
光学字符检测(OCD)和光学字符识别(OCR)是用于从图像中提取文本的计算机视觉技术。不同行业的使用情况各不相同,包括从扫描的文档或带有手写文本的表格中提取数据、自动识别车牌、根据序列号对履行中心中的箱子或物体进行分类、根据零件号识别组装线上要检查的部件等。
OCR 应用于许多行业,包括金融服务、医疗保健、物流、工业检测和智能城市。OCR 通过自动化手动任务,提高了企业的生产效率和运营效率。
为了有效,OCR 必须达到或超过人类水平的准确性。由于它所涉及的独特用例,它本身就很复杂。例如,当 OCR 分析文本时,文本可以在字体、大小、颜色、形状和方向上变化,可以是手写的,也可以具有其他噪声,如部分遮挡。在测试环境中微调模型对于保持高精度和降低错误率变得极其重要。
NVIDIA TAO 工具包 是一个低代码人工智能工具包,可以帮助开发人员为许多视觉人工智能应用程序定制和优化模型。NVIDIA 在 TAO 5.0 中引入了用于自动字符检测和识别的新模型和功能。这些模型和功能将加速创建自定义 OCR 解决方案。有关更多详细信息,请参阅 Access the Latest in Vision AI Model Development Workflows with NVIDIA TAO Toolkit 5.0。
本文是关于使用 NVIDIA TAO 和预训练模型创建和部署自定义 AI 模型以准确检测和识别手写文本的系列文章的一部分。这一部分解释了使用 TAO 对字符检测和识别模型的训练和微调。第二部分将引导您完成使用 NVIDIA Triton 部署模型的步骤。所提供的步骤可用于任何其他 OCR 任务。
NVIDIA TAO OCD/OCR 工作流程
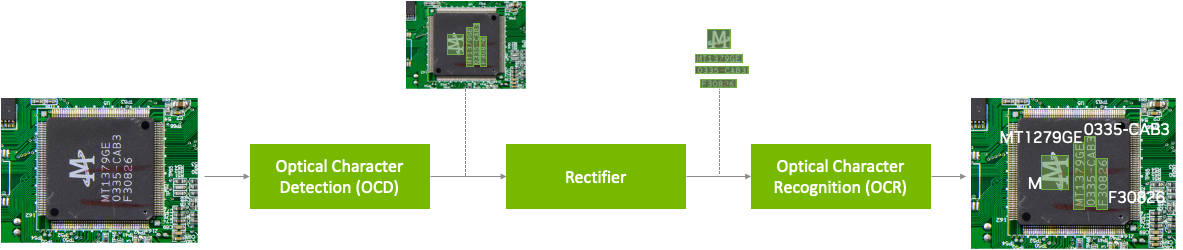
预训练的模型已经在大型数据集上进行了训练,并且可以使用额外的数据进行进一步的微调,以完成特定的任务。光学字符检测网络(OCDNet)是一个 TAO 预训练模型,用于检测具有复杂背景的图像中的文本。它使用一种称为可微分二值化的过程来帮助准确定位各种形状、大小和字体的文本。结果是具有检测到的文本的边界框。
文本整流器是一种中间件,在推理阶段充当字符检测和字符识别之间的桥梁。它的主要功能是提高识别极端角度文本中字符的准确性。为了实现这一点,文本整流器将覆盖文本区域的多边形顶点和原始图像作为输入。
光学字符识别网络(OCRNet)是另一个 TAO 预训练模型,可用于识别位于检测到的边界框区域中的文本字符。该模型将图像作为网络输入,并生成一系列字符作为输出。
先决条件
要继续学习本教程,您需要以下内容:
- 一个NGC account
- 这是一个样品 Jupyter notebook,用于训练 OCD 和 OCR 模型。
- NVIDIA TAO Toolkit 5.0(包含在 Jupyter 笔记本电脑中的安装说明)。有关一组完整的依赖项和先决条件,请参阅 TAO Toolkit 快速启动指南。
下载数据集
本教程对 OCD 和 OCR 模型进行了微调,以检测和识别手写字母。它使用了IAM Handwriting Database,这是一个包含各种手写英文文本文档的大型数据集。这些文本样本将用于训练和测试 OCD 和 OCR 模型的手写文本识别器。
若要访问此数据集,请在IAM 注册页面进行注册。
注册后,从下载页面开始:
- 数据/asci.tgz
- 数据/表格 A-D.tgz
- 数据/表格-H.tgz
- 数据/表格-Z.tgz
以下部分探讨了 Jupyter 笔记本的各个方面,以深入研究 OCDNet 和 OCRNet 的微调过程,从而检测和识别手写字符。
请注意,此数据集可能仅用于非商业性研究目的。想要了解更多信息,请访问IAM 手写数据库。
运行笔记本
OCDR Jupyter 笔记本展示了如何将 OCD 和 OCR 模型微调为 IAM 手写数据集。它还展示了如何在经过训练的模型上运行推理并执行部署。
设置环境变量
在 Jupyter 笔记本中设置以下环境变量以匹配当前目录,然后执行:
%env LOCAL_PROJECT_DIR=home/<username>/ocdr_notebook
%env NOTEBOOK_DIR=home/<username>/ocdr_notebook
# Set this path if you don't run the notebook from the samples directory.
%env NOTEBOOK_ROOT=home/<username>/ocdr_notebook将生成以下文件夹:
- 主机数据 包含了用于模型训练的训练/测试分割数据。
- 主机规范目录 包含了规范文件,这些文件中包含了 TAO 用于执行训练、推理、评估和模型部署的超参数。
- 主机结果目录 包含经过微调的 OCD 和 OCR 模型的结果。
- 预数据 是指下载的手写数据集文件的位置。这个路径将被用来预处理 OCD/OCR 模型训练的数据。
TAO 启动器在运行任务时使用 Docker 容器。要使数据和结果对 Docker 可见,请使用~/.tao_mounts.json文件运行 Jupyter 笔记本中的单元格以生成~/.tao_mounts.json文件
该环境现在可以与 TAO Launcher 一起使用了。接下来的步骤将为 TAO OCD 模型训练准备正确格式的手写数据集。
为 OCD 和 OCR 准备数据集
按照以下步骤预处理 IAM 手写数据集以匹配 TAO 图像格式。注意,在 TAO 中用于 OCD 和 OCR 模型训练的文件夹结构中, /img容纳手写图像数据,以及/gt包含在每个图像中发现的字符的基本真相标签。
|── train
| ├──img
| ├──gt
|── test
| ├──img
| ├──gt首先将下载的四个.tgz 文件移动到$PRE_DATA_DIR目录如果您遵循与上面相同的步骤,.tgz 文件将被放置在/data/iamdata.
从这些文件中提取图像和地面实况标签。随后的单元格将提取图像文件,并在运行时将其移动到正确的文件夹格式。
!tar -xf $PRE_DATA_DIR/ascii.tgz --directory $PRE_DATA_DIR/ words.txt
# Create directories to hold the image data and ground truth files.
!mkdir -p $PRE_DATA_DIR/train/img
!mkdir -p $PRE_DATA_DIR/test/img
!mkdir -p $PRE_DATA_DIR/train/gt
!mkdir -p $PRE_DATA_DIR/test/gt
# Unpack the images, let's use the first two groups of images for training, and the last for validation.
!tar -xzf $PRE_DATA_DIR/formsA-D.tgz --directory $PRE_DATA_DIR/train/img
!tar -xzf $PRE_DATA_DIR/formsE-H.tgz --directory $PRE_DATA_DIR/train/img
!tar -xzf $PRE_DATA_DIR/formsI-Z.tgz --directory $PRE_DATA_DIR/test/img数据现在已正确组织。然而,IAM 数据集使用的基本事实标签目前采用以下格式:
a01-000u-00-00 ok 154 1 408 768 27 51 AT A
# a01-000u-00-00 -> word id for line 00 in form a01-000u
# ok -> result of word segmentation
# ok: word was correctly
# er: segmentation of word can be bad
#
# 154 -> graylevel to binarize the line containing this word
# 1 -> number of components for this word
# 408 768 27 51 -> bounding box around this word in x,y,w,h format
# AT -> the grammatical tag for this word, see the
# file tagset.txt for an explanation
# A -> the transcription for this word
这个words.txt文件如下所示:
0 1
0 a01-000u-00-00 ok 154 408 768 27 51 AT A
1 a01-000u-00-01 ok 154 507 766 213 48 NN MOVE
2 a01-000u-00-02 ok 154 796 764 70 50 TO to
...
目前,words.txt使用四点坐标系在图像中的单词周围绘制边界框。 TAO 要求使用八点坐标系在检测到的文本周围绘制边界框。
要将数据转换为八点坐标系,请使用extract_columns和process_text_file笔记本第 2.1 节中提供的功能。words.txt将被转换为以下 DataFrame,并准备在 OCDNet 模型上进行微调。
filename x y x2 y2 x3 y3 x4 y4 word
0 gt_a01-000u.txt 408 768 435 768 435 819 408 819 A
1 gt_a01-000u.txt 507 766 720 766 720 814 507 814 MOVE
2 gt_a01-000u.txt 796 764 866 764 866 814 796 814 to
...为了为 OCRNet 准备数据集,必须将原始图像数据和标签转换为 LMDB 格式,LMDB 格式将图像和标签转换成键值内存数据库。
# Convert the raw train and test dataset to lmdb
print("Converting the training set to LMDB.")
!tao model ocrnet dataset_convert -e $SPECS_DIR/ocr/experiment.yaml \
dataset_convert.input_img_dir=$DATA_DIR/train/processed \
dataset_convert.gt_file=$DATA_DIR/train/gt.txt \
dataset_convert.results_dir=$DATA_DIR/train/lmdb
# Convert the raw test dataset to lmdb
print("Converting the testing set to LMDB.")
!tao model ocrnet dataset_convert -e $SPECS_DIR/ocr/experiment.yaml \
dataset_convert.input_img_dir=$DATA_DIR/test/processed \
dataset_convert.gt_file=$DATA_DIR/test/gt.txt \
dataset_convert.results_dir=$DATA_DIR/test/lmdb
数据现在已经处理完毕,可以在 OCDNet 和 OCRNet 预训练模型上进行微调。
创建自定义字符检测(OCD)模型
NGC CLI 将用于下载经过预训练的 OCDNet 模型。想要了解更多信息,请访问 NGC,然后点击导航栏中的“设置”。
下载 OCDNet 预训练模型
!mkdir -p $HOST_RESULTS_DIR/pretrained_ocdnet/
# Pulls pretrained models from NGC
!ngc registry model download-version nvidia/tao/ocdnet:trainable_resnet18_v1.0 --dest $HOST_RESULTS_DIR/pretrained_ocdnet/您可以使用以下调用检查模型是否已下载到/pretained_ocdnet/:
print("Check that model is downloaded into dir.")
!ls -l $HOST_RESULTS_DIR/pretrained_ocdnet/ocdnet_vtrainable_resnet18_v1.0
OCD 训练规范
在 specs 文件夹中,可以找到与两个模型的训练、评估、推断和导出数据的方式相关的不同文件。对于训练 OCDNet,您将使用 specs/ocd 文件夹中的 train.yaml 文件。您可以在这个规范文件中尝试更改不同的超参数,例如纪元的数量。
下面是一些可以进行实验的配置的代码示例:
num_gpus: 1
model:
load_pruned_graph: False
pruned_graph_path: '/results/prune/pruned_0.1.pth'
pretrained_model_path: '/data/ocdnet/ocdnet_deformable_resnet18.pth'
backbone: deformable_resnet18
train:
results_dir: /results/train
num_epochs: 300
checkpoint_interval: 1
validation_interval: 1
...
训练角色检测模型
既然已经配置了规范文件,请提供规范文件、预训练模型和结果的路径:
#Train using TAO Launcher
#print("Run training with ngc pretrained model.")
!tao model ocdnet train \
-e $SPECS_DIR/train.yaml \
-r $RESULTS_DIR/train \
model.pretrained_model_path=$DATA_DIR/ocdnet_deformable_resnet18.pth培训输出如下所示。请注意,此步骤可能需要一些时间,具体取决于train.yaml.
LOCAL_RANK: 0 - CUDA_VISIBLE_DEVICES: [0]
| Name | Type | Params
--------------------------------
0 | model | Model | 12.8 M
--------------------------------
12.8 M Trainable params
0 Non-trainable params
12.8 M Total params
51.106 Total estimated model params size (MB)
Training: 0it [00:00, ?it/s]Starting Training Loop.
Epoch 0: 100%|█████████| 751/751 [19:57<00:00, 1.59s/it, loss=1.61, v_num=0]评估模型
接下来,评估在 IAM 数据集上训练的 OCDNet 模型。
# Evaluate on model
!tao model ocdnet evaluate \
-e $SPECS_DIR/evaluate.yaml \
evaluate.checkpoint=$RESULTS_DIR/train/model_best.pth评估输出如下所示:
test model: 100%|██████████████████████████████| 488/488 [06:44<00:00, 1.21it/s]
Precision: 0.9412259824693795
Recall: 0.8738614928590677
Hmean: 0.9062936622138628
Evaluation finished successfully.
OCD 推断
推理工具生成带注释的图像输出和包含预测信息的.txt 文件。运行下面的推理工具,在 OCDNet 模型上生成推理,并可视化检测到的文本的结果。
# Run inference using TAO
!tao model ocdnet inference \
-e $SPECS_DIR/ocd/inference.yaml \
inference.checkpoint=$RESULTS_DIR/ocd/train/model_best.pth \
inference.input_folder=$DATA_DIR/test/img \
inference.results_dir=$RESULTS_DIR/ocd/inference图 3 显示了 OCDNet 对测试样本图像的推断。

导出 OCD 模型以进行部署
最后一步是将 OCD 模型导出为 ONNX 格式以进行部署。
!tao model ocdnet export \
-e $SPECS_DIR/export.yaml \
export.checkpoint=$RESULTS_DIR/train/model_best.pth \
export.onnx_file=$RESULTS_DIR/export/model_best.onnx创建自定义字符识别(OCR)模型
现在您已经有了经过训练的 OCDNet 模型来检测并将边界框应用于手写文本区域,请使用 TAO 微调 OCRNet 模型以识别和分类检测到的字母。
下载 OCRNet 预训练模型
在 Jupyter 笔记本中继续,OCRNet 预训练模型将从 NGC CLI 中提取。
!mkdir -p $HOST_RESULTS_DIR/pretrained_ocrnet/
# Pull pretrained model from NGC
!ngc registry model download-version nvidia/tao/ocrnet:trainable_v1.0 --dest $HOST_RESULTS_DIR/pretrained_ocrnetOCR 培训规范
OCRNet 将使用 experiment.yaml 规范文件进行训练。您可以更改训练超参数,如批量大小、时期数量和学习率,如下所示:
dataset:
train_dataset_dir: []
val_dataset_dir: /data/test/lmdb
character_list_file: /data/character_list
max_label_length: 25
batch_size: 32
workers: 4
train:
seed: 1111
gpu_ids: [0]
optim:
name: "adadelta"
lr: 0.1
clip_grad_norm: 5.0
num_epochs: 10
checkpoint_interval: 2
validation_interval: 1
训练字符识别模型
在数据集上训练 OCRNet 模型。您还可以在 train 命令中配置 spec 参数,如历元数或学习率,如下所示。
!tao model ocrnet train -e $SPECS_DIR/ocr/experiment.yaml \
train.results_dir=$RESULTS_DIR/ocr/train \
train.pretrained_model_path=$RESULTS_DIR/pretrained_ocrnet/ocrnet_vtrainable_v1.0/ocrnet_resnet50.pth \
train.num_epochs=20 \
train.optim.lr=1.0 \
dataset.train_dataset_dir=[$DATA_DIR/train/lmdb] \
dataset.val_dataset_dir=$DATA_DIR/test/lmdb \
dataset.character_list_file=$DATA_DIR/train/character_list.txt
输出将类似于以下内容:
...
Epoch 19: 100%|█| 3605/3605 [08:04<00:00, 7.44it/s, loss=0.0368, v_num=1, val_lCurrent_accuracy : 0.778
Best_accuracy : 0.727
+----------------+--------------+---------------------+
| Ground Truth | Prediction | Confidence && T/F |
|----------------+--------------+---------------------|
| at | al | 0.2867 False |
| home | home | 0.7792 True |
| . | . | 0.9828 True |
| there | there | 0.5470 True |
| had | had | 0.6234 True |
+----------------+--------------+---------------------+
评估模
您可以根据 OCRNet 模型的字符识别准确性来评估该模型。识别准确率只是指文本区域中正确识别的所有字符的百分比。
!tao model ocrnet evaluate -e $SPECS_DIR/ocr/experiment.yaml \
evaluate.results_dir=$RESULTS_DIR/ocr/evaluate \
evaluate.checkpoint=$RESULTS_DIR/ocr/train/best_accuracy.pth \
evaluate.test_dataset_dir=$DATA_DIR/test/lmdb \
dataset.character_list_file=$DATA_DIR/train/character_list.txt评价
输出应类似于以下内容:
data directory: /data/iamdata/test/lmdb num samples: 37109
Accuracy: 77.8%
OCR 推断
OCR 推断将从边界框中生成已识别字符的序列输出,如下所示。
!tao model ocrnet inference -e $SPECS_DIR/ocr/experiment.yaml \
inference.results_dir=$RESULTS_DIR/ocr/inference \
inference.checkpoint=$RESULTS_DIR/ocr/train/best_accuracy.pth \
inference.inference_dataset_dir=$DATA_DIR/test/processed \
dataset.character_list_file=$DATA_DIR/train/character_list.txt
+--------------------------------------+--------------------+--------------------+
| image_path | predicted_labels | confidence score |
|--------------------------------------+--------------------+--------------------|
| /data/test/processed/l04-012_28.jpg | lelly | 0.3799 |
| /data/test/processed/k04-068_26.jpg | not | 0.9644 |
| /data/test/processed/l04-062_58.jpg | set | 0.9542 |
| /data/test/processed/l07-176_39.jpg | boat | 0.4693 |
| /data/test/processed/k04-039_39.jpg | . | 0.9286 |
+--------------------------------------+--------------------+--------------------+
导出 OCR 模型以进行部署
最后,将 OCD 模型导出为 ONNX 格式以进行部署。
!tao model ocrnet export -e $SPECS_DIR/ocr/experiment.yaml \
export.results_dir=$RESULTS_DIR/ocr/export \
export.checkpoint=$RESULTS_DIR/ocr/train/best_accuracy.pth \
export.onnx_file=$RESULTS_DIR/ocr/export/ocrnet.onnx \
dataset.character_list_file=$DATA_DIR/train/character_list.txt
结果
表 1 详细介绍了本文中提到的两个模型的准确性和性能。字符检测模型在 ICDAR 预训练的 OCDNet 模型上进行了微调,字符识别模型则在 Uber-text OCRNet 预训练模型上进行了微调。ICDAR 和 Uber 文本是公开可用的数据集,我们分别用于预训练 OCDNet 和 OCRNet 模型。这两种模型都可以在 NGC 上找到。
| OCDNet | OCRNet | |
| 数据集 | IAM Handwritten Dataset | |
| 神经网络架构 | 可变形 Conv ResNet18 | ResNet50 |
| 精确 | 90% | 78% |
| 推理分辨率 | 1024×1024 | 1x32x100 |
| NVIDIA L4 上的推理性能(FPS) GPU | 125 帧/秒(BS=1) | 8030(BS=128) |
总结
这篇文章解释了在 NVIDIA TAO 中创建自定义字符检测和识别模型的端到端工作流程。您可以从 NGC 的字符检测(OCDNet)和字符识别(OCRNet)的预训练模型开始。然后使用 TAO 在自定义数据集上对其进行微调,并导出模型进行推理。
请继续阅读第二部分,了解如何使用 NVIDIA Triton 将此模型部署到生产中的分步演练。



