要开发准确的计算机视觉 AI 应用程序,您需要大量高质量的数据。对于传统的数据集,您可能需要花费数月的时间来收集图像、获取注释和清理数据。完成后,您可以找到边缘案例并需要更多数据,从而重新开始循环。
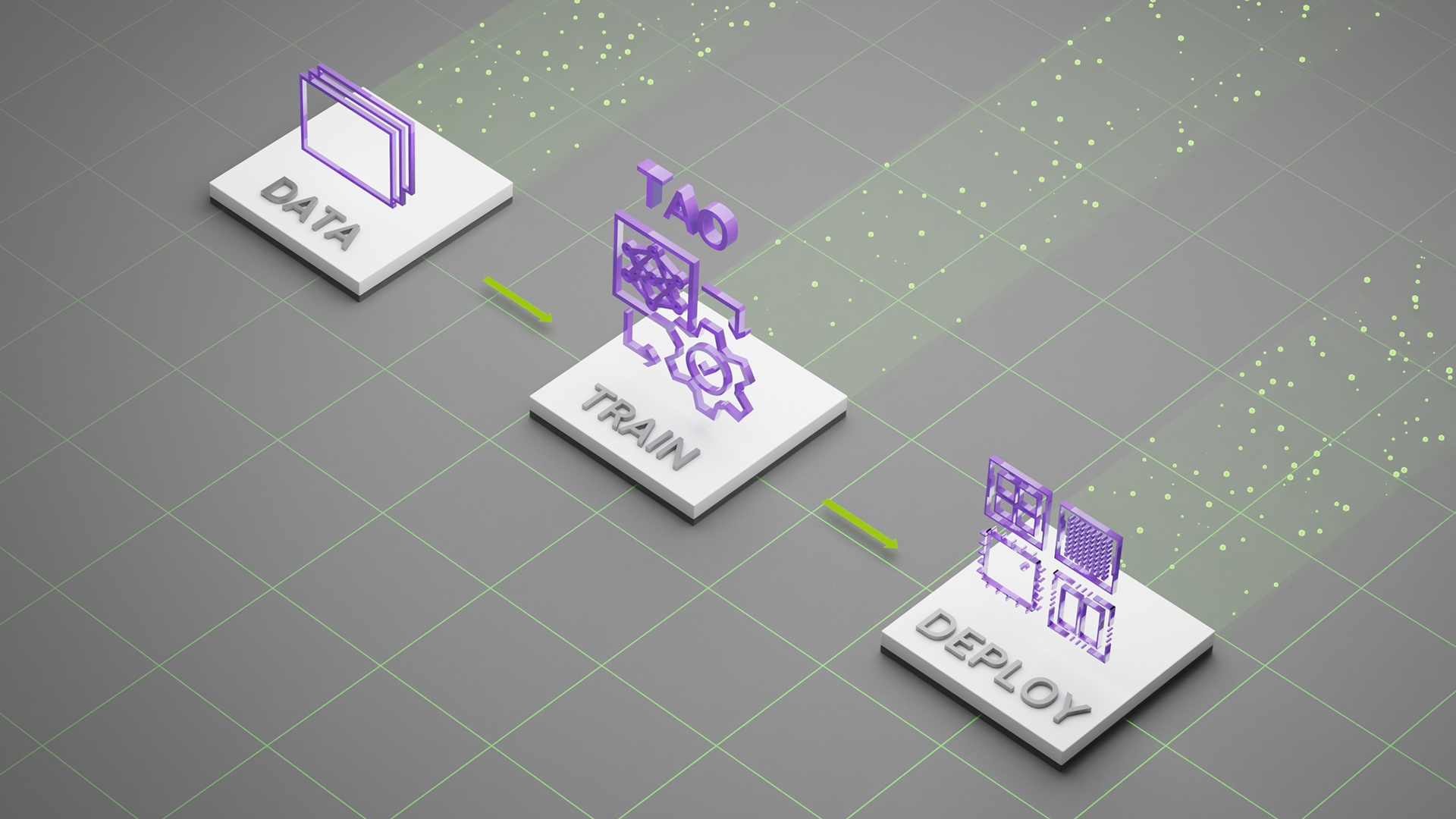
多年来,这种循环阻碍了人工智能的发展,尤其是在计算机视觉领域。 Lexset 构建工具,使您能够生成数据 来解决这个瓶颈。作为 AI 培训周期的一部分,可以开发和迭代具有培训数据的强大新工作流。
Lexset 的 Seahaven 平台可以在几分钟内生成完全带注释的数据集,包括照片级真实感 RGB 图像、语义分割和深度图。迭代可以快速有效地提高模型的准确性。寻找异常事件或罕见情况的数据不再需要几个月的时间。只需快速调整配置并生成新数据,即可使您的模型比以往任何时候都更好。
从 Seahaven 生成的合成数据可用于微调和定制 NVIDIA TAO 工具包中的预训练模型。 TAO 工具包是一种低代码 AI 模型开发解决方案,它抽象了 AI 框架的复杂性,并使您能够使用 transfer learning 为您的特定用例创建定制的、生产就绪的模型。
通过使用 Seahaven 和 TAO 工具包创建初始数据集,大大减少时间并提高准确性。最重要的是,您可以使用合成数据快速调整模型以适应不断变化的条件和不断增加的复杂性。
解决方案概述
对于这个实验,您可以使用一个简单的用例,构建一个计算机视觉模型,该模型能够发现并区分常见的硬件项目,例如螺钉。您从一个简单的背景开始,引入更多的复杂性来展示合成数据如何适应不断变化的条件。
我们创建了一个包含四个螺钉注释的图像的数据集,并使用 TAO 工具包对象检测模型开始。我们使用了更快的 R-CNN 、 RetinaNet 和 YOLOv3 。
在这篇文章中,我介绍了运行这个示例数据集所需的步骤,您可以通过更快的R-CNN来运行这个示例数据集。要运行RetinaNet或YOLOv3,步骤相同,并且在提供的Jupyter笔记本中。
我还分享了 Lexset 合成数据如何与模型训练配合使用,以快速解决随着用例变得更加复杂而可能出现的准确性问题。

要创建自己的数据集以与 TAO 工具包一起使用,请按照 Using Seahaven 和 Seahaven documentation 中的说明进行操作。
要再现所述结果,请遵循以下主要步骤:
- 使用预先训练的 ResNet-18 模型,并在 Lexset 的四螺钉合成数据集上训练 ResNet-18 更快的 RCNN 模型。
- 在合成数据集上使用经过最佳训练的权重,并使用真实世界四螺杆数据集的 10% 对其进行微调。
- 在真实螺钉验证数据集上评估最佳训练和微调权重。
- 对经过训练的模型进行推理。
先决条件
NVIDIA TAO 工具包需要 NVIDIA GPU (例如, A100 )和驱动程序才能使用其 Docker 容器,因此必须有一个才能继续。
您还需要至少 16 GB 的物理 RAM 、 50 GB 的可用内存和 8 核。我们在 Python 3.6.9 上进行了测试,并使用了 Ubuntu 18.04 。 TAO 工具包需要 NVIDIA 驱动程序 455 。 xx 或更高版本。
- tao 启动器严格来说是一个只支持 python3 的包,能够在 Python 3.6.9 或 3.7 或 3.8 上运行。
- 按照 Docker 官方说明 安装 docker ce 。
- 安装 docker ce 后,请遵循 post-installation steps 以确保 docker 可以在没有 sudo 的情况下运行。
- Install nvidia-container-toolkit .
- 您必须有一个 NGC 帐户和一个与您的帐户关联的 API 密钥。有关创建 NGC 帐户和获取 API 密钥的更多信息,请参阅 Installation Prerequisites 部分。
下载数据集
从 Google 驱动器文件夹 (笔记本中也提供了链接)下载数据集,其中包含螺钉合成图像和真实图像的所有 zip 文件。
● synthetic_dataset_without_complex_phase1.zip ● synthetic_dataset_with_complex_phase2.zip ● real_dataset.zip
将synthetic_dataset_without_complex_phase1.zip和real_dataset.zip中的数据集提取到/data目录中。数据集目录结构应如下所示:
├── real_test ├── real_train ├── synthetic_test └── synthetic_train
TAO Toolkit 支持 KITTI 格式的数据集,并且提供的数据集已经是该格式。要进一步验证,请参阅 KITTI 文件格式 。
环境设置
使用virtualenvwrapper创建新的虚拟环境。有关更多信息,请参阅 Python 指南中的 Virtual Environments 。
按照说明安装virtualenv和virtualenvwrapper后,设置 Python 版本:
echo "export VIRTUALENVWRAPPER_PYTHON=/usr/bin/python3" >> ~/.bashrc source ~/.bashrc mkvirtualenv launcher -p /usr/bin/python3
克隆存储库:
git clone https://github.com/Lexset/NVIDIA-TAO-Toolkit---Synthetic-Data.git cd tao-screws
要安装环境所需的依赖项,请安装需求。 txt 文件:
pip3 install -r requirements.txt
启动 Jupyter 笔记本:
cd faster_rcnn jupyter notebook --ip 0.0.0.0 --allow-root --port 8888
设置 TAO 工具包装载
笔记本有一个生成~/.tao_mounts.json文件的脚本。
{ "Mounts": [ { "source": "ABSOLUTE_PATH_TO_PROJECT_NETWORK_DIRECTORY", "destination": "/workspace/tao-experiments" }, { "source": "ABSOLUTE_PATH_TO_PROJECT_NETWORK_SPECS_DIRECTORY", "destination": "/workspace/tao-experiments/faster_rcnn/specs" } ], "Envs": [ { "variable": "CUDA_VISIBLE_DEVICES", "value": "0" } ], "DockerOptions": { "shm_size": "16G", "ulimits": { "memlock": -1, "stack": 67108864 }, "user": "1001:1001" } }
代码示例在 Ubuntu 主目录中生成全局~/.tao_mounts.json文件。
将数据集处理为 TFRecords
下载数据集并将其放入数据目录后,下一步是将 KITTI 文件转换为 NVIDIA TAO 工具包使用的 TFRecord 格式。为合成数据集和真实数据集生成 TFrecords 。 Jupyter 笔记本中的此代码示例生成 TFrecords :
#KITTI trainval !tao faster_rcnn dataset_convert --gpu_index $GPU_INDEX -d $SPECS_DIR/faster_rcnn_tfrecords_kitti_synth_train.txt \ -o $DATA_DOWNLOAD_DIR/tfrecords/kitti_synthetic_train/kitti_synthetic_train !tao faster_rcnn dataset_convert --gpu_index $GPU_INDEX -d $SPECS_DIR/faster_rcnn_tfrecords_kitti_synth_test.txt \ -o $DATA_DOWNLOAD_DIR/tfrecords/kitti_synthetic_test/kitti_synthetic_test
笔记本中的下一个代码示例对真实数据集应用了相同的转换。
下载 ResNet-18 卷积主干网
在本地设置 NGC CLI 时,下载卷积主干网 ResNet-18 。
!ngc registry model list nvidia/tao/pretrained_object_detection*
使用合成数据运行基准测试
以下命令开始对合成数据进行训练,所有日志都保存在out_resnet18_synth_amp16.log文件中。要查看日志,请打开文件,如果文件已打开,请刷新选项卡。
!tao faster_rcnn train --gpu_index $GPU_INDEX -e $SPECS_DIR/default_spec_resnet18_synth_train.txt --use_amp > out_resnet18_synth_amp16.log
或者,您可以使用tail命令查看日志的最后几行。
!tail -f ./out_resnet18_synth_amp16.log
在合成数据集上完成训练后,可以使用以下命令在 10% 合成验证数据集上评估合成训练模型:
!tao faster_rcnn evaluate --gpu_index $GPU_INDEX -e $SPECS_DIR/default_spec_resnet18_synth_train.txt
您可以看到如下结果。
mAP@0.5 = 0.9986
您还可以看到每个类的各个地图分数。
用真实数据微调综合训练模型
现在,使用来自合成训练的最佳训练权重,并对真实螺钉数据集的 10% 进行微调。real_train中的/train文件夹已处于 10% 的拆分状态,您可以使用以下命令开始微调:
!tao faster_rcnn train --gpu_index $GPU_INDEX -e $SPECS_DIR/default_spec_resnet18_real_train.txt --use_amp > out_resnet18_synth_fine_tune_10_amp16.log
结果:实际数据改善了 10%
每个历元的地图分数如下所示:
mAP@0.5 = 0.9408 mAP@0.5 = 0.9714 mAP@0.5 = 0.9732 mAP@0.5 = 0.9781 mAP@0.5 = 0.9745 mAP@0.5 = 0.9780 mAP@0.5 = 0.9815 mAP@0.5 = 0.9820 mAP@0.5 = 0.9803 mAP@0.5 = 0.9796 mAP@0.5 = 0.9810 mAP@0.5 = 0.9817
只需对真实螺钉数据集的 10% 进行微调,即可快速改善结果, mAP 得分超过 98% 。从合成数据集中学习到的功能在微调过程中对实际螺钉数据集的 10% 有所帮助。
在合成螺钉验证数据集中添加复杂背景
为了进一步验证综合训练模型,我们向复杂背景数据集中添加了 300 多幅图像。由于初始合成数据集不是在复杂背景下获取的,因此平均精度显著下降。
就像真实世界一样,随着用例变得更加复杂,准确性也会受到影响。当对包含更复杂或敌对背景的图像进行验证时,地图得分从 98% 左右下降到 83.5% 。
重新训练具有复杂背景的合成数据集
这就是合成数据真正闪耀的地方。为了减少在复杂图像上验证时地图的丢失,我生成了具有更复杂背景的其他图像,以添加到训练数据中。我只是调整了背景,以便新的训练数据集在几秒钟内就准备好了。新数据集推出后,性能提高了令人难以置信的 10-12% ,而无需进行其他更改。
具有复杂背景的数据集位于前面提到的 zip 文件synthetic_dataset_with_complex.zip中。提取此文件并用相同的名称替换/ data 目录中的文件夹,以获得具有复杂背景的更新合成数据集。
Average Mean Precision: mAP= 94.97% Increase in mAP score: 11.47%
具体来说,在几分钟的工作后,复杂背景系统的准确率提高了 11.47% ,达到 94.97% 。
结论
结果表明,使用合成数据和 TAO 工具包进行迭代是多么有效和快速。使用 Lexset’s Seahaven ,您可以在几分钟内生成新数据,并使用它解决引入复杂背景时遇到的准确性问题。
合成数据集的重要性现在已经很清楚了,因为针对真实螺钉数据的 90% 验证数据集上的微调模型的性能非常好。当实际或真实数据较少时,使用合成数据集进行初始特征学习。合成数据集可以节省大量时间和成本,同时产生优异的结果。
我相信这是计算机视觉发展的未来,数据生成与模型迭代同步进行。这将为用户提供更大的控制,并使您能够构建世界上最好的系统。
要创建自己的数据,请使用 Lexset 注册一个帐户。