
最近,瑞典一家大型银行利用 NVIDIA GPU 训练生成式对抗神经网络(GAN),将其纳入其防范欺诈和洗钱的策略中。金融欺诈和洗钱对金融机构和社会构成了巨大挑战,金融机构在识别和预防可疑及非法活动方面投入了大量资源。根据报告,大型机构通过使用 AI 进行欺诈检测,在一年内节省了约 1.5 亿美元。

识别金融欺诈和洗钱的现有方法依赖于人工设计的规则数据库,这些规则与金融交易中的可疑模式相匹配。随着新计划的识别,新规则会添加到规则库中。
瑞典银行针对这些问题开发了新的解决方案,在 GPU 上结合使用深度学习技术,从而生成用于识别可疑活动的先进解决方案。这种方法是通过 GAN 进行异常检测,以半监督式方式对问题建模。该解决方案需要软件和硬件,可以扩展以处理和训练基于大量数据的模型。Hopsworks 基于大小高达 40 TB 的数据集训练模型。为此,我们使用 Hopsworks 软件平台,NVIDIA V100 GPU 大规模设计功能,并使用多个 GPU 并行高效训练 GAN。
基于规则与基于模型的欺诈检测
现有的识别欺诈和洗钱的方法依赖于人工设计的规则数据库,这些数据库试图匹配表明欺诈的模式。随着新的欺诈计划的识别,新的规则被添加到规则引擎中。例如,在洗钱中,存在众所周知的模式,即在许多账户中进行洗钱,然后在中心使用雷达不到的小笔交易汇总这些资金,以便日后支出。
在“Rules-Based Fraud Detection code example”(基于规则的欺诈检测代码示例)中,您可以看到识别可疑金融交易的基于规则的方法。在这里,您定义了适用于所有金融交易的大量规则。如果交易符合任何规则,则触发警报。如果警报被错误触发(误报),则会产生成本。如果未触发任何警报,但应该触发(误报),则您必须设计新规则来识别欺诈计划。公司维护这些规则数据库,并定期向客户发送更新。
Rules-Based Fraud Detection
# Rule 1
IF transfersLastDay > 10 && amount > $5k
THEN
alert
END
# Rule 2
IF country is LISTED && amount > $1k
THEN
alert
END
…
# Rule N
… Train Fraud Detection Model
dataset=tf.data(“financial_transactions”)
model = …
model.compile(…)
model.fit(dataset, …)
Detect Fraud with Model
IF model.predict(amount,transfersLastDay,
country, ….) == TRUE
THEN
alert
END给定足够的历史金融交易数据,基于模型的方法比基于规则的方法更擅长模式匹配,因为它们可以泛化为学习欺诈方案,就像现有的欺诈方案一样。在“Train Fraud Detection Model”(训练欺诈检测模型)代码示例中,您可以看到,您必须首先整理已标记的训练数据集:financial_transactions.借助该数据集,您可以训练模型,然后将经过训练的模型用于新的金融交易,以预测它们是否是欺诈或非欺诈。如果金融交易被怀疑存在欺诈,系统会发送警报。
GAN 是金融欺诈预测的自然选择,因为它们可以从历史数据中学习合法交易的模式。对于每笔新的金融交易,模型都会计算异常分数;分数高的金融交易被标记为可疑交易。
GAN 在生产环境中的训练和部署相当具有挑战性,它们需要大量的 GPU 资源、并行超参数搜索,以及分布式训练的支持。这一过程必须非常谨慎,并且需要高级的机器学习经验。其中一个 GAN 的实现是基于使用同步编码器训练从受污染图像数据中进行异常检测的无监督学习,该研究描述了一种异常检测架构,它能够容忍少量错误标记的样本,并支持并行编码器的训练。
使用实体和交易的图形表示来理解欺诈
要检测欺诈模式并触发警报,您可以使用图形和表格特征以及前面介绍的基于 DL 的 GAN 技术。图形由节点(也称为顶点)和边缘(也称为弧形)组成。在金融应用中,图形可以对企业和个人的事务交互进行建模。
为了展示图形的效用,我们举个例子。用不同的标题标记企业和个人:企业标记为“公司”,个人标记为“Indiv”。边缘用于表示具有关联日期和金额的交易,箭头表示交易方向。
有多种预期图形模式,例如正常散布模式(也称为公英),会在组织支付薪酬时发生。这种模式发生在特定日期,薪酬相对固定,资金流从单个支付者流出。异常散布模式是指交易的突然爆发,这在以前参与节点或双向资金流中从未见过。
图 1 显示了收集 – 散布模式,即资金最初在 1 月流入中心节点。这些资金随后在 2 月流出到其他节点。在洗钱领域,这种收集 – 散布模式用于隐藏金融机构的资金分配情况。同样,图 2 显示了在不同日期再次具有双向资金流的散布 – 收集模式。在这种情况下,资金的来源和目的地是两个不同的中心实体。
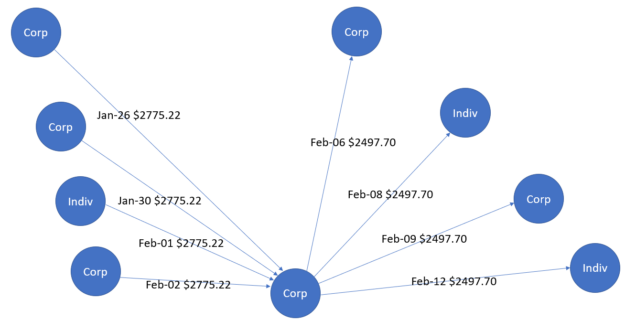
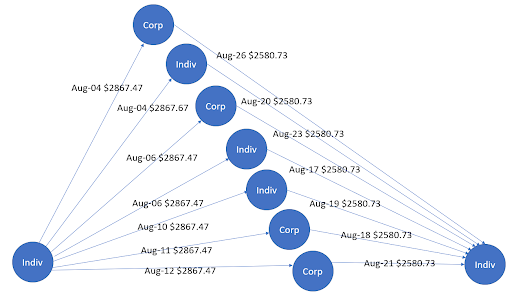
基于 DL 的 GAN 方法基于表格特征和图形特征,可以检测此类欺诈模式,其中一个示例基于在 NVIDIA GPU 上使用 Hopsworks.此类方法与基于规则的技术并存,以获得更好的结果、准确性和混淆矩阵。
将欺诈建模为二进制分类问题所面临的挑战
图 3 显示了金融欺诈二进制分类器的混淆矩阵。对于洗钱等问题,应大幅提高假阴性的权重。使用 F1 分数的变体来评估模型:精度、召回和辐射的权重不应相等。
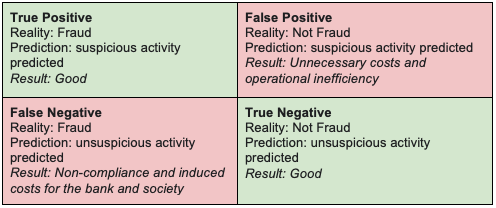
在检测洗钱模式方面还有其他挑战:
- 严重的类别不平衡:被标记为可疑的交易可能不到历史交易总数的 0.0001%。
- 非平稳性:不断有人发明新的洗钱计划。为了识别新出现的模式,相关技术必须能够自我调整或易于调整。
Logical Clocks,开源 Hopsworks 平台的开发者,已发布一个用于检测欺诈的完整端到端开源示例。
- 金融交易的原始数据集样本
- 特征工程程序,用于计算图形嵌入等复杂特征,并将其存储在特征存储中
- 用于查找 GAN 良好超参数的 Notebook
- 使用多个 GPU 对 GAN 进行分布式训练。
代码可以在任何 Hopsworks 集群 上运行,包括 AWS 和 Microsoft Azure 上提供的托管 Hopsworks 集群,以及在本地使用 NVIDIA GPU 安装的 Hopsworks。Hopsworks 集群能够管理多达数千个 GPU,并可按需分配给应用程序。
用于加速金融数据科学的 NVIDIA GPU
在大量客户记录中识别欺诈和洗钱是金融机器学习(ML)和深度学习(DL)的经典用例。由于需要数万亿次浮点运算(TOPS),因此应用 GPU 可显著加速神经网络训练过程。许多数据科学家都知道 NVIDIA GPU 多年来一直在帮助 ML 训练过程。
当神经网络训练完成且推理阶段变得更加重要时,最近推出的开源软件 NVIDIA Triton 推理服务器 可以帮助简化和管理推理加速和生产模型部署。Triton 服务器可以作为 Docker 容器、在 bare metal 上运行,也可以在虚拟化环境中的虚拟机中运行。Hopsworks 支持在 使用 KFServing 的 Triton 服务器。
Hopsworks 支持使用 TensorFlow、PyTorch 和 Scikit-Learn 进行 ML/DL 训练,并额外支持使用 TensorFlow 和 PyTorch 上的透明数据并行训练、超参数调优和并行消融研究 Maggy。Hopsworks 适用于多 GPU、单节点系统以及多 GPU 系统集群。DGX A100 系统 现在是用于在 GPU 上进行分布式训练的 AI 基础设施的通用系统。每个 DGX A100 系统都提供以下配置:
- 8 块 NVIDIA 100 Tensor Core GPU
- 80GB GPU 显存,总计 640GB
- SXM (NVLink) 外形规格
- 与 NVIDIA NVLink 交换机 相关
- 分别为 5 petaFLOPS 或 10 petaOPS INT8
多 GPU、多节点 DGX A100 系统构成 Hopsworks 平台上的 Superpod,可显著加速 DL 训练和推理工作负载。通过与 OEM 合作伙伴、系统集成商和增值经销商的 NVIDIA 合作伙伴网络 (NPN) 合作,您可以在 NVIDIA GPU 上实现类似的配置。
图 4 展示了使用 Hopsworks 的 DL 系统架构,这些系统可以利用 TensorFlow 和 CollectiveAllReduceStrategy 进行数据并行分布式 GPU 训练。Hopsworks 中支持的 Maggy 框架有助于简化 TensorFlow 开发流程。 CollectiveAllReduceStrategy 通过使用 Spark 对分布式计算进行透明管理,在多 GPU、多节点系统上运行。大型集群还受益于使用 NVSwitch 的 GPU 互连。未来,我们还将看到使用 NVSwitch 的 NVIDIA Rapids.ai 框架和 Spark 在 GPU 上的应用。
在 NVIDIA 认证的多 GPU、多节点系统上使用 Hopsworks 优化分布式训练
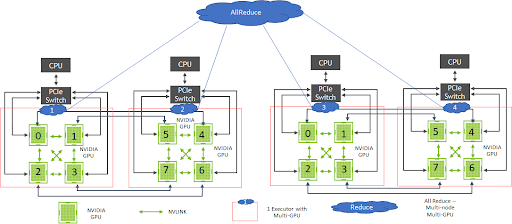
为了使用其他架构对经过训练的模型进行推理, NVIDIA 通过 NVIDIA Triton 推理服务器框架支持多个推理工作负载、并发应用程序和 DL 模型实例,从而提高了 GPU 利用率。Hopsworks 客户已使用 GAN、视觉和其他需要在 GPU 上进行大量分布式训练的 DL 模型来开发尖端 AI 系统。
以下内容 LogicalClocks 中的端到端洗钱示例 在 DGX 系统上使用多 GPU、多节点框架上的设置训练用于异常检测的 GAN 模型。使用此类设置的训练时间几乎可以实现线性扩展,也称为 强扩展 加速 DL 训练。此外,使用 Triton 服务器框架进行此类模型的推理可以高效使用 GPU。
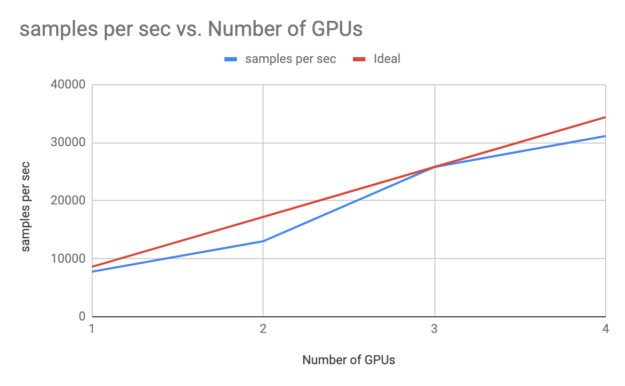
您还可以使用其他框架(包括 RAPIDS.ai、基于 GPU 的 Spark 和 NVIDIA GRAPH 框架 CuGraph)在 Hopsworks 平台上的 GPU 上加速此类功能。
联系我们
团队合作是设计准确的金融欺诈和洗钱解决方案的关键。从基于规则的方法到基于模型的方法是一个常见的技术目标。其目标是减少金融机构在生产中使用欺诈检测或洗钱模型时可能收到的错误分类结果的数量。如今,客户期望其金融机构在预防欺诈和限制错误警报方面更准确。
如需了解更多信息以及分享您在此重要用例和先进方法方面的经验,请在下方发表评论。



