有关更多信息,请参阅以下资源:
- 安装 Metaflow
- Outerbounds
- NVIDIA Triton 推理服务器 可与 NVIDIA AI Enterprise 一起使用,并享受 90 天免费试用 软件评估许可证
如果您有任何疑问或反馈,请加入Metaflow 社区的 Slack 频道,与数千名 ML/AI 开发者和工程师交流。